Дэвид Райх - Кто мы и как сюда попали [Древняя ДНК и новая наука о человеческом прошлом]
![Дэвид Райх - Кто мы и как сюда попали [Древняя ДНК и новая наука о человеческом прошлом]](/books/1066346/devid-rajh-kto-my-i-kak-syuda-popali-drevnyaya-dnk-i.webp "Обложка книги")
- Название:Кто мы и как сюда попали [Древняя ДНК и новая наука о человеческом прошлом]
- Автор:
- Жанр:
- Издательство:Литагент Corpus
- Год:2020
- Город:М.
- ISBN:978-5-17-118990-7
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Дэвид Райх - Кто мы и как сюда попали [Древняя ДНК и новая наука о человеческом прошлом] краткое содержание
В своей книге Райх наглядно показывает, сколько скрытой информации о нашем далеком прошлом содержит человеческий геном и как радикально геномная революция меняет наши устоявшиеся представления о современных людях. Миграции наших предков, их отношения с конкурирующими видами, распространение культур – все это предстает в совершенно ином свете с учетом данных по ДНК ископаемых останков. Анализ научных открытий и исследований ведет к провокационной мысли: по всей видимости, различия между нынешними популяциями – биологическая реальность, однако с привычными стереотипами она не имеет ничего общего. Вопрос, кто же мы такие и откуда взялись, приходится ставить заново. Ответ еще в процессе формирования, но шаблоны уже трещат по швам.
Кто мы и как сюда попали [Древняя ДНК и новая наука о человеческом прошлом] - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Сингх и Тхангарадж очень обрадовались такой возможности и быстро уверили меня, что будет правильно расширить картину, включив данные по различным материковым группам индийцев. Они открыли нам доступ к собранной ими огромной коллекции ДНК. В морозильниках Центра в Хайдарабаде хранились образцы, представляющие фантастически разнообразное население Индии. Когда я последний раз проведывал эту коллекцию, там было более 18 тысяч индивидуальных образцов из трехсот с лишним группировок. Чтобы ее собрать, студенты со всей Индии объезжали сотни поселений и брали анализы крови у тех, чьи бабушки и дедушки были родом из этих же мест. Из этой коллекции мы выбрали 25 групп как можно более разнообразных и по географии, и по культуре, и по лингвистике. В нашей выборке присутствовали группы высокого и низкого социального статуса по индийской кастовой системе, а также ряд племен, существующих вне кастовой системы.
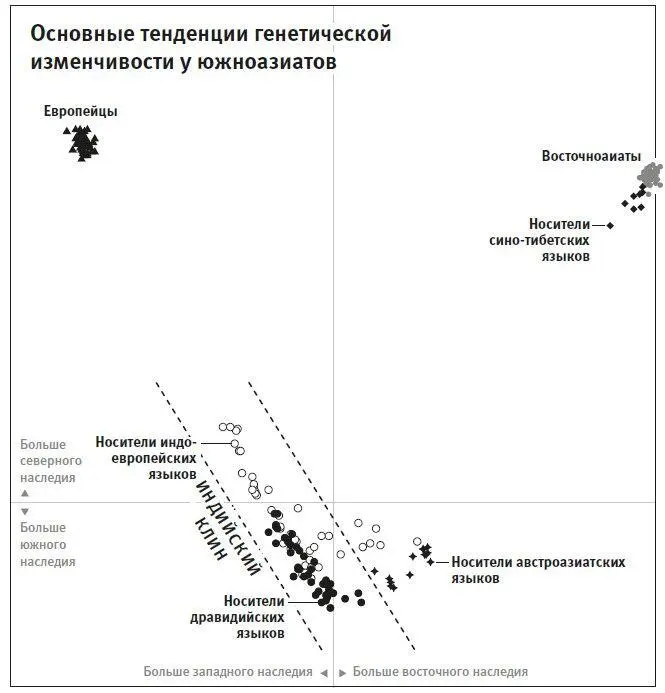
Рис. 17б.Анализ главных компонент показывает, что генетическая изменчивость большинства групп Юго-Восточной Азии образует постепенный ряд в координатах пропорции наследия, где на одном – северном – конце оказываются носители индоевропейских языков, на другом – южном – дравидийские носители.
Через несколько месяцев Тхангарадж приехал ко мне в лабораторию в Бостон и привез уникальные и драгоценнейшие образцы ДНК. Мы их решили исследовать методом микрочипирования однонуклеотидных замен (SNP). Эту технологию незадолго до того разработали в США, и в Индии она была еще недоступна. Поэтому Тхангарадж смог получить разрешение на вывоз образцов ДНК (по индийским государственным законам, если исследование биологических материалов можно провести внутри страны, то их вывоз запрещен).
SNP-микрочип содержит тысячи микропикселей, в каждом из которых сидит искусственно синтезированный кусочек ДНК из интересного для исследования места генома. Микрочип инкубируется с образцом ДНК исследуемого генома, и когда микрочип в конце промывают, то участки генома, соединенные с искусственными кусочками и потому связанные с субстратом прочнее, не вымываются. Оценивая относительную прочность связи исследуемой ДНК с искусственной “наживкой”, можно определить (а это делает камера, снимающая флуоресцентные метки на исходных образцах), какие генетические варианты содержатся в конкретном образце. С помощью SNP-микрочипирования мы исследовали много сотен тысяч позиций в геноме, по которым люди отличаются друг от друга, – в каждой из этих позиций у них стоят разные нуклеотиды. По этим вариабельным позициям можно определить, кто с кем теснее связан. Эта технология гораздо дешевле, чем полногеномное секвенирование, потому что можно направить все внимание только на значимые для исследования позиции, именно на те, по которым у людей есть различия и, следовательно, они дают максимум информации по истории популяций.
Чтобы получить общее представление о связях образцов друг с другом, мы применили статистический прием – метод главных компонент, описанный в предыдущем разделе об истории западноевразийской популяции. Метод главных компонент основан на поиске комбинаций однонуклеотидных замен в ДНК, наиболее четко отделяющих одну группу людей от другой. Выложив на координатную плоскость полученные значения по индийским группам, мы увидели, что все они расположились вдоль одной линии. На самом конце линии, далеко от других точек, оказались западные евразийцы – европейцы, центральноазиаты, индивиды с Ближнего Востока, которых мы включили в рассмотрение специально для сравнения. Мы назвали неевразийскую часть линии “индийский клин”: градиент изменчивости среди индийских групп, который на графике направлен, как стрела, к западным евразийцам 19 .
Данный градиент изменчивости, выявленный на плоскости главных компонент, может быть обусловлен несколькими, совершенно различными, историческими событиями. Однако, глядя на эту недвусмысленную “стрелу”, мы предположили, что многие нынешние индийские группы могут быть смешанными и в них в разных пропорциях присутствует западноевразийское наследие и наследие еще от какой-то очень непохожей популяции. На графике дальше всего от западных евразийцев расположились южные группы индийцев, говорящих на дравидийских языках, поэтому мы построили модель, согласно которой нынешние индийцы сформированы за счет смешения двух предковых популяций. А потом проверили ее на наших данных.
Для проверки мы придумали новые методы. Те самые методы, которые были использованы в 2010 году для выявления скрещивания между неандертальцами и современными людьми 20 , – но изначально они были разработаны для изучения истории индийских популяций.
Сначала мы протестировали гипотезу, где европейцы и индийцы произошли от общей предковой популяции, которая еще раньше отделилась от предков восточноазиатов (восточноазиатов представляли китайцы хань). Мы определили все буквы ДНК, по которым различаются геномы индийцев и европейцев, а потом оценили, насколько часто у китайцев встречаются европейский или индийский варианты. И получили ответ: у китайцев явно больше “индийских” букв ДНК, чем европейских. Теперь можно было отбросить идею, что европейцы и индийцы произошли от общей гомогенной предковой популяции, отделившейся от пракитайцев.
Альтернативная гипотеза, которую мы рассмотрели, предполагала, что китайцы и индийцы произошли от общей предковой популяции, отделившейся от ствола европейцев. Но и этот сценарий не подтвердился: европейские группы теснее связаны со всеми индийцами, чем со всеми китайцами.
Мы обнаружили, что частоты генетических мутаций, усредненные по всем группам индийцев, имеют промежуточное значение между европейцами и восточноазиатами. Единственное, что могло объяснить такую картину, – это смешение древних популяций, одна из которых имеет отношение к европейцам, центральноазиатам и людям Ближнего Востока, а другая связана отдаленным родством с восточноазиатами.
На начальных этапах мы называли первую популяцию “западными евразийцами”, подчеркивая широкий территориальный охват включенных популяций – и Европа, и Ближний Восток, и Центральная Азия, между которыми различий по частоте мутаций было не так уж много. Масштаб этих различий на порядок меньше, чем между европейцами и народами Восточной Азии. В свете этого было удивительно заметить, что одна из двух популяций, имевших отношение к генетическому наследию нынешних индийцев, сгруппировалась с западными евразийцами. Для нас это выглядело как восточный предел распространения западноевразийского наследия, где западные евразийцы смешивались с совсем непохожими на них людьми. Мы могли видеть, что та “непохожая” популяция теснее связана с сегодняшними восточноазиатами, например с китайцами, но все равно они должны были разделиться десятки тысяч лет назад. Эта группа походила на рано отделившуюся линию, вклад которой остался лишь в геномах нынешних южноазиатских популяций, и, в общем, больше нигде.
Читать дальшеИнтервал:
Закладка:









