Рэймонд Курцвейл - Эволюция разума

- Название:Эволюция разума
- Автор:
- Жанр:
- Издательство:Эксмо
- Год:2015
- Город:Москва
- ISBN:978-5-699-81143-4
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Рэймонд Курцвейл - Эволюция разума краткое содержание
Центральная идея работ знаменитого Рэя Курцвейла — искусственный интеллект, который со временем будет властвовать во всех сферах жизни людей. В своей новой книге «Эволюция разума» Курцвейл раскрывает бесконечный потенциал возможностей в сфере обратного проектирования человеческого мозга.
Эволюция разума - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Другое открытие заключается в том, что для усвоения основного массива знаний хорошо работают правила, сформулированные людьми. Для перевода коротких фрагментов текста такой подход часто обеспечивает более точный результат. Например, DARPA выше оценило переводы коротких текстов с помощью китайско-русского словаря, основанного на правилах, чем переводы Google Translate. Что же касается других элементов языка, к которым относятся миллионы редких фраз и заключенных в них понятий, тут точность переводов, основанных на правилах, непозволительно низкая. Если построить график точности понимания разговорной речи от количества данных, на которых обучалась система, системы, основанные на правилах, сначала показывают более высокую эффективность, но точность распознавания не поднимается выше 70 %. Напротив, статистические системы достигают точности 90 %, но для этого им нужно «изучить» очень большой массив данных.
Часто нам требуется обеспечить приемлемую эффективность при небольшом объеме обучающих данных, но предусмотреть повышение точности при дополнительных тренировках системы. Быстрое достижение средней эффективности позволяет перейти к автоматическому режиму сбора тренировочных данных при каждом использовании. Таким образом, в процессе применения системы происходит и ее обучение, что приводит к постепенному повышению точности результатов. Такое статистическое обучение должно быть полностью основано на принципе иерархии, что отражает структуру языка и принцип работы человеческого мозга.
Именно так работают Сири и Dragon Go: для определения наиболее общих и надежных явлений используются заранее сформулированные правила, а усвоение более редких элементов языка находится в руках конкретных пользователей. Когда создатели Cyc обнаружили, что достигли потолка эффективности при обучении системы на заранее сформулированных правилах, они также переключились на этот подход. Правила, определенные лингвистами, выполняют две важнейшие функции. Во-первых, они обеспечивают приемлемую начальную точность, так что систему можно допускать к широкому использованию, где она будет улучшаться автоматически. Во-вторых, они служат надежной основой для низших уровней понятий, от которых начинается автоматический подъем на более высокие иерархические уровни.
Как отмечалось выше, Ватсон является удивительным примером реализации комбинированного подхода, в котором сочетается настройка системы по предварительно сформулированным правилам и ее иерархическое статистическое обучение. Для создания системы, способной играть в «Джеопарди!» на разговорном языке, компания IBM объединила несколько лучших программ. С 14 по 16 февраля 2011 г. Ватсон соревновался с двумя ведущими игроками: Брэдом Раттером, выигравшим в эту викторину больше денег, чем кто-либо другой, и Кеном Дженнингсом, который удерживал звание чемпиона викторины рекордное время — 75 дней.
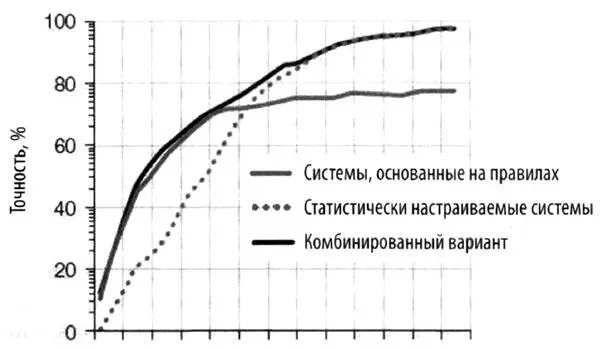
Точность систем распознавания разговорной речи как функция объема тренировочных данных. Наилучшие результаты получаются при сочетании заранее сформулированных правил для освоения «основного» языка и самостоятельной тренировки для освоения «деталей».
В моей первой книге «Эра разумных машин», написанной в середине 1980-х гг., я предсказывал, что компьютер станет чемпионом мира по шахматам примерно к 1998 г. Еще я предсказал, что если это произойдет, то мы либо станем хуже думать о человеческом разуме, либо лучше думать о разуме машин, либо потеряем интерес к шахматам. И если принять во внимание историю, скорее всего, должно было произойти последнее. Так и вышло. В 1997 г., когда суперкомпьютер IBM Deep Blue обыграл чемпиона мира по шахматам Гарри Каспарова, мы немедленно стали утверждать, что именно так и должно было случиться, поскольку компьютеры — логические машины, а шахматы, в конце концов, игра на логику. Победу компьютера не сочли ни важным, ни удивительным событием. Многие критики принялись утверждать, что компьютер никогда бы не смог одолеть человеческую речь — со всеми метафорами, сравнениями, каламбурами, двусмысленностями и юмором.
Вот почему Ватсон так много значит: «Джеопарди!» — именно такая сложная и напряженная игра на знание языка. Типичные вопросы викторины содержат непростые обороты человеческой речи. Однако для большинства зрителей, возможно, не очевидно, что Ватсон не только понимает вопросы, заданные в неожиданной и запутанной форме, но большая часть его знаний не была сформирована людьми. Он обзавелся этими знаниями самостоятельно, прочитав 200 млн страниц документов на человеческом языке, включая «Википедию» и другие энциклопедии, что составляет 4 трлн байт информации. Как вы понимаете, «Википедия» написана не на ЛИСП или CycL, а «нормальными» предложениями со всеми присущими языку двусмысленностями и путаницами. При ответе на вопрос викторины Ватсон должен проверить все 4 млрд знаков реферативного материала (конечно, «Джеопарди!» — не вопросы, а загадки, но это техническая сторона дела — по форме это настоящие вопросы). Если Ватсон способен понять вопрос и ответить на него на основании 200 млн страниц текста — и всего за три секунды! — ничто не может помешать подобным машинам прочесть миллиарды имеющихся в Интернете документов. Именно это сейчас и происходит.
Когда в период с 1970-х по 1990-е гг. мы занимались разработкой систем для распознавания знаков и речи и первых систем, понимающих разговорную речь, мы включали в свои программы «эксперта-менеджера». Мы создавали разные системы для решения одной и той же задачи, но в каждом случае использовали несколько иной подход. Некоторые из различий были незначительными, например вариации параметров, контролирующих математику алгоритма обучения. Но некоторые были фундаментальными, например использование предварительно сформулированных правил вместо иерархических статистически обучающихся систем. Эксперт-менеджер представлял собой компьютерную программу, призванную изучить сильные и слабые стороны различных систем путем анализа их эффективности в реальных ситуациях. Оценка производилась по принципу ортогональности, то есть одна система считалась скорее сильной, другая — скорее слабой. Выяснилось, что общая эффективность комбинированных систем с обученным экспертом-менеджером была намного выше, чем у отдельных систем.
Ватсон действует по такому же принципу. Используя архитектуру UIMA (Unstructured Information Management Architecture), Ватсон распоряжается буквально сотнями различных систем — многие отдельные языковые компоненты Ватсона аналогичны тем, что применяются в широко используемых системах распознавания разговорного языка, — и все они либо пытаются напрямую дать ответ на вопрос викторины, либо как минимум прояснить вопрос. UIMA выступает в роли эксперта-менеджера, разумно сочетающего результаты отдельных систем. UIMA превзошла более ранние системы (включая разработанные нами еще до создания компании Nuance) в том, что составляющие ее системы могут участвовать в получении результата, даже если не пришли к финальному ответу. Достаточно, чтобы подсистема помогла найти путь к ответу. Кроме того, UIMA может рассчитать степень собственного доверия к полученному ответу. Человеческий мозг тоже это делает: обычно вы совершенно уверены в ответе, если у вас спросят, как зовут вашу мать, но гораздо менее уверены, если речь идет о человеке, которого вы видели один раз год назад.
Читать дальшеИнтервал:
Закладка: