Игнаси Белда - Том 33. Разум, машины и математика. Искусственный интеллект и его задачи

- Название:Том 33. Разум, машины и математика. Искусственный интеллект и его задачи
- Автор:
- Жанр:
- Издательство:Де Агостини
- Год:2014
- ISBN:978-5-9774-0728-1
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Игнаси Белда - Том 33. Разум, машины и математика. Искусственный интеллект и его задачи краткое содержание
Уже несколько десятилетий тема искусственного интеллекта занимает умы математиков и людей, далеких от науки. Ждать ли нам в ближайшем будущем появления говорящих машин и автономных разумных систем, или робот еще не скоро сравнится с человеком? Что такое искусственный интеллект и возможно ли в лабораторных условиях создать живой разумный организм? Ответы на эти и многие другие вопросы читатель узнает из данной книги. Добро пожаловать в удивительный мир искусственного интеллекта, где математика, вычисления и философия идут рука об руку.
Том 33. Разум, машины и математика. Искусственный интеллект и его задачи - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
Несмотря на все преимущества и относительную простоту метода главных компонент (сегодня этот метод входит в стандартную поставку всех пакетов статистических программ), по мере увеличения числа измерений в модели сложность расчетов возрастает, и вычисления могут оказаться непосильными. В подобных случаях используются два других метода отбора характеристик: жадный прямой отбор ( greedy forward selection ) и жадное обратное исключение ( greedy backward elimination ). Оба этих метода обладают серьезными недостатками: они требуют выполнения огромного объема расчетов, при этом вероятность выбора наиболее подходящих характеристик невысока. Однако основная идея этих методов и ее реализация просты, а объем необходимых вычислений для большого числа измерений все же не так высок, как при использовании метода главных компонент. Это объясняет, почему жадный прямой отбор и жадное обратное исключение стали так популярны среди специалистов по интеллектуальному анализу данных.
* * *
ЖАДНЫЕ АЛГОРИТМЫ
Жадные алгоритмы — разновидность алгоритмов, в которых для определения следующего действия (при решении задач планирования, поиска или обучения) всегда выбирается вариант, ведущий к максимальному увеличению некоего градиента в краткосрочной перспективе.
Достоинство жадных алгоритмов заключается в том, что они способны очень быстро найти максимальное значение определенных математических функций. Для сложных функций, имеющих несколько максимумов, жадные алгоритмы, напротив, обычно останавливаются на одном из локальных максимумов, так как не могут оценить задачу в целом. В итоге жадные алгоритмы оказываются не вполне эффективны, так как результатом их работы часто является субоптимум функции.
* * *
Как следует из названия, один из этих методов является прямым, а другой — обратным, однако оба используют один принцип. Представьте, что мы хотим отобрать характеристики, точнее всего описывающие тенденции голосования на парламентских выборах. Имеем пять известных характеристик выборки: покупательная способность, родной город, образование, пол и рост избирателя. Будем использовать для анализа тенденций нейронную сеть. Применив жадный прямой отбор, выберем первую переменную в задаче и смоделируем данные с помощью нейронной сети, используя только эту переменную. После того как модель построена, оценим точность прогноза и сохраним полученную информацию. Повторим аналогичные действия для всех остальных переменных по отдельности. По завершении анализа выберем переменную, для которой были получены лучшие результаты, и повторим моделирование с последующей оценкой модели, но уже для двух переменных. Предположим, что лучшие результаты были получены для переменной «образование». Проверим все возможные сочетания переменных, в которых первой переменной будет «образование». Получим модели «образование и родной город», «образование и пол», «образование и рост». И вновь, проанализировав четыре сочетания, выберем лучшее из них, к примеру «образование и покупательная способность», после чего повторим описанные выше действия уже для трех переменных, две из которых будут фиксированы. Этот процесс будет повторяться до тех пор, пока с добавлением очередной переменной точность новой модели относительно предыдущей, содержащей на одну переменную меньше, не перестанет возрастать.
Жадное обратное исключение проводится прямо противоположным образом: в качестве исходной выбирается модель, содержащая все переменные, затем из нее последовательно исключаются переменные так, чтобы качество модели не ухудшалось.
Как можно догадаться, этот метод является не слишком интеллектуальным: он не гарантирует, что будет найдено наилучшее сочетание переменных, а также предполагает значительный объем вычислений, поскольку на каждом этапе необходимо выполнять моделирование заново.
Ввиду важных недостатков существующих методов отбора характеристик на специализированных конференциях постоянно предлагаются новые методы. Они обычно описываются тем же принципом, что и метод главных компонент, то есть заключаются в поиске новых переменных, которые замещают исходные и повышают плотность информации. Подобные переменные называются латентными. Они используются во множестве дисциплин, однако наибольшее распространение получили в общественных науках. Такие характеристики, как качество жизни в обществе, доверие участников рынка или пространственное мышление человека, — латентные переменные, которые нельзя измерить напрямую. Они измеряются и выводятся по результатам совокупного анализа других, более осязаемых характеристик. Латентные переменные обладают еще одним преимуществом: они сводят несколько характеристик в одну, тем самым уменьшая размерность модели и упрощая работу с ней.
Визуализация данных — дисциплина, изучающая графическое представление данных, как правило многомерных. Эта дисциплина стала популярной вскоре после образования современных государств, способных систематически собирать данные о развитии экономики, общества и производственных систем. В действительности визуализация данных и анализ данных — смежные дисциплины, так как многие средства, методы и понятия, используемые для упрощения визуализации, возникли в рамках анализа данных, и наоборот.
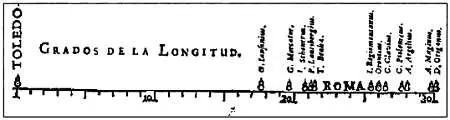
Возможно, автором первой известной визуализации статистических данных был Михаэль ван Лангрен, который в 1644 году изобразил на диаграмме 12 оценок расстояния между Толедо и Римом, предложенных 12 разными учеными. Слово «ROMA» («РИМ») указывает оценку самого Лангрена, а маленькая размытая стрелка, изображенная под линией примерно в ее центре, — корректное расстояние, вычисленное современными методами.
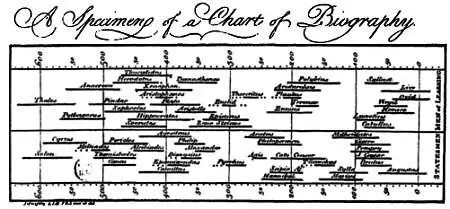
Еще в XVIII веке Джозеф Пристли составил диаграмму, где изобразил, в какое время жили некоторые выдающиеся деятели античности.
В том же столетии, благодаря трудам Иммануила Канта, который утверждал, что именно представление делает объект возможным, а не наоборот, стало понятно, что нельзя вести споры о знаниях или реальности, не учитывая, что эти самые знания и реальность создает человеческий разум. Так представление и визуализация данных заслуженно заняли важнейшее место в науке.
Позднее, во время Промышленной революции, начали появляться более сложные методы представления данных. В частности, Уильям Плейфэр создал методы, позволяющие представить изменение объемов производства, связав их с колебаниями цен на пшеницу и с величиной заработной платы при разных правителях на протяжении более 250 лет.
Читать дальшеИнтервал:
Закладка:









