Игнаси Белда - Том 33. Разум, машины и математика. Искусственный интеллект и его задачи

- Название:Том 33. Разум, машины и математика. Искусственный интеллект и его задачи
- Автор:
- Жанр:
- Издательство:Де Агостини
- Год:2014
- ISBN:978-5-9774-0728-1
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Игнаси Белда - Том 33. Разум, машины и математика. Искусственный интеллект и его задачи краткое содержание
Уже несколько десятилетий тема искусственного интеллекта занимает умы математиков и людей, далеких от науки. Ждать ли нам в ближайшем будущем появления говорящих машин и автономных разумных систем, или робот еще не скоро сравнится с человеком? Что такое искусственный интеллект и возможно ли в лабораторных условиях создать живой разумный организм? Ответы на эти и многие другие вопросы читатель узнает из данной книги. Добро пожаловать в удивительный мир искусственного интеллекта, где математика, вычисления и философия идут рука об руку.
Том 33. Разум, машины и математика. Искусственный интеллект и его задачи - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
Благодаря вычислительной технике специалисты в сфере визуализации данных начали понимать, каким должно быть качественное представление данных для их быстрой интерпретации. Один из важнейших моментов, которые следует принимать во внимание (помимо самих данных, модели представления и графического движка, используемого для визуализации), — ограниченные способности восприятия самого аналитика, конечного потребителя данных. В мозгу аналитика происходят определенные когнитивные процессы, в ходе которых выстраивается ментальная модель данных. Однако эти когнитивные процессы страдают из-за ограниченности нашего восприятия: так. большинство из нас неспособны представить себе больше четырех или пять измерений. Чтобы упростить построение моделей, необходимо учитывать все эти ограничения. Качественная визуализация данных должна представлять информацию в иерархическом виде с различными уровнями подробностей. Также визуализация должна быть непротиворечивой и не содержать искажений. В ней следует свести к минимуму влияние данных, которые не содержат полезной информации или могут вести к ошибочным выводам. Рекомендуется дополнять визуализацию иными статистическими данными, указывающими статистическую значимость различной информации.
Для достижения всех этих целей используются стратегии, подобные рассмотренным в главе, посвященной анализу данных. Первая из них заключается в снижении размерности с помощью уже описанных методов, в частности, путем ввода латентных переменных. Вторая стратегия состоит в снижении числа выборок модели путем их разделения на значащие группы. Этот процесс называется кластеризацией (английское слово «кластер» можно перевести как «гроздь», «пучок»).
Кластерный анализ состоит в разделении множества результатов наблюдений на подмножества — кластеры, так, чтобы все результаты, принадлежащие к одному кластеру, обладали некими общими свойствами, необязательно очевидными. Кластеризация данных значительно упрощает их графическое представление, а также позволяет специалистам по визуализации понять изображаемые данные. Существует множество алгоритмов кластеризации, и каждый из них обладает особыми математическими свойствами, которые делают его пригодным для тех или иных типов данных.
В главе об анализе данных нельзя обойти стороной тему распознавания образов как одну из основных целей анализа. Для распознавания образов можно использовать все описанные выше средства: нейронные сети, метод опорных векторов, метод главных компонент и другие. Как вы видите, распознавание образов имеет непосредственное отношение к машинному обучению.
Цель системы-классификатора, подобно нейронной сети или методу опорных векторов, — предсказать, к какому классу относится данная выборка, то есть классифицировать ее. Поэтому системе-классификатору в целях обучения следует передать множество выборок известных классов. После обучения системы ей можно будет передавать для классификации новые выборки. Как и в описанных выше методах, начальное множество выборок известных классов обычно делится на два подмножества — обучающее и тестовое. Тестовое множество помогает проверить, не переобучена ли система.
При создании классификаторов применяются два подхода: мичиганский, предложенный исследователями из Мичиганского университета, и питтсбургский, появившийся, соответственно, в университете города Питтсбурга. В мичиганском подходе описывается эволюционный алгоритм, в котором в роли эволюционирующих особей выступают правила, каждое правило содержит множество условий и цель.
Класс выборки укажет правило, с набором условий которого совпадает выборка.
В питтсбургском подходе, напротив, каждая особь представляет собой множество правил, а приспособленность особи оценивается по средней ошибке для каждого из этих правил. Оба подхода, которые в немалой степени дополняют друг друга, имеют свои преимущества и недостатки. В последние 30 лет исследователи предлагают различные улучшения обоих подходов, чтобы компенсировать их неэффективность.
Еще одна важная область применения искусственного интеллекта в бизнесе — это работа с хранилищами данных, которые широко используются предприятиями с большой клиентской базой и, следовательно, с большой базой выборок. Путем анализа базы выборок можно определить тенденции, закономерности и шаблоны поведения. Хранилище данных — это место, куда стекаются данные со всего предприятия, будь то данные о продажах, производстве, результатах маркетинговых кампаний, внешних источниках финансирования и так далее. Сегодня хранилища данных используются в таких областях, как банковская сфера, здравоохранение, розничная торговля, нефтепереработка, государственная служба и другие.
Создание и структурирование хранилища данных — сложная задача, на решение которой инженерам потребуется несколько месяцев и даже лет. После того как хранилище данных выстроено, структурировано и обеспечена его корректность, содержащиеся в нем данные изучаются и анализируются с помощью так называемых OLAP-кубов, которые в действительности представляют собой гиперкубы. OLAP-куб (от англ. OnLine Analytical Processing — «аналитическая обработка в реальном времени») — это многомерная структура данных, позволяющая очень быстро выполнять перекрестные запросы к данным различной природы. О LAP-куб можно считать многомерным вариантом электронной таблицы. К примеру, электронная таблица, в которой представлены данные о продажах молочных продуктов нашей компании в разных странах в прошлом году (в тысячах штук), может выглядеть так.
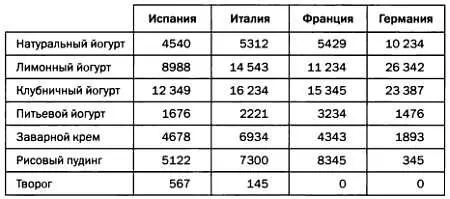
Если мы хотим получить данные о продажах в отдельные месяцы, нужно добавить к таблице третье измерение, в котором для каждого региона и типа продукции представленные данные будут разбиты на 12 месяцев.
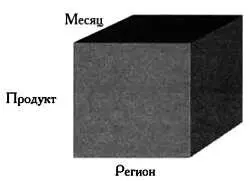
Сформировав куб, мы сможем выполнять различные виды сложного анализа данных с учетом предварительно выстроенной структуры куба. Заметим, что основные затраты вычислительных ресурсов при использовании хранилища данных связаны не с самим анализом данных, а с построением множества гиперкубов. Гиперкубы могут отражать данные организации с учетом множества возможных сочетаний. Поэтому OLAP-кубы, как правило, строятся по ночам, а используются и анализируются на следующий день.
Читать дальшеИнтервал:
Закладка:









