Тревор Кокс - Зачем мы говорим. История речи от неандертальцев до искусственного интеллекта

- Название:Зачем мы говорим. История речи от неандертальцев до искусственного интеллекта
- Автор:
- Жанр:
- Издательство:КоЛибри, Азбука-Аттикус
- Год:2020
- Город:М.
- ISBN:978-5-389-17812-0
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Тревор Кокс - Зачем мы говорим. История речи от неандертальцев до искусственного интеллекта краткое содержание
Зачем мы говорим. История речи от неандертальцев до искусственного интеллекта - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
В записи сиплый, свистящий голос поезда был создан с использованием соновокса. К горлу крепился репродуктор, и актер беззвучно артикулировал слова. Свистковые тоны, проигрываемые репродуктором, заставляли горло вибрировать и проходили в голосовой тракт. Эти вибрации заменяли нормальное гудение голосовых связок {277} 277 Актеру приходится закрывать голосовую щель, иначе значительная доля звука пропадет в легких.
. Подобная техника может помочь человеку, который утратил голосовые связки из-за болезни. Искусственная гортань закрепляется на горле и действует подобно репродуктору соновокс. В этом случае устройство производит не свист, а гудение, ведь здесь идея состоит не в создании мультяшного голоса, а в замене речи.
В XX веке были разработаны еще более сложные способы создания вокальных карикатур и «механических» голосов. Самым замечательным был вокодер, устройство, первоначально разработанное, чтобы кодировать речь для телефонных линий. Во многом вокодер имитировал работу соновокса: замещал создаваемую голосовыми связками звуковую волну нотами синтезатора. Группа Kraftwerk первой использовала вокодер в альбоме 1974 года Autobahn. Главная песня начинается с того, что машина заводится, трогается с места и гудит. Затем вокодер создает медленную электронную распевку слова Autobahn {278} 278 Обязательно послушайте альбомную версию. https://youtu.be/x-G28iyPtz0 .
. Механический голос постепенно нарастает, начиная с тоники, а затем добавляются еще ноты, чтобы получился аккорд. Такое электронное обесчеловечивание голоса точно соответствовало отстраненной эстетике группы (мы вернемся к вокодеру в следующей главе).
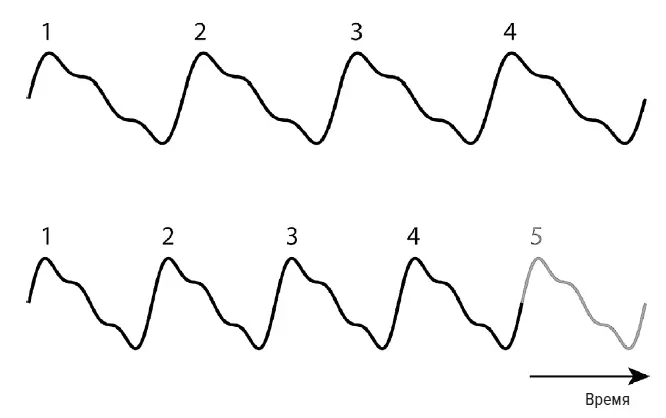
Когда компьютеры появились в каждой звукозаписывающей студии, обработка музыки стала цифровой, что дало еще большую свободу для манипулирования голосом. Возможно, самым известным и эффективным преобразованием голоса был хит Шер Believe, который принес ей премию «Грэмми» в 1999 году. Пение Шер было обработано программой Auto-Tune с максимальным использованием звуковых эффектов, чтобы придать ее голосу модуляции. Auto-Tune постоянно оценивает частоту пения, используя математическую операцию «автокорреляция». Если программа обнаруживает частоту, которая не подходит к одной из нот музыкальной гаммы, аудио обрабатывается так, чтобы гармония улучшилась. Скажем, нота, изображенная на верхней схеме рисунка на с. 215, бемольная, тогда четыре цикла звука сжимаются и в конце добавляется еще один цикл. Это означает, что нота изменяется быстрее: другими словами, частота увеличилась, чтобы скорректировать гармонию {279} 279 Hildebrand H. A., Auburn Audio Technologies Inc. Pitch detection and intonation correction apparatus and method. 1999. US Patent 5,973,252.
. Если корректировка производится осторожно и постепенно, будет трудно обнаружить использование Auto-Tune, часто его просто не слышно. Но если программа настроена так, что производит коррекцию моментально, получается модулированный звук, такой как в Believe Шер. На самом деле мы слышим, как программа прыгает между разными нотами, так как тон корректируется слишком часто. Эта запись — замечательный пример того, как артисты используют технологии и злоупотребляют ими для создания неожиданных творческих эффектов.
Популярная музыка прибегает к созданию коротких, легко запоминающихся мелодий, которые делают песню притягательной. Этот прием известен как «музыкальный хук». Believe Шер — пример того, что это может относиться не только к мелодии или словам: искаженный голос сам по себе становится эффектным хуком. С учетом того, как акустические потоки формируются в сознании, качание частоты помогает отличить голос от музыкального сопровождения и выделить его.
Повышение тона в Auto-Tune
Злоупотребление Auto-Tune приводило и к удивительным мистификациям. Одна из самых известных — это ремейк речи Ника Клегга, в которой он приносит извинения за повышение платы за обучение. Эта запись даже попала в топ-40. Звуки, производимые с вибрацией голосовых связок, например гласные, по своей природе обладают тоном {280} 280 Есть основанная на этом эффекте замечательная акустическая иллюзия, которую Дайана Дойч назвала «песня речи». См.: Speech to Song Illusion // DianaDeutsch. https://deutsch.ucsd.edu/psychology/pages.php?i=212 .
. Если использовать Auto-Tune, можно повысить или понизить частоты разговорной речи так, чтобы она стала похожей на мелодию. Программа не сможет обработать звуки речи, которые обладают нечеткими частотами, например [с], поэтому после наложения Auto-Tune мистификация Клегга переключается с механического голоса на пение и обратно.
Голос с едва различимым механическим оттенком — это обычное явление в современном поп-вокале. Такие записи лучше продаются, хотя некоторым не нравится подобное звучание. Музыкальный критик Telegraph Нил Маккормик так прокомментировал использование Auto-Tune: «Преимущественно в музыке эта штука используется плохо, из рук вон плохо». Он вспоминает свой разговор с Леди Гагой: «Когда я впервые брал у нее интервью, она то и дело начинала петь, а я ей вроде: ух ты, петь-то умеешь по-настоящему; но у нее ведь была эта пластинка, на которой она звучала как робот, играющий в Just Dance». Маккормик спросил Леди Гагу, зачем она использует обработанный в Auto-Tune голос, ведь она фантастическая певица. «И она, по сути, ответила, что этого хочет молодежь».
Но так ли уж сильно электронные ухищрения для манипуляций с современным поп-голосом отличаются от техник пения, которые изобретали оперные певцы для создания звука, достаточного, чтобы заполнить весь зрительный зал? Как мы увидели на примере «Барселоны», оперные певцы жертвуют произношением, концентрируя внимание на мелодической линии. Таким образом, обучение студентов пению в классическом стиле воспитывает певцов, у которых почти нет индивидуальности. Так и голос современного певца, прошедший цифровую обработку, может звучать не как голос человека, а как музыкальный инструмент. Оперные певцы используют очень широкое вибрато, модуляцию частоты, которая помогает им выделяться на фоне оркестра. Подобно этому, механическое качание частоты, которые звукооператор добавляет к голосу поп-певца, помогает выделить его на фоне музыкального сопровождения. При качественном исполнении музыкальная обработка — это просто расширение того, что люди делали на протяжении веков {281} 281 Еще один пример — «перемещающиеся» голоса в песне A Day in the Life (The Beatles), причем этот эффект наиболее очевиден в наушниках. Когда Леннон начинает петь I read the news today, его голос доносится справа. К концу первого стиха, который заканчивается словами I’d love to turn you on, он уже переместился налево. И это отголосок вековой традиции антифонального пения, при котором два разных хора поют перекличкой для создания эффекта пространственного разделения музыки.
.
Интервал:
Закладка:









