Чарльз Петцольд - Код. Тайный язык информатики

- Название:Код. Тайный язык информатики
- Автор:
- Жанр:
- Издательство:Манн, Иванов и Фербер
- Год:2019
- Город:Москва
- ISBN:978-5-00117-545-2
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Чарльз Петцольд - Код. Тайный язык информатики краткое содержание
Код. Тайный язык информатики - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Рассмотрим следующую строку шестнадцатеричных значений.
41 09 42 09 43 09
Символ 09 — это код горизонтальной табуляции, или табулятор. Если представить, что все горизонтальные позиции символа на странице принтера нумеруются начиная с 0, то код табуляции дает команду напечатать следующий символ на следующей горизонтальной позиции, номер которой кратен восьми, например так.
Это удобный способ для расположения текста столбцами.
Даже сегодня многие компьютерные принтеры реагируют на код перехода к новой странице (12h), извлекая текущую страницу и начиная печатать на новой.
Код для возврата на один символ назад (backspace) может использоваться для печати составных символов на некоторых старых принтерах. Предположим, вам нужно, чтобы телетайпный аппарат отобразил строчную букву e с обратным апострофом: è . Эту задачу можно решить с помощью шестнадцатеричных кодов 65 08 60.
Сегодня наиболее важными являются управляющие коды для возврата каретки и перевода строки, которые имеют то же значение, что и аналогичные коды Бодо. В ответ на код возврата каретки печатающая головка принтера перемещается к левому краю страницы, а в ответ на код перевода строки — на одну строку вниз. Обычно для перехода на новую строку требуются оба кода. Код возврата каретки может использоваться сам по себе для печати поверх существующей строки, а код перевода строки — для того, чтобы перейти к следующей, при этом не перемещаясь к левому краю страницы.
Несмотря на то что кодировка ASCII — доминирующий стандарт в компьютерном мире, она не используется во многих крупных компьютерных системах IBM. Для мейнфреймов System/360 компания разработала собственный 8-битный код EBCDIC (Extended BCD Interchange Code — расширенный двоично-десятичный код обмена информацией) — расширенный вариант более раннего 6-битного кода BCDIC, полученного из кодов, используемых на перфокартах IBM. Эти перфокарты, позволяющие хранить по 80 текстовых символов, были созданы IBM в 1928 году и использовались на протяжении более 50 лет.

Рассматривая взаимосвязь между перфокартами и соответствующими им 8-битными кодами символов EBCDIC, имейте в виду, что эти коды разрабатывались на протяжении многих десятилетий под влиянием различных технологий. По этой причине не стоит ожидать от них излишней логичности или согласованности.
На перфокарте символ кодируется комбинацией из одного или нескольких прямоугольных отверстий, пробитых в одном столбце. Сам символ часто печатается в верхней части карты. Нижние десять строк пронумерованы от 0 до 9. Ненумерованная строка над нулевой строкой считается одиннадцатой, а верхняя — двенадцатой; десятая строка отсутствует.
Вот еще несколько терминов из области применения перфокарт IBM: строки с нулевой по девятую называются цифровыми строками , или цифровой пробивкой . Одиннадцатая и двенадцатая строки — зонные строки , или зонная пробивка . Иногда нулевая и девятая строки считались не цифровыми, а зонными, что вызывало путаницу.
Восьмибитный код символа EBCDIC состоит из старшей и младшей тетрад (четыре бита). Младшая тетрада — код BCD, соответствующий цифровой пробивке символа; старшая тетрада — код, который произвольно можно поставить в соответствие зонной пробивке символа. Из главы 19 вы помните, что BCD означает двоично-десятичный код — 4-битный код для цифр от 0 до 9.
Для цифр от 0 до 9 не существует никакой зонной пробивки. Отсутствие пробивки соответствует старшей тетраде 1111. Младшая тетрада — код BCD цифровой пробивки. В следующей таблице приведены коды EBCDIC для цифр от 0 до 9.
Шестнадцатеричный код
Символ EBCDIC
F0
0
F1
1
F2
2
F3
3
F4
4
F5
5
F6
6
F7
7
F8
8
F9
9
Для прописных букв тетрада 1100 соответствует зонной пробивке только двенадцатой строки, тетрада 1101 — зонной пробивке только одиннадцатой строки, тетрада 1110 — зонной пробивке только нулевой строки. Приведем коды EBCDIC для прописных букв.
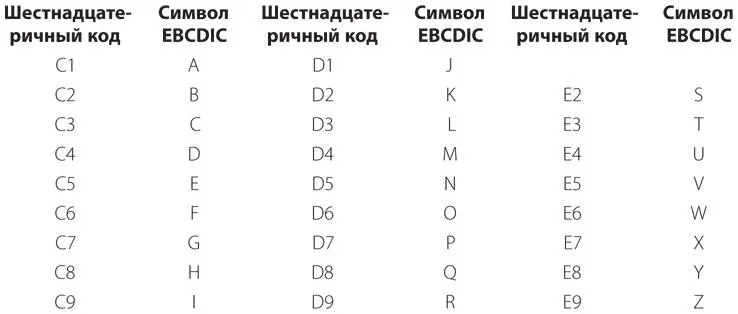
Обратите внимание на зазоры в нумерации этих кодов. Если вы используете текст EBCDIC при написании программ, эти зазоры могут мешать.
Строчные буквы соответствуют той же цифровой пробивке, что и прописные, но другой зонной пробивке. Для строчных букв от a до i пробиваются двенадцатая и нулевая строки, что соответствует коду 1000, для букв от j до r — двенадцатая и одиннадцатая строки, что соответствует коду 1001, для букв от s до z — одиннадцатая и нулевая строки, что соответствует коду 1010. Коды EBCDIC для строчных букв следующие.
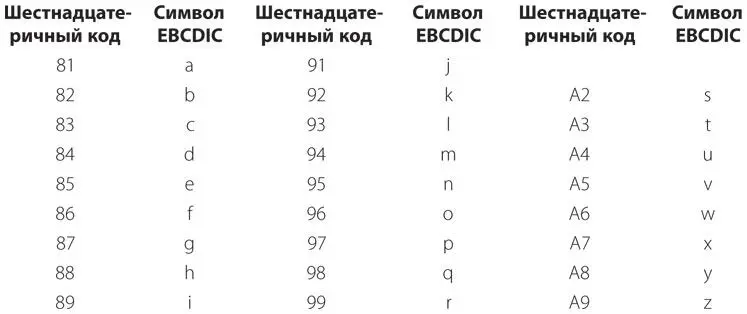
Разумеется, существуют и другие коды EBCDIC — для знаков препинания и управляющих символов, однако мы едва ли нуждаемся в проведении полномасштабного исследования этой системы.
На первый взгляд может показаться, что одного столбца перфокарты IBM достаточно для кодирования 12 бит информации. Каждое отверстие соответствует одному биту, не так ли? По идее, для кодирования символа ASCII должно быть достаточно семи из 12 позиций в каждом столбце. Однако на практике это не очень хорошо работает, поскольку при этом пробивается слишком много отверстий, из-за чего карта становится хрупкой.
Многие из 8-битных кодов EBCDIC не определены. Это говорит о том, что использование 7-битной кодировки ASCII имеет больше смысла. Во времена разработки системы ASCII память была дорогостоящей. Некоторые люди полагали, что кодировка ASCII должна быть 6-битной и предусматривать символ переключения между строчными и прописными буквами для экономии.
Как только эта идея была отвергнута, другие стали полагать, что кодировка ASCII должна быть 8-битной, поскольку даже в то время считалось, что в компьютерах будет применяться скорее 8-битная архитектура, чем 7-битная. Конечно, современным стандартом являются 8-битные байты. Несмотря на то что технически ASCII — это 7-битная кодировка, почти всегда ее коды хранятся как 8-битные значения.
Эквивалентность байтов и символов, безусловно, удобна, поскольку мы можем приблизительно представить, какой объем компьютерной памяти занимает конкретный текстовый документ, просто подсчитав количество символов. Некоторым людям гораздо легче понять, что такое килобайт и мегабайт памяти, когда этот объем ставится в соответствие объему текста.
Читать дальшеИнтервал:
Закладка: