Саймон Сингх - Книга шифров .Тайная история шифров и их расшифровки

- Название:Книга шифров .Тайная история шифров и их расшифровки
- Автор:
- Жанр:
- Издательство:Астрель
- Год:2007
- Город:Москва
- ISBN:нет данных
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Саймон Сингх - Книга шифров .Тайная история шифров и их расшифровки краткое содержание
Саймон Сингх получил степень кандидата наук по физике в Кембриджском университете. Во время работы продюсером на Би-би-си снял удостоенный награды Британской академии кино и телевидения документальный фильм «Великая теорема Ферма» и написал бестселлер под тем же названием.
Шифры используются с тех пор, как люди научились писать. В «Книге шифров» Саймон Сингх посредством волнующих историй о шпионаже, интригах, интеллектуальном блеске и военной хитрости показывает захватывающую историю криптографии.
<<Изложение Сингха сочетает в себе увлекательность и наиболее содержательный анализ из всех, которые я когда-нибудь видел. Как и всегда, он блещет способностью объяснять>>.
<<Гардиан>>
Книга шифров .Тайная история шифров и их расшифровки - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Предположим, что длина ключевого слова действительно составляет 5 букв; тогда следующий этап будет заключаться в том, чтобы найти эти буквы. Пока обозначим ключевое слово в виде L 1-L 2-L 3-L 4-L 5, где L 1 будет первой буквой ключевого слова, L 2— второй, и так далее. Тогда процесс шифрования начнется с зашифровывания первой буквы открытого текста в соответствии с первой буквой ключевого слова Буква определяет строку квадрата Виженера и, тем самым, задает одноалфавитный шифр замены для первой буквы открытого текста. Однако когда наступает время для зашифровывания второй буквы открытого текста, криптограф должен использовать L 2, чтобы определить другую строку квадрата Виженера, задавая тем самым уже иной одноалфавитный шифр замены. Третья буква открытого текста будет зашифровываться в соответствии с L 3, четвертая — в соответствии с L 4, а пятая — в соответствии с L 5. Каждая буква ключевого слова задает для шифрования свой отличающийся шифралфавит. Но затем шестая буква открытого текста будет опять зашифровываться в соответствии с L 1, седьмая буква — в соответствии с L 2, и далее цикл повторяется. Другими словами, в нашем случае многоалфавитный шифр состоит из пяти одноалфавитных шифров, причем каждый одноалфавитный шифр отвечает за шифрование 1/ 5части всего сообщения. Но самое главное состоит в том, что нам уже известно, как проводить криптоанализ одноалфавитных шифров.

Таблица 8 Повторяющиеся последовательности и интервалы между ними в шифртексте.
Поступим следующим образом. Мы знаем, что одна из строк квадрата Виженера, определяемая буквой задает шифралфавит, которым зашифрованы 1-я, 6-я, 11-я, 16-я… буквы сообщения. Поэтому если возьмем 1-ю, 6-ю, 11-ю, 16-ю… буквы шифртекста, то мы сможем применить добрый, старый частотный анализ для определения данного шифралфавита. На рисунке 14 показано частотное распределение букв, которые стоят на 1-м, 6-м, 11-м, 16-м… местах шифртекста; это буквы W, I, R, Е… Здесь следует напомнить, что каждый шифралфавит в квадрате Виженера — это просто обычный алфавит, сдвинутый на 1… 26 позиций. Поэтому частотное распределение на рисунке 14 должно иметь те же особенности, что и частотное распределение стандартного алфавита, за исключением того, что оно будет сдвинуто на некоторое расстояние. Сравнивая распределение L 1со стандартным распределением, можно определить величину сдвига. На рисунке 15 показано стандартное частотное распределение для отрывка английского открытого текста.
В стандартном распределении имеются пики, плато и впадины, и, чтобы сравнить его с распределением шифра L 1поищем наиболее заметные особенности и их комбинации. Так, весьма характерную особенность в стандартном распределении (рис. 15) составляют три пика у R-S-Ти длинная ложбина справа от них, которая захватывает шесть букв от Uдо Zвключительно. В распределении (рис. 14) есть только один похожий участок с тремя пиками у V-W-Хи последующей впадиной, простирающейся вдоль шести букв от Yдо D. А это означает, что все буквы, зашифрованные в соответствии с L 1были сдвинуты на четыре позиции, и L 1определяет шифралфавит, который начинается с Е, F, G, Н…, то есть первая буква ключевого слова, L 1это, по всей видимости, Е. Данное предположение может быть проверено путем сдвига распределения на четыре буквы назад и сравнения его со стандартным распределением. На рисунке 16 даны для сравнения оба распределения. Совпадение между основными пиками очень хорошее, так что нет никаких сомнений, что ключевое слово действительно начинается с буквы Е.

Рис. 14 Частотное распределение букв в зашифрованном с помощью шифралфавита L1 тексте (число появлений букв).

Рис. 15 Стандартное частотное распределение букв (число появлений букв на основе отрывка открытого текста, содержащего то же самое количество букв, что и в шифртексте).
Подведем итоги. Поиск повторений в шифртексте позволил нам определить длину ключевого слова, которое, как оказалось, состоит из пяти букв. Это позволило нам разделить шифртекст на пять частей, где каждая часть зашифрована с помощью шифра одноалфавитной замены, который определяется одной буквой ключевого слова. При анализе той части шифртекста, которая была зашифрована в соответствии с первой буквой ключевого слова, мы смогли показать, что эта буква, L 1, является, по-видимому, буквой Е. Этот же прием применяется и для поиска второй буквы ключевого слова. Выясняется распределение частот появления 2-й, 7-й, 12-й, 17-й… букв в шифртексте, и получившееся распределение, приведенное на рисунке 17, снова сравнивается со стандартным распределением, после чего находится величина сдвига.
Это распределение анализировать сложнее. Явных кандидатов для трех соседствующих пиков, которые соответствуют буквам R-S-T, не находится. Однако отчетливо видна ложбина, которая тянется от Gдо Lи которая, видимо, соответствует ложбине, идущей от Uдо Zв стандартном распределении. Если это так, то можно ожидать, что пики, соответствующие R-S-T, появятся у букв D, Еи F, однако пика у буквы Ене наблюдается.
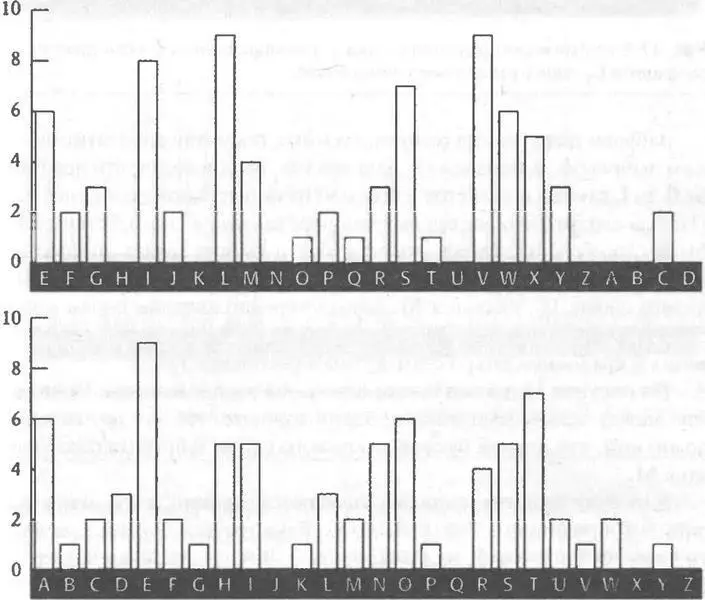
Рис. 16 Распределение L1 сдвинутое на четыре буквы назад (вверху), в сравнении со стандартным частотным распределением (внизу). Совпадают все основные пики и впадины.
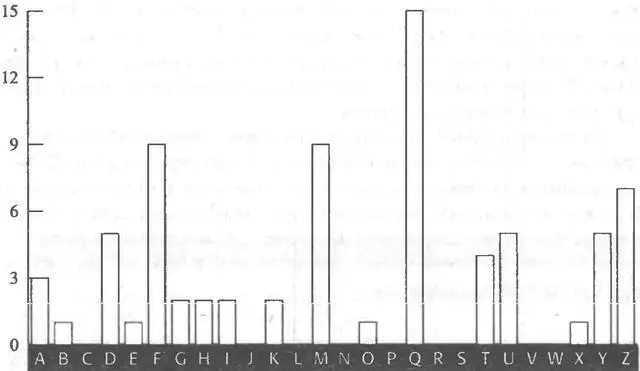
Рис. 17 Частотное распределение букв в зашифрованном с помощью шифралфавита L2 тексте (число появлений букв).
Забудем пока об отсутствующем пике, посчитав его статистическим выбросом, и продолжим наш анализ, предполагая, что ложбина от Gдо Lкак раз и является той самой отличительной особенностью. Отсюда следует, что все буквы, зашифрованные в соответствии с L 2, были сдвинуты на двенадцать позиций, и L 2определяет шифралфавит, который начинается с М, N, О, Р…, то есть второй буквой ключевого слова, L 2, является М. Данное предположение вновь может быть проверено путем сдвига распределения L 2на двенадцать букв назад и сравнения его со стандартным распределением.
Читать дальшеИнтервал:
Закладка:









