Саймон Сингх - Книга шифров .Тайная история шифров и их расшифровки

- Название:Книга шифров .Тайная история шифров и их расшифровки
- Автор:
- Жанр:
- Издательство:Астрель
- Год:2007
- Город:Москва
- ISBN:нет данных
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Саймон Сингх - Книга шифров .Тайная история шифров и их расшифровки краткое содержание
Саймон Сингх получил степень кандидата наук по физике в Кембриджском университете. Во время работы продюсером на Би-би-си снял удостоенный награды Британской академии кино и телевидения документальный фильм «Великая теорема Ферма» и написал бестселлер под тем же названием.
Шифры используются с тех пор, как люди научились писать. В «Книге шифров» Саймон Сингх посредством волнующих историй о шпионаже, интригах, интеллектуальном блеске и военной хитрости показывает захватывающую историю криптографии.
<<Изложение Сингха сочетает в себе увлекательность и наиболее содержательный анализ из всех, которые я когда-нибудь видел. Как и всегда, он блещет способностью объяснять>>.
<<Гардиан>>
Книга шифров .Тайная история шифров и их расшифровки - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Предположим, что мы перехватили это зашифрованное сообщение. Задача состоит в том, чтобы дешифровать его. Мы знаем, что текст написан на английском языке и что он зашифрован с помощью одноалфавитного шифра замены, но мы ничего не знаем о ключе. Поиск всех возможных ключей практически невыполним, поэтому нам следует применить частотный анализ. Далее мы шаг за шагом будем выполнять криптоанализ зашифрованного текста, но если вы чувствуете уверенность в своих силах, то можете попытаться провести криптоанализ самостоятельно.
При виде такого зашифрованного текста любой криптоаналитик немедленно приступит к анализу частоты появления всех букв; его результат приведен в таблице 2. Нет ничего удивительного в том, что частотность букв различна. Вопрос заключается в том, можем ли мы на основе частотности букв установить, какой букве алфавита соответствует каждая из букв зашифрованного текста. Зашифрованный текст сравнительно короткий, поэтому мы не можем непосредственно применять частотный анализ. Было бы наивным предполагать, что наиболее часто встречающаяся в зашифрованном тексте буква О является и наиболее часто встречающейся буквой в английском языке — еили что восьмая по частоте появления в зашифрованном тексте буква Y соответствует восьмой по частоте появления в английском языке букве h. Бездумное применение частотного анализа приведет к появлению тарабарщины. Например, первое слово РС<2 будет расшифровано как аоv.
Таблица 2 Частотный анализ зашифрованного сообщения.
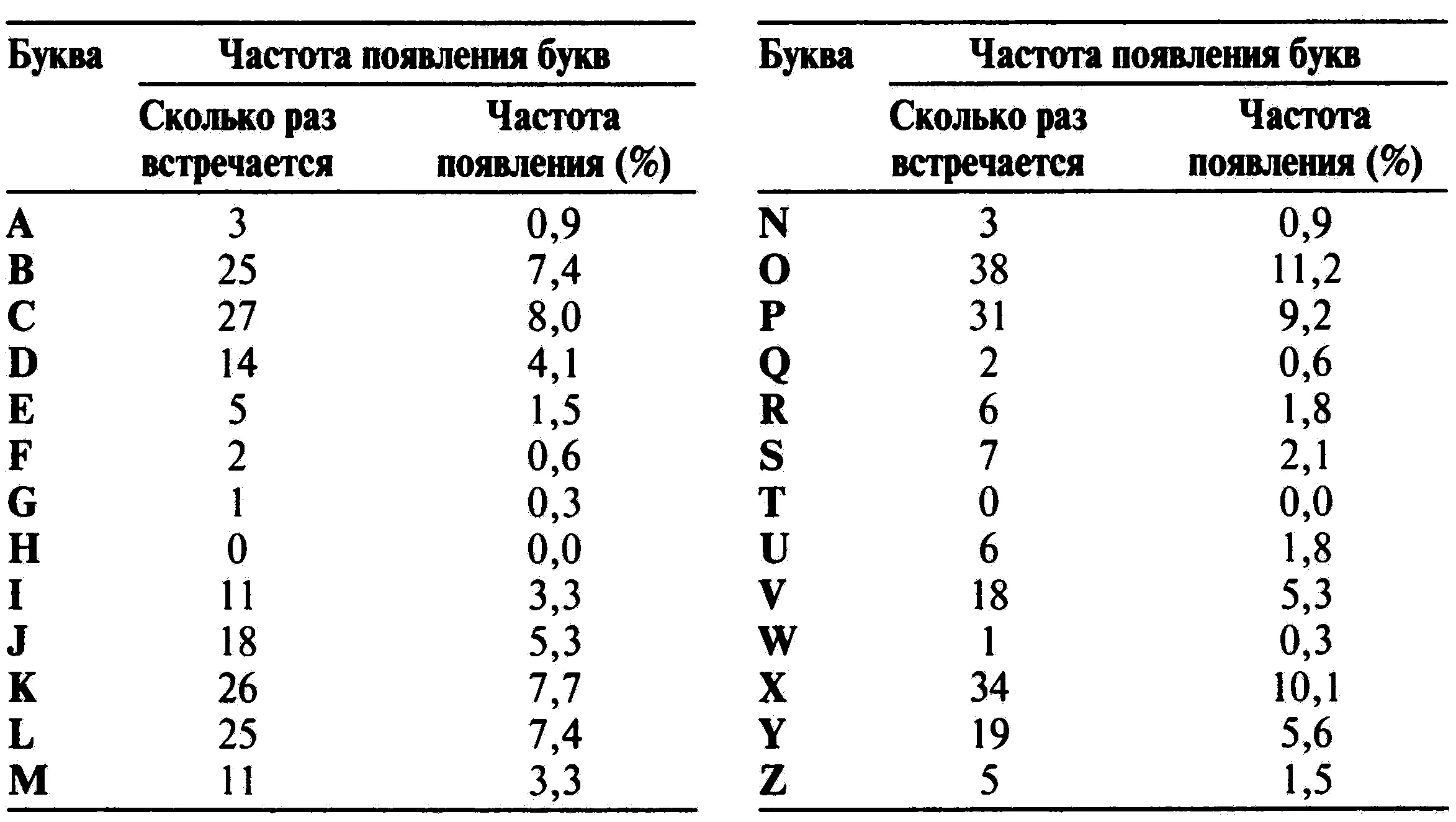
Начнем, однако, с того, что обратим внимание только на три буквы, которые в зашифрованном тексте появляются более тридцати раз: О, Xи Р.Естественно предположить, что эти наиболее часто встречающиеся в зашифрованном тексте буквы представляют собой, по всей видимости, наиболее часто встречающиеся буквы английского алфавита, но не обязательно в том же порядке. Другими словами, мы не можем быть уверены, что О = е, X = tи Р = а,но мы можем сделать гипотетическое допущение, что:
О= е, tили а, X= е, tили а, Р= е, tили а.
Чтобы быть уверенным в своих дальнейших действиях и идентифицировать три чаще всего встречающихся буквы: О, Xи Р,нам потребуется применить частотный анализ более тонким образом. Вместо простого подсчета частоты появления трех букв, мы можем проанализировать, как часто они появляются рядом с другими буквами. Например, появляется ли буква Оперед или после некоторых других букв, или же она стремится стоять рядом только с некоторыми определенными буквами? Ответ на этот вопрос будет убедительно свидетельствовать, является ли буква Огласной или согласной. Если Оявляется гласной, то она должна появляться перед и после большинства других букв, если же она представляет собой согласную, то она будет стремиться избегать соседства со множеством букв. Например, буква еможет появиться перед и после практически любой другой буквы, в то время как буква tперед или после букв b, d, g, j, k, m, qи vвстречается редко.
В нижеприведенной таблице показано, насколько часто каждая из трех чаще всего встречающихся в зашифрованном тексте букв: О, Xи Рпоявляется перед или после каждой буквы. О,к примеру, появляется перед Ав 1 случае, но никогда сразу после нее, поэтому в первой ячейке стоит 1. Буква Ососедствует с большинством букв, и существует всего 7 букв, которых она совершенно избегает, что показано семью нулями в ряду О.Буква Xобщительна в не меньшей степени, так как она тоже стоит рядом с большинством букв и чурается только 8 из них. Однако буква Ргораздо менее дружелюбна. Она приветлива только к нескольким буквам и сторонится 15 из них. Это свидетельствует о том, что Ои Xявляются гласными, а Рпредставляет собой согласную.

Теперь зададимся вопросом, каким гласным соответствуют Ои X.Скорее всего, что они представляют собой еи а— две наиболее часто встречающиеся гласные в английском языке, но будет ли О = еи X = а,или же О = а,а X = е?Интересной особенностью в зашифрованном тексте является то, что сочетание ООпоявляется дважды, а XX не попадается ни разу. Так как в открытом английском тексте сочетание букв еевстречается значительно чаще, чем аа,то, по всей видимости, О = еи X = а.
На данный момент мы с уверенностью определили две буквы в зашифрованном тексте. Наш вывод, что X = а,основан на том, что в зашифрованном тексте в некоторых позициях X стоит отдельным словом, а а— это одно из всего двух слов в английском языке, состоящих из одной буквы. Взашифрованном тексте есть еще одна отдельно стоящая буква, Y, и это означает, что она представляет собой второе однобуквенное английское слово — і.Поиск однобуквенных слов является стандартным криптоаналитическим приемом, и я включил его в список советов по криптоанализу в Приложении В.Этот прием срабатывает только потому, что в данном зашифрованном тексте между словами остались пробелы. Но зачастую криптографы удаляют все пробелы, чтобы затруднить противнику дешифрование сообщения.
Хотя у нас есть пробелы между словами, однако следующий прием сработает и там, где зашифрованный текст был преобразован в непрерывную строку символов. Данный прием позволит нам определить букву hпосле того, как мы нашли букву е. Ванглийском языке буква hчасто стоит перед буквой е(как, например, в the, then, theyи т. п.), но очень редко после е. Внижеприведенной таблице показана частота появления буквы О,которая, как мы полагаем, является буквой е,перед и после всех других букв в зашифрованном тексте. На основе этой таблицы можно предположить, что Впредставляет собой букву h,потому что она появляется перед Ов 9 случаях, но никогда не стоит после нее. Никакая другая буква в таблице не имеет такой асимметричной связи с О.
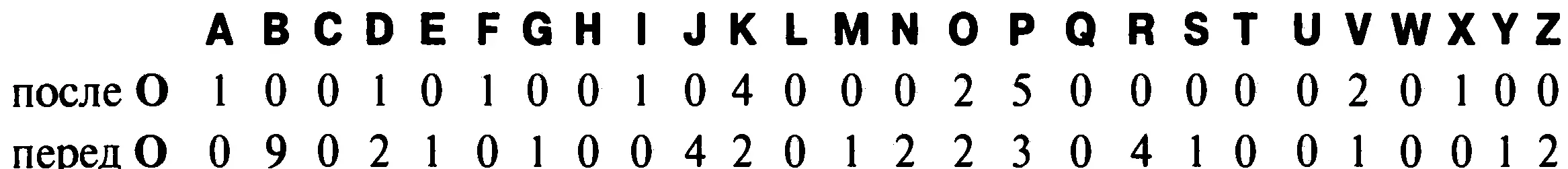
Интервал:
Закладка:









