Уиттакер . - Как тестируют в Google

- Название:Как тестируют в Google
- Автор:
- Жанр:
- Издательство:Издательский дом Питер
- Год:2014
- ISBN:978-5-496-00893-8
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Уиттакер . - Как тестируют в Google краткое содержание
Как тестируют в Google - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
А как насчет веб-сайтов, управляемых данными? Возьмем, например, сайты YouTube и CNN — их контент огромен и изменяется со временем. Не запутаются ли боты? Они справятся, если будут предупреждены о нормальных колебаниях данных этого сайта. Например, если в нескольких последовательных сериях изменился только текст статьи и картинки, то боты посчитают изменения уместными для данного сайта. Если показатели выйдут за рамки (допустим, при нарушении IFRAME или при переходе сайта на другой макет), боты могут подать сигнал тревоги и сообщить об этом веб-разработчику, чтобы он определил, нормально ли новое состояние или пора заводить соответствующий баг. Пример небольшого шума можно увидеть на рис. 3.32: на сайте CNET есть реклама, которая во время проверки
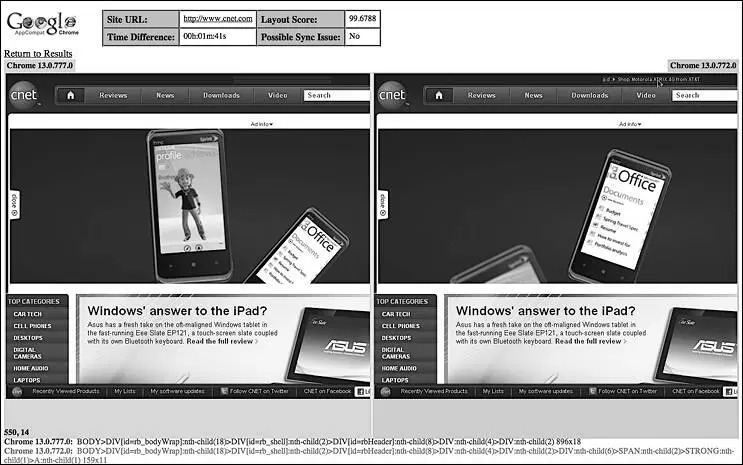
Рис. 3.32. Анализ визуальных различий для страниц с шумовыми различиями
появилась справа, а не слева. Такой шум считается небольшим и будет либо проигнорирован ботом, либо помечен как несущественный человеком, который моментально заметит, что это всего лишь реклама.
А что происходит дальше со всеми этими сигналами? Должен ли тестировщик или разработчик просматривать их все? На самом деле нет, мы уже ведем эксперименты по прямой передаче информации о различиях краудсорс-тестировщикам53, чтобы они быстро ее проверяли. Мы хотим оградить наши основные команды разработки и тестирования от лишнего шума. Мы просим внешних помощников посмотреть две версии веб-страницы и обнаруженные различия. Они отмечают, баг это или несущественное отклонение.
Как мы получаем данные от сообщества? Гениальное — просто: мы построили инфраструктуру, которая транслирует необработанные данные ботов на обычную страницу голосования для тестировщиков. Разумеется, мы сравнивали работу краудсорсеров со стандартными методами ручного рецензирования. Схема была следующая: боты пометили только шесть URL-адресов как требующие дополнительной проверки. Помеченные URL-адреса получили тестировщики из сообщества. Имея в арсенале данные ботов и инструменты визуализации различий, краудсорсеры определяли, ошибка ли это, в среднем за 18 секунд. А проверка всех 150 URL-адресов на регрессию ручными методами заняла около трех дней. Тестировщики из сообщества успешно определили все шесть различий как несущественные. Результаты работы краудсорсеров и ручной затратной формы проверки совпали! А зачем платить больше?
Звучит здорово! Правда, этот метод подходит только для статических версий веб-страниц. А как насчет интерактивных элементов — раскрывающихся меню, тестовых полей и кнопок? Мы ведем работу по решению этой проблемы, можно сказать, мы открыли киностудию: боты автоматически взаимодействуют с интересующими нас частями веб-страницы и снимают на каждом шаге кадр DOM. Затем «фильмы» каждой серии сравниваются покадрово с помощью той же технологии анализа различий.
В Google некоторые команды уже заменили большую часть своей ручной работы по регрессионному тестированию ботами. У них появилось время для более интересной работы, например исследовательского тестирования, которой они не могли заниматься раньше. Команда поставила себе цель сделать сервис общедоступным, выложить исходный код для всех и добавить возможности собственного хостинга, чтобы команды могли тестировать внутри своей сети, если кто-то не хочет открывать свои URL-адреса наружу. Мы не торопимся с массовым внедрением новой технологии — нужно убедиться в ее стопроцентной надежности.
Базовый код проекта Bots работает в инфраструктурах Skytap и Amazon EC2. Код сервиса распространяется по модели открытого кода (подробнее в блоге тестирования Google и приложении В). Теджас Шах был техническим руководителем Bots с первых дней существования проекта; позднее к нему присоединились Эриэл Томас, Джо Михаил и Ричард Бустаманте. Присоединяйтесь и вы к этим ребятам, чтобы двигать эксперимент дальше!
Как оценить качество всего интернета
Чтобы измерить, насколько хорошо поисковая система справляется с запросами, для теста мы берем случайную репрезентативную выборку поисковых запросов. По результатам можно судить, как система будет работать со всеми запросами, — мы просто экстраполируем данные. А если мы используем Bots на репрезентативной выборке URL-адресов, мы можем судить о качестве интернета в целом.
Сингулярность54: легенда о происхождении ботов
Джейсон Арбон
Давным-давно, в далеком-далеком офисе Google родилась… первая версия Chrome. Уже по первым поступившим данным было понятно, что Chrome отображает веб-страницы иначе, чем Firefox. В начале мы оценивали эти различия, только отслеживая объем поступающих сообщений о багах и подсчитывая количество жалоб на проблемы совместимости от пользователей, которые удаляли браузер после пробного использования.
Мне было интересно, есть ли более многоразовый, автоматизированный и объективный метод оценки того, насколько хорошо мы работаем в этой области. Были ребята до меня, которые пытались организовать автоматическое сравнение снимков веб-страниц между браузерами, а кто-то даже пытался использовать продвинутые методы распознавания изображений и границ. Правда, эти методы часто не работали, потому что между страницами всегда много различий, вспомните хотя бы о разных картинках в рекламе, меняющемся контенте и т.д. В базовых тестах макетов WebKit вычислялся хэш-код всего макета страницы (см. рис. 3.33). Поэтому когда обнаруживалась проблема, инженеры не имели понятия о том, что именно в приложении не работает, у них был только снимок ошибки. Многочисленные ложноположительные55 срабатывания только прибавляли работы инженерам, вместо того чтобы уменьшать ее.

Рис. 3.33. В ранних средствах тестирования макетов WebKit использовались хэши всего макета страницы. Теперь мы можем тестировать целые страницы и обнаруживать сбои на уровне элементов, а не на уровне страницы
Мысли постоянно возвращали меня к ранней простой реализации ChromeBot, которая обходила миллионы URL-адресов в запущенных копиях браузера Chrome на тысячах виртуальных машин. Она искала всевозможные сбои, используя для этого свободное процессорное время в центрах обработки данных. Это был ценный инструмент, который находил баги на ранней стадии, а функциональное тестирование взаимодействия с браузером добавлялось позже. К сожалению, технология утратила свою новизну и использовалась только для выявления редких сбоев. А что, если построить более серьезную версию этого инструмента, которая будет нырять во всю страницу целиком, а не только ходить по берегу? И назвать ее, например, Bots.
Читать дальшеИнтервал:
Закладка:

![Джулиан Ассанж - Google не то, чем кажется [отрывок из книги «When Google Met WikiLeaks»]](/books/1074503/dzhulian-assanzh-google-ne-to-chem-kazhetsya-otryvok.webp)