Педро Домингос - Верховный алгоритм

- Название:Верховный алгоритм
- Автор:
- Жанр:
- Издательство:Манн, Иванов и Фербер
- Год:2015
- ISBN:9785001001720
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Педро Домингос - Верховный алгоритм краткое содержание
Верховный алгоритм - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Когда Робби подрастет, он сможет применять один из вариантов метода главных компонент для решения проблемы «эффекта вечеринки», то есть чтобы выделить из шума толпы отдельные голоса. Схожий метод может помочь ему научиться читать. Если каждое слово — измерение, тогда текст — точка в пространстве слов, и главные направления этого пространства окажутся элементами значения. Например, «президент Обама» и «Белый дом» в пространстве слов далеко отстоят друг от друга, но в пространстве значений близки, потому что обычно появляются в схожих контекстах. Хотите верьте, хотите нет, но такой тип анализа — все, что требуется и компьютерам, и людям для оценки сочинений на экзаменах SAT (стандартизованный тест для приема в высшие учебные заведения США). В Netflix используется похожая идея. Вместо того чтобы рекомендовать фильмы, которые понравились пользователям со схожими вкусами, система проецирует и пользователей, и фильмы в «пространство вкуса» с низкой размерностью и рекомендует картины, расположенные в этом пространстве рядом с вами. Это помогает найти фильмы, которые вы никогда не видели, но обязательно полюбите.
Тем не менее главные компоненты набора данных о лице вас, скорее всего, разочаруют. Вопреки ожиданиям, это будут, например, не черты лица и выражения, а скорее размытые до неузнаваемости лица призраков. Дело в том, что метод главных компонент — линейный алгоритм, поэтому главными компонентами могут быть только взвешенные пиксель за пикселем средние реальных лиц (их еще называют «собственные лица», потому что они собственные векторы центрированной ковариационной матрицы этих данных, но я отхожу от темы). Чтобы по-настоящему понять не только лица, но и большинство форм в мире, нам понадобится кое-что еще, а именно нелинейное понижение размерности.
Представьте, что вместо карты Пало-Альто у нас есть GPS-координаты важнейших городов всей Области залива Сан-Франциско:
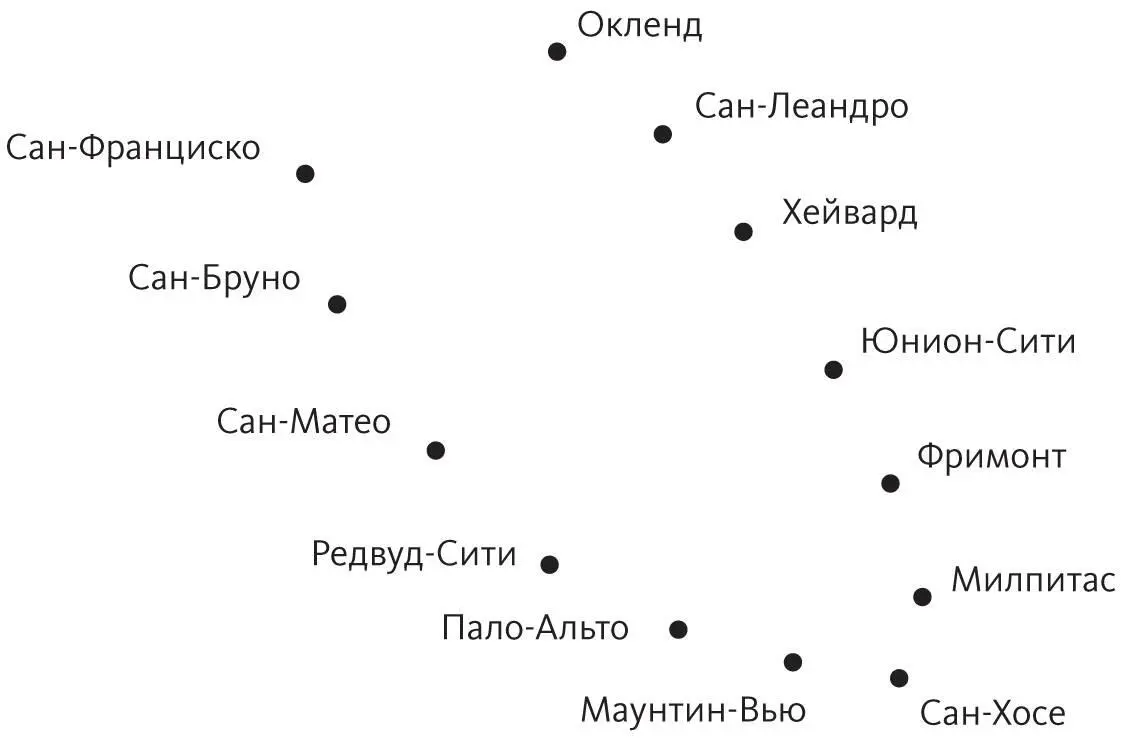
Глядя на эту схему, можно, вероятно, сделать предположение, что города расположены на берегу залива и, если провести через них линию, положение каждого города можно определить всего одним числом: как далеко он находится от Сан-Франциско по этой линии. Но метод главных компонент такую кривую найти не может: он нарисует прямую линию через центр залива, где городов вообще нет, а это только затуманит, а не прояснит форму данных.
Теперь представьте на секунду, что мы собираемся создать Область залива с нуля. Бюджет позволяет построить единую дорогу, чтобы соединить все города, и нам решать, как она будет проложена. Естественно, мы проложим дорогу, ведущую из Сан-Франциско в Сан-Бруно, оттуда в Сан-Матео и так далее, вплоть до Окленда. Такая дорога будет довольно хорошим одномерным представлением Области залива, и ее можно найти простым алгоритмом: «построй дорогу между каждой парой близлежащих городов». Конечно, у нас получится целая сеть дорог, а не одна, проходящая рядом с каждым городом, но можно получить и одну дорогу, если сделать ее наилучшим приближением сети, в том смысле, что расстояния между городами по этой дороге будут как можно ближе расстоянию вдоль сети.
Именно это делает Isomap — один из самых популярных алгоритмов нелинейного понижения размерности. Он соединяет каждую точку данных в высокоразмерном пространстве (пусть это будет лицо) со всеми близлежащими точками (очень похожими лицами), вычисляет кратчайшие расстояния между всеми парами точек по получившейся сети и находит меньшее число координат, которое лучше всего приближает эти расстояния. В отличие от метода опорных векторов, координаты лиц в этом пространстве часто довольно осмысленны: одна координата может показывать, в каком направлении смотрит человек (левый профиль, поворот на три четверти, анфас и так далее), другая — как лицо выглядит (очень грустное, немного грустное, спокойное, радостное, очень радостное) и так далее. Isomap имеет неожиданную способность сосредоточиваться на самых важных измерениях комплекса данных — от понимания движения на видео до улавливания эмоций в речи.
Вот интересный эксперимент. Возьмите потоковое видео из глаз Робби, представьте, что каждый кадр — точка в пространстве изображений, а потом сведите этот набор изображений к единственному измерению. Какое это будет измерение? Время. Как библиотекарь расставляет книги на полке, время ставит каждое изображение рядом с самыми похожими. Наверное, наше восприятие времени — просто естественный результат замечательной способности головного мозга понижать размерность. В дорожной сети нашей памяти время — главная автострада, и мы ее быстро находим. Другими словами, время — главная компонента памяти.
Жизнелюбивый робот
Кластеризация и понижение размерности приближают нас к пониманию человеческого обучения, но чего-то очень важного все равно не хватает. Дети не просто пассивно наблюдают за миром. Они активно действуют: замечают предметы, берут их в руки, играют, бегают, едят, плачут и задают вопросы. Даже самая продвинутая зрительная система будет бесполезна, если она не поможет Робби взаимодействовать со средой. Ему нужно не просто знать, где что находится, но и что надо делать в каждый момент. В принципе можно научить его выполнять пошаговые инструкции, соотнося показания сенсоров с соответствующими ответными действиями, но это возможно только для узких задач. Предпринимаемые действия зависят от цели, а не просто от того, что вы в данный момент воспринимаете, при этом цели могут быть весьма отдаленными. И потом, в любом случае нужно обойтись без пошагового контроля: дети учатся ползать, ходить и бегать сами, без помощи родителей. Ни один рассмотренный нами обучающий алгоритм так учиться не умеет.
У людей действительно есть один постоянный ориентир: эмоции. Мы стремимся к удовольствиям и избегаем боли. Коснувшись горячей плиты, вы непроизвольно отдернете руку. Это просто. Сложнее научиться не трогать плиту: для этого нужно двигаться так, чтобы избежать острой боли, которую вы еще не почувствовали. Головной мозг делает это, ассоциируя боль не просто с моментом прикосновения к плите, но и с ведущими к этому действиями. Эдвард Торндайк101 назвал это законом эффекта: действия, которые ведут к удовольствию, станут с большей вероятностью повторяться в будущем, а ведущие к боли — с меньшей. Удовольствие как будто путешествует назад во времени, и действия в конце концов могут начать ассоциироваться с довольно отдаленными результатами. Люди освоили такой поиск косвенных наград лучше, чем любое животное, и этот навык критически важен для успеха в жизни. В знаменитом эксперименте детям давали зефир и говорили, что, если они выдержат несколько минут и не съедят его, им дадут целых два. Те, кому это удалось, лучше успевали в школе и позже, когда стали взрослыми. Менее очевидно, наверное, то, что с аналогичной проблемой сталкиваются компании, использующие машинное обучение для совершенствования своих сайтов и методов ведения бизнеса. Компания может принять меры, которые принесут ей больше денег в краткосрочной перспективе — например, начать по той же цене продавать продукцию худшего качества, — но не обратить внимания, что в долгосрочной перспективе это приведет к потере клиентов.
Читать дальшеИнтервал:
Закладка:






