Карл Андерсон - Аналитическая культура

- Название:Аналитическая культура
- Автор:
- Жанр:
- Издательство:Манн, Иванов и Фербер
- Год:2017
- Город:Москва
- ISBN:нет данных
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Карл Андерсон - Аналитическая культура краткое содержание
Книга будет интересна CEO и владельцам бизнеса, менеджерам, аналитикам.
Аналитическая культура - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
(Процесс принятия решений будет темой следующей главы.)
Рекомендация: используйте калькулятор размера выборки.
Вопрос, который мне чаще всего задают относительно A/B-тестирования: «Как долго нужно проводить тестирование?» Обычно я отвечаю: «Я не знаю, нужно подсчитать с помощью калькулятора размера выборки».

Этот раздел более технический по сравнению с остальными, а потому те, кого статистика приводит в ужас, могут просто его пропустить. Основной вывод в том, что вам необходимо рассчитать минимальный размер выборки с помощью простого статистического онлайн-инструмента и придерживаться этого размера. Нельзя досрочно прекратить тестирование и рассчитывать на значимые результаты.
Причина, по которой непросто дать ответ на этот вопрос, заключается в том, что существует множество факторов, которые мы пытаемся оптимизировать.
Предположим, мы проводим стандартный A/B-тест. Есть четыре возможных сценария. Между сравниваемыми показателями не наблюдается различия, тогда:
1) мы приходим к верному заключению, что различия нет;
2) мы приходим к ошибочному заключению, что различия нет; это ложноположительный результат.
Или между сравниваемыми показателями наблюдается различие, тогда:
3) мы приходим к ошибочному заключению, что различия нет; это ложноотрицательный результат;
4) мы приходим к верному заключению, что различие есть.
Вышесказанное можно суммировать следующим образом.

Наша цель — попытаться оптимизировать вероятность верного заключения (1 или 4) и минимизировать вероятность сделать ложноположительное (2) или ложноотрицательное (3) заключение.
Для этого в нашем распоряжении два рычага, которыми мы можем воспользоваться.
Первый — более очевидный размер выборки. Если бы вы проводили опросы избирателей на президентских выборах, то были бы более уверены в своем прогнозе, если бы опросили 500 тыс. проголосовавших, а не 5 тыс. Это верно и относительно A/B-тестирования. Более значительная выборка повышает вашу статистическую мощность (статистический термин) при определении статистически достоверного различия, если это различие действительно существует. Возвращаясь к нашему примеру с четырьмя возможностями, если различие есть, то более крупная выборка снижает вероятность ложноотрицательного заключения (то есть более вероятно сделать вывод 4, чем 3). Обычно используется мощность 0,8. Это означает, что при существовании различия мы сможем определить его с вероятностью 80 %. Запомните это, мы вернемся к этому чуть позже.
Второй рычаг в нашем распоряжении — это статистический уровень значимости, обычно составляющий 5 % [137]. (Для масштабной выборки хороший подход — выбрать p ≤ 10 –4.) Это означает приемлемую вероятность сделать ложноположительное заключение, если на самом деле различия между сравниваемыми показателями нет. Предположим, у нас есть обычная монета. Мы подбросили ее десять раз, и десять раз выпал орел. Кажется, сюда закралась погрешность в пользу орла. Но самая обычная монета все же могла бы упасть орлом вверх десять раз подряд, но только один раз из 1024 раз, или примерно 0,1 % от всех случаев. Если мы предположим, что монета с погрешностью, то рискуем ошибиться в 0,1 % случаев. Это кажется приемлемым риском. Далее, предположим, мы решаем, что если мы увидим восемь, девять или десять орлов или, наоборот, ноль, один или два орла, то сделаем вывод, что монета с погрешностью. При этом есть вероятность ошибиться уже в 11 % случаев. Это кажется слишком рискованным. Суть в том, чтобы сбалансировать убедительность доказательства, что тестируемое качество действительно оказывает влияние, против вероятности, что мы наблюдаем лишь случайный эффект (а фактического различия нет).
Итак, вооружившись критерием статистической мощности = 0,8 и уровнем статистической значимости = 5 %, переходим к калькулятору размера выборки (рис. 8.3). Вводим два этих значения (см. нижнюю часть рисунка), но кроме этого нужно предоставить дополнительную информацию. Этот тип калькулятора (оптимизированный для определения конверсии, то есть контроля перехода на сайт) запрашивает базовый показатель коэффициента конверсии. Это значит текущий коэффициент в вашей контрольной группе. Он также запрашивает значение минимального заметного эффекта. Это означает, что при существовании значительного различия, например 7 %, вы сможете определить его сразу же и обойтись при этом небольшим размером выборки. Если требуется определить менее значительное различие, например 1 %, потребуется выборка более крупного размера, чтобы убедиться, что различие действительно существует и оно не случайно. При коэффициенте конверсии 10 % и различии 1 % вам потребуется выборка из 28 616 человек: 14 313 составят контрольную группу и столько же — тестовую.
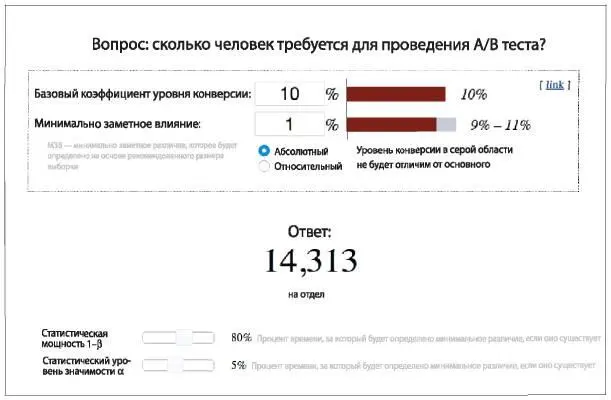
Рис. 8.3. Калькулятор размера выборки для определения конверсии
Источник: http://www.evanmiller.org/ab-testing/sample-size.html
Есть разные калькуляторы размера выборки, подходящие для разных ситуаций. Например, для сравнения средних значений, скажем, среднего размера корзины в контрольной группе и тестовой группе, калькулятор размера выборки будет похожим, но требования по вводимой информации станут слегка отличаться, например базовым показателем вариативности [138].
Оценить, сколько дней нужно на проведение эксперимента, можно путем деления среднего дневного трафика на общий размер выборки.
Обратите внимание, что это минимальный размер выборки. Предположим, исходя из размера выборки и уровня посещаемости вашего сайта, вам рекомендуется проводить тестирование в течение четырех дней. Если в эти дни уровень посещаемости сайта был ниже обычного среднего показателя, следует продолжить эксперимент, пока вы не достигнете минимального размера выборки. Если вы не продлите эксперимент или слишком рано его завершите, результаты будут необъективными. В итоге у вас повысится вероятность получить ложноотрицательное заключение: вы не сможете определить различие, которое существует. Более того, если наблюдается положительный результат, повышается вероятность того, что он не отражает действительность (см. Most Winning A/B Test Results Are Illusory [139]). Это чрезвычайно важный эффект. Вы видите положительное влияние, празднуете свою победу, запускаете тестируемую характеристику в массовое производство, а затем не наблюдаете никакого роста. Итог — напрасно потраченные время и силы, а кроме того, утрата доверия.
Читать дальшеИнтервал:
Закладка:





![Карл Юнг - Аналитическая психология [litres]](/books/1058248/karl-yung-analiticheskaya-psihologiya-litres.webp)


