Нихиль Будума - Основы глубокого обучения

- Название:Основы глубокого обучения
- Автор:
- Жанр:
- Издательство:Манн, Иванов и Фербер
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Нихиль Будума - Основы глубокого обучения краткое содержание
Основы глубокого обучения - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
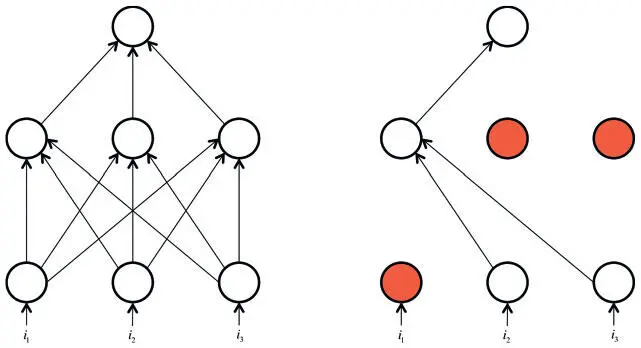
Рис. 2.16. Прореживание помечает каждый нейрон сети как неактивный с некой случайной вероятностью на каждом этапе обучения
Прореживание — понятный процесс, но стоит учесть несколько важных моментов. Во-первых, нужно, чтобы выходные значения нейронов во время тестирования были эквивалентны ожидаемым выходным значениям в процессе обучения. Мы можем добиться этого наивным способом, масштабировав параметры в тесте. Например, если p = 0,5, нейроны должны вдвое уменьшить выходные значения в тесте, чтобы обеспечить те же (ожидаемые) параметры в ходе обучения. Ведь выходное значение нейрона равно 0 с вероятностью (1 − p). И если до прореживания оно равнялось x , после прореживания ожидаемое значение будет E [output] = px + (1 − p) 0 = px . Но такое применение операции нежелательно, поскольку предполагает масштабирование выходных значений нейрона во время тестирования. Результаты тестов очень важны для оценки модели, и предпочтительнее использовать обратное прореживание , при котором масштабирование происходит в процессе обучения, а не тестирования. Выходное значение любого нейрона, активность которого не заглушена, делится на p перед передачей его на следующий уровень. Теперь
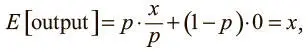
что позволит не прибегать к произвольному масштабированию выходных значений нейрона во время тестирования.
Резюме
Мы познакомились с основами обучения нейронных сетей с прямым распространением сигнала, поговорили о градиентном спуске, алгоритме обратного распространения ошибки, а также методах борьбы с переобучением. В следующей главе мы применим полученные знания на практике, используя библиотеку TensorFlow для эффективного создания первых нейросетей. В главе 4 мы вернемся к проблеме оптимизации целевых функций для обучения нейросетей и разработки алгоритмов, значительно повышающих качество обучения. Эти улучшения позволят обрабатывать гораздо больше данных, а следовательно, и строить более сложные модели.
Глава 3. Нейросети в TensorFlow
Что такое TensorFlow?
Мы могли бы на протяжении всей книги описывать абстрактные модели глубокого обучения, но надеемся, что в итоге вы не только поймете, как они работают, но и получите навыки, необходимые для создания их с нуля, чтобы решать задачи в вашей области. Вы уже лучше понимаете теорию моделей глубокого обучения, так что в этой главе мы обсудим программную реализацию некоторых алгоритмов.
Основной инструмент, который нам нужен, называется TensorFlow [17]. Это открытая программная библиотека, выпущенная в 2015 году Google, чтобы облегчить создание, разработку и обучение моделей. TensorFlow изначально была внутренней библиотекой для разработчиков Google, и мы думаем, что в открытую версию будут добавляться новые функции по мере их тестирования и проверки в Google. TensorFlow — лишь один из вариантов, доступных разработчикам, и мы выбрали эту библиотеку за продуманный дизайн и простоту использования. Краткое ее сопоставление с альтернативами будет дано в следующем разделе.
TensorFlow — библиотека Python, которая дает пользователям возможность выражать произвольные вычисления в виде графа потоков данных . Узлы графа соответствуют математическим операциям, а ребра — данным, которые передаются из одного узла в другой. Данные в TensorFlow представлены в виде тензоров — многомерных массивов (векторы — одномерные тензоры, матрицы — двумерные и т. д.).
Такой способ представления полезен во многих областях, но TensorFlow в основном используется для глубокого обучения в практике и исследованиях. Представление нейросетей в виде тензоров, и наоборот, — не тривиальная задача, а скорее навык, который нужно развить при работе с этой книгой. Это позволит применить варианты ускорения, которые обеспечивают современные компьютеры (например, для параллельных тензорных операций на графических процессорах) и даст четкий и выразительный способ внедрения моделей. Мы поговорим об основах использования TensorFlow и рассмотрим два простых примера (логистическую регрессию и многослойные сети с прямым распространением сигнала). Но, прежде чем погрузиться в предмет, сопоставим в общих чертах TensorFlow с альтернативами для моделей глубокого обучения.
Сравнение TensorFlow с альтернативами
Помимо TensorFlow, есть и ряд других библиотек для создания глубоких нейросетей. Это Theano, Torch, Caffe, Neon и Keras [18]. На основании двух простых критериев (выразительность и наличие активного сообщества разработчиков) мы в итоге сократили поле выбора до TensorFlow, Theano (создана в LISA Lab Монреальского университета) и Torch (в основном поддерживается командой Facebook AI Research).
Все три библиотеки могут похвастать солидным сообществом разработчиков, позволяют манипулировать тензорами с незначительными ограничениями и обеспечивают возможность автоматического дифференцирования (что позволяет пользователям обучать модели глубокого обучения без необходимости адаптировать алгоритм обратного распространения ошибок для различных архитектур нейросетей, как мы делали в предыдущей главе). Один из недостатков Torch, однако, в том, что эта среда написана на Lua. Это скриптовый язык, который напоминает Python, но мало используется за пределами собственного глубокого обучения. Мы решили не заставлять новичков осваивать новый язык ради создания моделей, так что вариантов теперь два: TensorFlow и Theano.
Из этих двух кандидатов выбрать было труднее (первый вариант главы написан с использованием Theano), но в конце концов мы остановились на TensorFlow по ряду незначительных причин. Во-первых, в Theano нужен дополнительный шаг — «компиляция графа», который занимает много времени при разработке определенных видов архитектур глубокого обучения. Хотя фаза компиляции невелика по сравнению со временем обучения, при написании и отладке нового кода она кажется неприятной. Во-вторых, у TensorFlow гораздо более понятный интерфейс. Многие классы моделей можно выразить значительно меньшим числом строк, не жертвуя общей выразительностью структуры. Наконец, TensorFlow создавалась для использования в продуктивных системах, а Theano разрабатывали ученые почти исключительно для исследовательских целей. Поэтому у TensorFlow много полезных функций и свойств, которые делают эту библиотеку лучшим вариантом для реальных систем (способность работать в мобильной среде, легко создавать модели для запуска на нескольких графических процессорах на одной машине и обучать масштабные сети распределенным методом). Знакомство с Theano и Torch полезно при изучении примеров из открытых источников, но анализ этих библиотек выходит за рамки этой книги [19].
Читать дальшеИнтервал:
Закладка:









