Нихиль Будума - Основы глубокого обучения

- Название:Основы глубокого обучения
- Автор:
- Жанр:
- Издательство:Манн, Иванов и Фербер
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Нихиль Будума - Основы глубокого обучения краткое содержание
Основы глубокого обучения - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Для более эффективного анализа проблемы И. Гудфеллоу и его коллеги (команда исследователей, объединившая специалистов из Google и Стэнфордского университета) опубликовали в 2014 году статью [42], в которой попытались разделить два этих фактора, способных вызвать затруднение. Вместо анализа функции ошибок во времени они исследовали, что происходит на поверхности ошибок между случайным образом инициализированным вектором параметров и успешным конечным решением, с помощью линейной интерполяции.
Итак, при случайным образом инициализированном векторе параметров θ i и решении стохастического градиентного спуска θ f мы намерены вычислить функцию ошибок в каждой точке методом линейной интерполяции θ α = α θ f + (1 − α ) θ i .
Ученые хотели понять, будут ли локальные минимумы помехой градиентному методу поиска даже в случае, если мы будем знать, куда двигаться. Оказалось, что для большого количества реальных сетей с разными типами нейронов прямой путь между случайным образом инициализированной точкой в пространстве параметров и решением стохастического градиентного спуска не осложняется сколь-нибудь проблемными локальными минимумами.
Мы можем даже показать это сами на примере сети с прямым распространением сигнала из нейронов ReLU, созданной в главе 3. Запустив контрольный файл, который мы сохранили при обучении исходной сети, мы можем пересоздать компоненты inference и loss, сохраняя список указателей на переменные в оригинальном графе для дальнейшего использования в var_list_opt (где opt — оптимальные настройки параметров):
# mnist data image of shape 28*28=784
x = tf.placeholder("float", [None, 784])
# 0–9 digits recognition => 10 classes
y = tf.placeholder("float", [None, 10])
sess = tf.Session()
with tf.variable_scope("mlp_model") as scope:
output_opt = inference(x)
cost_opt = loss(output_opt, y)
saver = tf.train.Saver()
scope.reuse_variables()
var_list_opt = [
"hidden_1/W",
"hidden_1/b",
"hidden_2/W",
"hidden_2/b",
"output/W",
"output/b"
]
var_list_opt = [tf.get_variable(v) for v in var_list_opt]
saver.restore(sess, "mlp_logs/model-checkpoint-file")
Так же мы можем повторно использовать конструкторы компонентов для создания случайным образом инициализированной сети. Вот как мы сохраняем переменные в var_list_rand для следующего шага программы:
with tf.variable_scope("mlp_init") as scope:
output_rand = inference(x)
cost_rand = loss(output_rand, y)
scope.reuse_variables()
var_list_rand = [
"hidden_1/W",
"hidden_1/b",
"hidden_2/W",
"hidden_2/b",
"output/W",
"output/b"
]
var_list_rand = [tf.get_variable(v) for v in var_list_rand]
init_op = tf.initialize_variables(var_list_rand)
sess.run(init_op)
Инициализировав две эти сети, мы можем вывести линейную интерполяцию при помощи параметров alpha и beta:
with tf.variable_scope("mlp_inter") as scope:
alpha = tf.placeholder("float", [1, 1])
beta = 1 — alpha
h1_W_inter = var_list_opt[0] * beta + var_list_rand[0] * alpha
h1_b_inter = var_list_opt[1] * beta + var_list_rand[1] * alpha
h2_W_inter = var_list_opt[2] * beta + var_list_rand[2] * alpha
h2_b_inter = var_list_opt[3] * beta + var_list_rand[3] * alpha
o_W_inter = var_list_opt[4] * beta + var_list_rand[4] * alpha
o_b_inter = var_list_opt[5] * beta + var_list_rand[5] * alpha
h1_inter = tf.nn.relu(tf.matmul(x, h1_W_inter) + h1_b_inter)
h2_inter = tf.nn.relu(tf.matmul(h1_inter, h2_W_inter) + h2_b_inter)
o_inter = tf.nn.relu(tf.matmul(h2_inter, o_W_inter) + o_b_inter)
cost_inter = loss(o_inter, y)
Наконец, мы можем варьировать значение alpha, чтобы определить, как меняется поверхность ошибок при переходе вдоль линии от случайным образом инициализированной точки к конечному решению стохастическим градиентным спуском:
import matplotlib.pyplot as plt
summary_writer = tf.train.SummaryWriter("linear_interp_logs/", graph_def=sess.graph_def)
summary_op = tf.merge_all_summaries()
results = []
for a in np.arange(-2, 2, 0.01):
feed_dict = {
x: mnist.test.images,
y: mnist.test.labels,
alpha: [[a]],
}
cost, summary_str = sess.run([cost_inter, summary_op], feed_dict=feed_dict)
summary_writer.add_summary(summary_str, (a + 2)/0.01)
results.append(cost)
plt.plot(np.arange(-2, 2, 0.01), results, ‘ro')
plt.ylabel(‘Incurred Error')
plt.xlabel(‘Alpha')
plt.show()
Получаем рис. 4.3, который мы можем проанализировать сами. Если мы будем повторять этот эксперимент, окажется, что никаких локальных минимумов, которые всерьез поставили бы нас в тупик, и нет. Судя по всему, основная сложность с градиентным спуском — не они, а трудности с выбором нужного направления. К этому вопросу мы вернемся чуть позже.
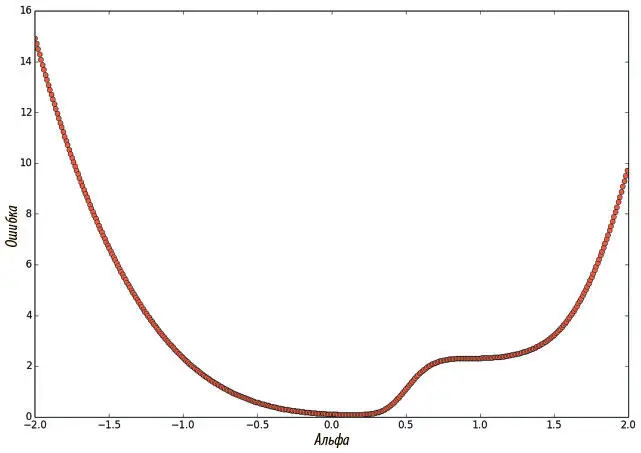
Рис. 4.3. Функция потерь трехслойной нейросети с прямым распространением сигнала при линейной интерполяции на линию, соединяющую случайным образом инициализированный вектор параметров и решение стохастического градиентного спуска
Плоские области на поверхности ошибок
Хотя наш анализ и показал отсутствие проблем с локальными минимумами, можно отметить особенно плоскую область, в которой градиент доходит до нуля, а alpha = 1. Это не локальный минимум, и вряд ли она поставит нас в затруднение, но кажется, что нулевой градиент может замедлить обучение.
В общем случае для произвольной функции точка, на которой градиент становится нулевым вектором, называется критической . Критические точки бывают разных типов. Мы уже говорили о локальных минимумах, несложно представить себе и их противоположности: локальные максимумы , которые, впрочем, не вызывают особых проблем при стохастическом градиентном спуске. Но есть и странные точки, лежащие где-то посередине. Эти «плоские» области — потенциально неприятные, но не обязательно смертельные — называются седловыми точками . Оказывается, когда у нашей функции появляется все больше измерений (а у модели все больше параметров), седловые точки становятся экспоненциально более вероятными, чем локальные минимумы. Попробуем понять, почему так происходит.
Для одномерной функции ошибок критическая точка может принимать одну из трех форм, как показано на рис. 3.1. Представим себе, например, что все эти три конфигурации одинаково вероятны. Если взять случайную критическую точку случайной одномерной функции, то вероятность того, что это локальный минимум, будет равна 1/3. И если у нас есть k критических точек, то можно ожидать, что локальными минимумами окажутся k/ 3 из них.
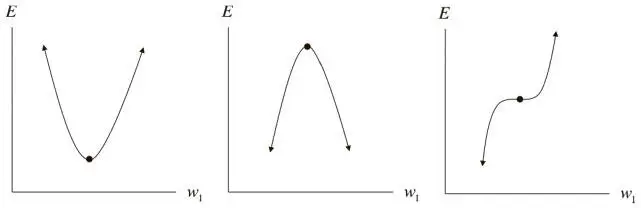
Рис. 4.4. Анализ критической точки в одном измерении
Можно распространить это утверждение на функции с большим числом измерений. Представим функцию потерь в d -мерном пространстве. Возьмем произвольную критическую точку. Оказывается, определить, будет ли она локальным минимумом, локальным максимумом или седловой точкой, сложнее, чем для одномерного случая. Рассмотрим поверхность ошибок на рис. 4.5. В зависимости от того, как выбирать направление (от A к B или от C к D), критическая точка будет казаться либо минимумом, либо максимумом. В реальности она ни то ни другое. Это более сложный тип седловой точки.
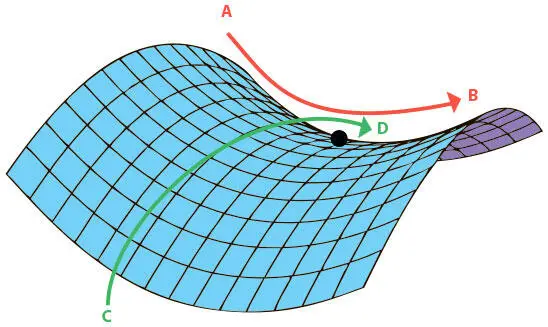
Рис. 4.5. Седловая точка на двумерной поверхности ошибок
Читать дальшеИнтервал:
Закладка:









