Нихиль Будума - Основы глубокого обучения

- Название:Основы глубокого обучения
- Автор:
- Жанр:
- Издательство:Манн, Иванов и Фербер
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Нихиль Будума - Основы глубокого обучения краткое содержание
Основы глубокого обучения - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
# to put attention on. (Сначала вычисляем конкатенацию выводов кодера, на которые нужно обратить внимание)
top_states = [
array_ops.reshape(e, [-1, 1, cell.output_size]) for e
in encoder_outputs
]
attention_states = array_ops.concat(1, top_states)
Создаем декодер. Если флаг output_projection не выбран, нейрон оборачивается, чтобы использовать проекцию выходного значения:
output_size = None
if output_projection is None:
cell = rnn_cell.OutputProjectionWrapper(cell,
num_decoder_symbols)
output_size = num_decoder_symbols
Отсюда вычисляем выходные значения и состояния с помощью embedding_attention_decoder:
if isinstance(feed_previous, bool):
return embedding_attention_decoder(
decoder_inputs,
encoder_state,
attention_states,
cell,
num_decoder_symbols,
embedding_size,
output_size=output_size,
output_projection=output_projection,
feed_previous=feed_previous,
initial_state_attention=initial_state_attention)
Стоит отметить, что embedding_attention_decoder — небольшое улучшение по сравнению с attention_decoder, описанным в предыдущем разделе. Здесь выходные значения проецируются на обученное пространство векторного представления, что обычно повышает производительность. Функция loop, которая просто описывает динамику рекуррентного нейрона с векторным представлением, вызывается на этом шаге:
def embedding_attention_decoder(decoder_inputs,
initial_state,
attention_states,
cell,
num_symbols,
embedding_size,
output_size=None,
output_projection=None,
feed_previous=False,
update_embedding_for_previous=
True,
dtype=None,
scope=None,
initial_state_attention=False):
if output_size is None:
output_size = cell.output_size
if output_projection is not None:
proj_biases = ops.convert_to_tensor(output_projection[1], dtype=dtype)
proj_biases.get_shape(). assert_is_compatible_with(
[num_symbols])
with variable_scope.variable_scope(
scope or "embedding_attention_decoder", dtype=dtype)
as scope:
embedding = variable_scope.get_variable("embedding",
[num_symbols, embedding_size])
loop_function = _extract_argmax_and_embed(
embedding, output_projection,
update_embedding_for_previous) if feed_previous
else None
emb_inp = [
embedding_ops.embedding_lookup(embedding, i) for i in
decoder_inputs
]
return attention_decoder(
emb_inp,
initial_state,
attention_states,
cell,
output_size=output_size,
loop_function=loop_function,
initial_state_attention=initial_state_attention)
Последний шаг — рассмотреть собственно attention_decoder. Как видно из названия, основное свойство этого декодера — вычислять набор весов внимания по скрытым состояниям, которые выдаются при кодировании. После профилактических проверок изменяем размер скрытых признаков на нужный:
def attention_decoder(decoder_inputs,
initial_state,
attention_states,
cell,
output_size=None,
loop_function=None,
dtype=None,
scope=None,
initial_state_attention=False):
if not decoder_inputs:
raise ValueError("Must provide at least 1 input to attention
decoder.") (Необходимо предоставить по меньшей мере один ввод декодеру внимания)
if attention_states.get_shape()[2].value is None:
raise ValueError("Shape[2] of attention_states must be known:
(Форма [2] attention_states должна быть известна)
%s" %
attention_states.get_shape())
if output_size is None:
output_size = cell.output_size
with variable_scope.variable_scope(
scope or "attention_decoder", dtype=dtype) as scope:
dtype = scope.dtype
batch_size = array_ops.shape(decoder_inputs[0])[0] # Needed
# for
#reshaping.
attn_length = attention_states.get_shape()[1].value
if attn_length is None:
attn_length = array_ops.shape(attention_states)[1]
attn_size = attention_states.get_shape()[2].value
# To calculate W1 * h_t we use a 1-by-1 convolution,
# need to reshape before. (Для вычисления W1 * h_t используем свертку 1 к 1, которую нужно предварительно переформатировать)
hidden = array_ops.reshape(attention_states,
[-1, attn_length, 1, attn_size])
hidden_features = []
v = []
attention_vec_size = attn_size # Size of query vectors
for attention. (Размер векторов запросов для внимания)
k = variable_scope.get_variable("AttnW_0",
[1, 1, attn_size,
attention_vec_size])
hidden_features.append(nn_ops.conv2d(hidden, k,
[1, 1, 1, 1], "SAME"))
v. append(
variable_scope.get_variable("AttnV_0",
[attention_vec_size]))
state = initial_state
Сейчас мы определим метод attention(), который получает вектор запросов и возвращает вектор весов внимания по скрытым состояниям. Этот метод реализует тот же подход к вниманию, что и в предыдущем разделе:
def attention(query):
"""Put attention masks on hidden using hidden_features and query.""" (Накладываем маски внимания на скрытый слой с помощью hidden_features и запросов)
ds = [] # Results of attention reads will be
# stored here. (Результаты чтения внимания будут храниться здесь)
if nest.is_sequence(query): # (если запрос n-мерен, делаем его плоским)
# flatten it.
query_list = nest.flatten(query)
for q in query_list: # Check that ndims == 2 if
# specified. (Проверяем, что ndims == 2, если указано)
ndims = q.get_shape(). ndims
if ndims:
assert ndims == 2
query = array_ops.concat(1, query_list)
# query = array_ops.concat(query_list, 1)
with variable_scope.variable_scope("Attention_0"):
y = linear(query, attention_vec_size, True)
y = array_ops.reshape(y, [-1, 1, 1,
attention_vec_size])
# Attention mask is a softmax of v^T * tanh(…). (Маска внимания — функция мягкого максимума v^T * tanh(…))
s = math_ops.reduce_sum(v[0] * math_ops.tanh(
hidden_features[0] + y),
[2, 3])
a = nn_ops.softmax(s)
# Now calculate the attention-weighted vector d. (Теперь вычисляем вектор весов внимания d)
d = math_ops.reduce_sum(
array_ops.reshape(a, [-1, attn_length, 1, 1]) *
hidden, [1, 2])
ds.append(array_ops.reshape(d, [-1, attn_size]))
return ds
При помощи этой функции вычисляем внимание по каждому из состояний вывода, начиная с начального:
outputs = []
prev = None
batch_attn_size = array_ops.stack([batch_size, attn_size])
attns = [array_ops.zeros(batch_attn_size, dtype=dtype)]
for a in attns: # Ensure the second shape of attention
# vectors is set. (Убеждаемся, что вторая форма векторов внимания задана)
a. set_shape([None, attn_size])
if initial_state_attention:
attns = attention(initial_state)
Выполняем тот же цикл для остальных входных данных. Проводим профилактическую проверку, чтобы убедиться, что входные данные на текущем шаге имеют нужный размер. Затем запускаем ячейки РНС и запрос внимания. Они объединяются и передаются на выход в соответствии с той же динамикой:
for i, inp in enumerate(decoder_inputs):
if i > 0:
variable_scope.get_variable_scope(). reuse_variables()
# If loop_function is set, we use it instead of
# decoder_inputs. (Если задана loop_function, используем ее вместо вводов декодера)
if loop_function is not None and prev is not None:
with variable_scope.variable_scope("loop_function",
reuse=True):
inp = loop_function(prev, i)
# Merge input and previous attentions into one vector of
# the right size. (Сливаем ввод и предыдущие внимания в один вектор нужного размера)
input_size = inp.get_shape(). with_rank(2)[1]
if input_size.value is None:
raise ValueError("Could not infer input size from input:
%s" % inp.name) (Нельзя вывести размер ввода из ввода)
x = linear([inp] + attns, input_size, True)
# Run the RNN. (Запускаем РНС)
cell_output, state = cell(x, state)
# Run the attention mechanism. (Запускаем механизм внимания)
if i == 0 and initial_state_attention:
with variable_scope.variable_scope(
variable_scope.get_variable_scope(), reuse=True):
attns = attention(state)
else:
attns = attention(state)
with variable_scope.variable_scope(
"AttnOutputProjection"):
output = linear([cell_output] + attns, output_size,
True)
if loop_function is not None:
prev = output
outputs.append(output)
return outputs, state
Мы успешно завершили подробную реализацию весьма изощренной нейронной системы машинного перевода. Продуктивные системы содержат дополнительные хитрости, которые не поддаются простым обобщениям, к тому же они обучаются на больших вычислительных серверах, чтобы обеспечивать передовые технологические возможности. Так, эта модель обучалась в течение четырех дней на восьми GPU NVIDIA Telsa M40. Показываем графики перплексии на рис. 7.31 и 7.32, а также изменение темпа обучения со временем.
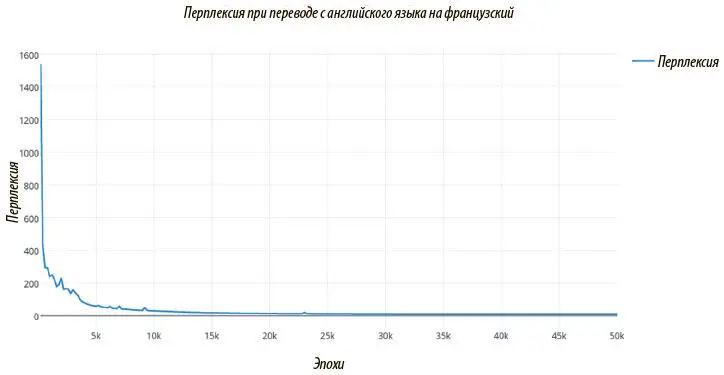
Рис. 7.31. График перплексии по обучающим данным во времени. После 50 тысяч эпох перплексия снижается примерно с 6 до 4 — вполне приличный результат для нейронной системы машинного перевода
Читать дальшеИнтервал:
Закладка:









