Нихиль Будума - Основы глубокого обучения

- Название:Основы глубокого обучения
- Автор:
- Жанр:
- Издательство:Манн, Иванов и Фербер
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Нихиль Будума - Основы глубокого обучения краткое содержание
Основы глубокого обучения - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
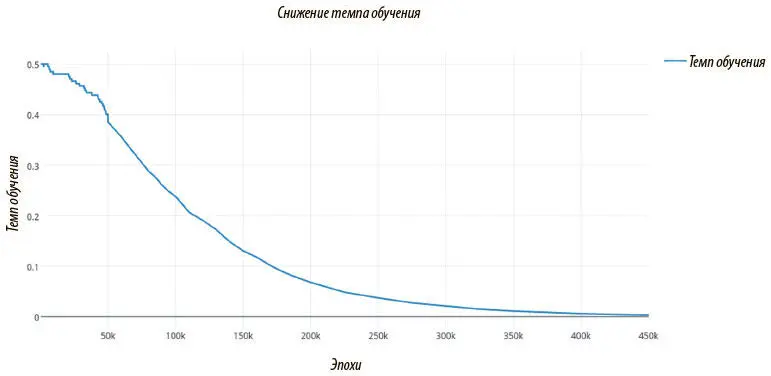
Рис. 7.32. График темпа обучения во времени; в отличие от перплексии, темп почти гладко снижается до 0. Это означает, что к моменту окончания обучения модель достигнет стабильного состояния
Чтобы ярче показать модель с вниманием, можно визуализировать внимание, которое вычисляет декодер LSTM при переводе предложения с английского языка на французский. Так, мы знаем, что, когда кодер LSTM обновляет состояние ячейки, чтобы сжать предложение до непрерывного векторного представления, он также вычисляет скрытые состояния на каждом шаге. Мы знаем, что декодер LSTM вычисляет выпуклую сумму по этим скрытым состояниям, и ее можно считать механизмом внимания: когда определенному скрытому состоянию соответствует больший вес, можно считать, что модель обращает больше внимания на токен, введенный на этом шаге.
Именно такую визуализацию мы и показываем на рис. 7.33. Английское предложение, которое необходимо перевести, приведено в верхней строке, а перевод на французский — в первом столбце.
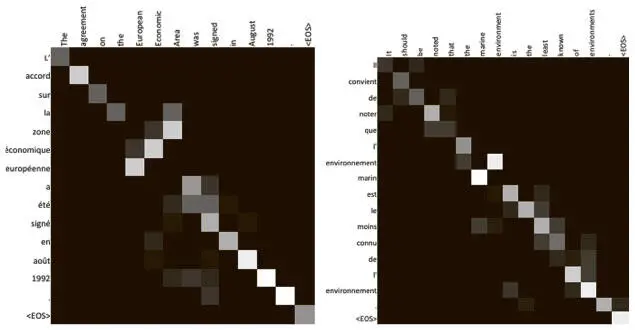
Рис. 7.33. Мы можем непосредственно визуализировать веса, когда декодер наблюдает скрытые состояния кодера. Чем светлее квадрат, тем больше внимания уделяется элементу
Чем светлее квадрат, тем больше внимания декодер уделил столбцу при декодировании этого элемента ряда. Таким образом, (i, j) — й элемент карты внимания показывает меру внимания, которая была уделена j -й метке в английском предложении при переводе i -й метки во французском.
Сразу можно увидеть, что механизм, судя по всему, работает неплохо. Внимание в основном уделяется именно нужным областям, хотя в предсказаниях модели и присутствует легкий шум. Возможно, добавление дополнительных слоев в сеть поможет добиться более четкого внимания.
Отметим особо, что словосочетание the European Economic Area («европейская экономическая зона») переводится на французский в обратном порядке — zone economique europeenne, и этот переворот отражается в весах внимания! Такие схемы могут быть еще интереснее, если переводить с английского на какой-то другой язык, который не так гладко разбивается слева направо. Разобрав и воплотив одну из важнейших архитектур, мы можем перейти к изучению поразительных новых достижений рекуррентных нейронных сетей и углубиться в более сложные аспекты обучения.
Резюме
В этой главе мы занимались анализом последовательностей. Мы разобрали, как заставить сети с прямым распространением сигнала обрабатывать последовательности, постарались понять работу рекуррентных нейронных сетей и остановились на многочисленных областях применения механизмов внимания: от переводов с языка на язык до расшифровки аудиофайлов.
Глава 8. Нейронные сети с дополнительной памятью
* * *
[96]
Мы уже убедились в том, насколько эффективной может быть РНС при решении таких сложных проблем, как машинный перевод. Но мы пока не раскрыли ее потенциал полностью. В главе 7 мы говорили о теоретических доказательствах того, что архитектура РНС обеспечит универсальное представление функций. Еще более точный результат можно получить при помощи полноты РНС по Тьюрингу . При грамотной архитектуре и адекватной установке параметров им будут под силу любые вычислительные задачи, решаемые компьютерными алгоритмами или машиной Тьюринга [97].
Нейронные машины Тьюринга
Однако добиться такой универсальности на практике крайне сложно. Причина в том, что мы имеем дело с огромным полем поиска вариантов архитектур и значений параметров РНС — настолько большим, что при помощи градиентного спуска очень трудно найти решение произвольной задачи. Ниже мы рассмотрим ряд подходов с переднего края исследований, позволяющих начать реализовывать этот потенциал.
Рассмотрим, например, очень простую проблему понимания чтения.
Мэри вышла в коридор. Она взялатам стакан с молоком. Затем она вернулась в офис, где увидела яблоко, и взяла его.
Сколько предметов в руках у Мэри?
Ответ тривиален: два! Но что в нашем мозге породило этот вариант? Если бы мы думали о том, как ответить на этот вопрос на понимание с помощью простой компьютерной программы, алгоритм, вероятно, выглядел бы так.
1. назначить ячейку памяти для подсчета .
2. инициализировать подсчет значением 0.
3. для каждого слова в тексте .
3.1. если слово — взяла.
3.1.1. увеличить число .
4. выдать значение.
Оказывается, мозг подходит к решению задачи почти так же, как и эта простая программа. Приступая к чтению, мы выделяем место в памяти (как и она) и помещаем туда полученные данные. Сначала мы фиксируем местоположение Мэри — судя по первому предложению, это коридор. Из второго получаем информацию о предметах, которые несет Мэри. Сейчас это стакан молока. Когда мы видим третье предложение, мозг модифицирует значение первой ячейки памяти: уже не коридор, а офис. К концу четвертого предложения вторая ячейка тоже модифицируется, вместив не только молоко, но и яблоко. Когда мы доходим до вопроса, мозг быстро обращается ко второй ячейке и получает оттуда информацию о том, что предметов два. В нейронауках и когнитивной психологии такая система кратковременного хранения информации и управления ею называется кратковременной памятью. Именно она лежит в основе исследований, которые мы будем рассматривать в этой главе.
В 2014 году Алекс Грейвз и коллеги из Google DeepMind впервые осветили этот вопрос в статье «Нейронные машины Тьюринга» [98], где ввели новую нейронную архитектуру под тем же названием — нейронная машина Тьюринга (Neural Turig Machine, NTM). Она состоит из контроллерной нейронной сети (обычно РНС) с внешним запоминающим устройством, созданным по принципу рабочей памяти мозга.
Рисунок 8.1 показывает, что то же сходство сохраняется и для архитектуры нейронной машины Тьюринга с внешней памятью вместо RAM, головками считывания/записи вместо шины считывания/записи и контроллера с сетью вместо CPU, за исключением того, что контроллер обучается программе, а в CPU она поступает в готовом виде.
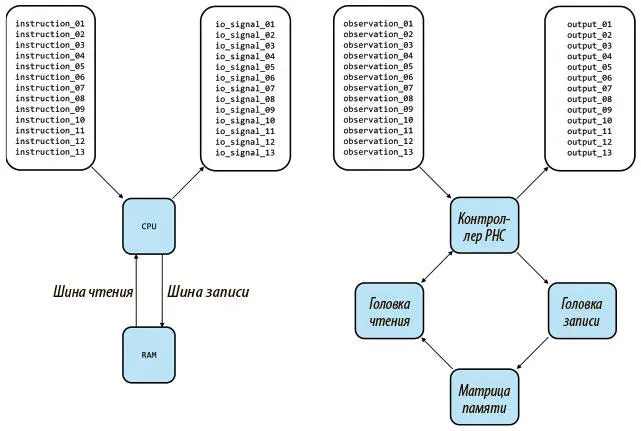
Рис. 8.1. Сравнение архитектуры современного компьютера, в который поступает готовая программа (слева), с нейронной машиной Тьюринга, которая обучается (справа). Здесь по одной головка чтения и записи, но в NTM их может быть и по нескольку
Читать дальшеИнтервал:
Закладка:









