Денис Соломатин - Математические модели в естественнонаучном образовании. Том II

- Название:Математические модели в естественнонаучном образовании. Том II
- Автор:
- Жанр:
- Издательство:неизвестно
- Год:2022
- ISBN:нет данных
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Денис Соломатин - Математические модели в естественнонаучном образовании. Том II краткое содержание
Математические модели в естественнонаучном образовании. Том II - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
а. Объясните, почему при сравнении последовательностей для 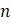 таксонов может появиться
таксонов может появиться 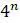 возможных шаблона.
возможных шаблона.
б. Некоторые шаблоны неинформативны. Простыми примерами являются четыре паттерна, показывающие одно и то же основание во всех последовательностях. Объясните, почему существуют 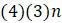 неинформативных паттернов, все последовательности которых совпадают, кроме одной.
неинформативных паттернов, все последовательности которых совпадают, кроме одной.
в. Сколько всего существует неинформативных шаблонов, в которых 2 основания появляются один раз, а все остальные совпадают?
г. Сколько существует неинформативных шаблонов, в которых 3 основания появляется один раз, а все остальные согласованы?
д. Объедините свои ответы, чтобы рассчитать количество информативных шаблонов для таксонов. Являются ли большинство шаблонов информативными для больших ?
5.4.8. Компьютерная программа, вычисляющая оценки экономии, может работать следующим образом: сначала сравните последовательности и подсчитайте количество сайтов 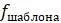 для каждого появляющегося информативного шаблона. Затем для данного дерева вычислите оценки экономии
для каждого появляющегося информативного шаблона. Затем для данного дерева вычислите оценки экономии 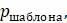 каждого из этих шаблонов. Наконец, используйте эту информацию для вычисления оценки экономии дерева, используя все последовательности. Какая формула необходима для выполнения заключительного шага? Другими словами, выразите оценку экономии дерева через и
каждого из этих шаблонов. Наконец, используйте эту информацию для вычисления оценки экономии дерева, используя все последовательности. Какая формула необходима для выполнения заключительного шага? Другими словами, выразите оценку экономии дерева через и 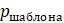 .
.
5.4.9. Показатели экономичности можно рассчитать еще эффективнее, используя тот факт, что несколько разных шаблонов всегда дают одинаковую оценку. Например, при сопоставлении 4 таксонов шаблоны (ATTA) и (CAAC) будут иметь одинаковую оценку.
а. Используя это наблюдение для 4 таксонов определите, сколько различных информативных таблиц должно быть рассмотрено, чтобы получить оценку экономии для всех возможных комбинаций?
б. Повторите часть (а) для 5 таксонов.
5.4.10. Используйте метод максимальной экономии для построения некорневого дерева для моделируемых последовательностей a1, a2, a3 и a4 в файле данных seqdata.mat. Сначала поместите последовательности в строки массива командой a=[a1;a2;a3;a4]. Затем найдите информативные сайты самостоятельно запрограммированной функцией infosites=informative(a). Наконец, извлеките информативные сайты с помощью команды ainfo=a(:,infosites).
а. Каков процент информативных сайтов?
б. Сколько различных деревьев следует проанализировать, чтобы найти самое экономное, относящееся к четырем таксонам?
в. Бывает слишком сложно использовать все информативные сайты для ручного расчета. Если это так, то используйте хотя бы первые 10 информативных сайтов, чтобы выбрать самое экономное дерево.
г. Согласуется ли найденное дерево топологически с тем, которое получается методом UPGMA и/или методом присоединения соседей с использованием расстояния Джукса-Кантора?
5.4.11. В этой задаче попытайтесь использовать метод максимальной экономии для построения некорневого дерева для ранее смоделированных последовательностей d1, d2, d3, d4, d5 и d6 в файле данных seqdata.mat. Начните с поиска информативных сайтов, как в предыдущей задаче.
а. Каков процент информативных сайтов?
б. Вычислите количество некорневых деревьев, которые необходимо изучить, если рассматривать все комбинации.
в. Используйте метод присоединения соседей, с логарифмическим расстоянием, вычисляемым из полных последовательностей, чтобы получить дерево, которое является хорошей отправной точкой для поиска наиболее экономных. Рассчитайте его оценку экономии, используя только первые 10 информативных сайтов.
г. Опять же, используя только первые 10 информативных сайтов, найдите по крайней мере 4 других дерева, которые похожи на одно из части (в). Можно ли найти более экономные?
д. Насколько уверены в том, что самое экономное дерево, которое нашли, действительно является самым экономным из всех возможных комбинаций? Для какого процента возможных деревьев вычислили оценки экономии? Какой процент информативных сайтов использовали?
5.5. Другие методы
На самом деле существует много других подходов к построению филогенетического дерева. Список предлагаемых методов довольно длинный и с каждым годом становится все длиннее, так как исследователи продолжают развивать данную проблематику.
В дополнение к дистанционным методам и методу максимальной экономии существует третий основной класс подходов, называемых методами максимального правдоподобия. Идея метода максимального правдоподобия состоит в том, что сначала предстоит выбрать конкретную модель молекулярной эволюции, например, модель Джукса-Кантора, 2- или 3-параметрическую модель Кимуры или более сложную. Затем нужно рассмотреть конкретное дерево, которое является кандидатом для описания связи данных таксонов. Предполагая, что эволюционная модель и конкретное дерево верны, можно рассчитать вероятность того, что последовательность ДНК могла быть получена именно на этих исходных данных. Вычисляется вероятность дерева, охватывающего имеющиеся данные. Повторяем этот процесс на всех остальных деревьях, получая значение вероятности для каждого. Затем выбираем дерево, к которого получилась наибольшая вероятность, поскольку именно такое дерево, как оказалось, лучше всего соответствует имеющимся данным.
Для многих исследователей методы максимального правдоподобия, которые следуют давней традиции в математической статистике, дают наибольшую надежду на то, что построенное дерево получилось хорошим. Однако можно столкнуться с рядом проблем. Во-первых, вычисляемые вероятности зависят от выбора конкретной модели эволюции, и если эта модель плохо описывает реальный процесс, то можно поставить под сомнение достоверность результатов. Во-вторых, как и в случае с экономностью, метод требует рассмотрения всех возможных деревьев, а значит, больших вычислительных затрат. Для каждой рассматриваемой топологии дерева требуется громоздкий расчет, чтобы найти оптимальные параметры модели, согласующиеся с данными. Если количество таксонов велико, то невозможно перебрать все возможные деревья, оптимизируя параметры модели для каждого, поэтому на практике используются эвристические методы сокращения числа свободных переменных. Хотя с практической точки зрения кажется, что данные методы работают хорошо, максимизация вероятности требует гораздо больше вычислительных ресурсов, чем другие подходы.
Читать дальшеИнтервал:
Закладка:









