Джин Ким - Руководство по DevOps

- Название:Руководство по DevOps
- Автор:
- Жанр:
- Издательство:Манн, Иванов и Фербер
- Год:2018
- Город:Москва
- ISBN:9785001007500
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Джин Ким - Руководство по DevOps краткое содержание
Руководство по DevOps - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
В следующих главах мы покажем, как встроить в работу петли обратной связи: они позволят всем сотрудникам работать над достижением общих целей, замечать проблемы сразу при их появлении, настраивать быстрое обнаружение сбоев и восстановление, а также проверять, что все элементы функциональности не только работают так, как запланировано, но также соответствуют целям организации и поддерживают получение новых знаний и обмен опытом.
Глава 14. Создайте телеметрию, позволяющую замечать проблемы и решать их
Суровая реальность жизни отдела IT-эксплуатации — не все идет так гладко, как хотелось бы. Небольшие изменения приводят к многообразным и неожиданным последствиям, включая задержки, простои в работе и масштабные сбои, влияющие на всех наших клиентов. Это реальность управления сложными системами; ни один человек не в состоянии охватить взглядом всю систему и понять, как ее части взаимодействуют друг с другом.
Когда в нашей повседневной работе происходит какой-нибудь неожиданный сбой, у нас не всегда есть информация, необходимая для решения проблемы. Например, не всегда можно определить, произошел ли сбой из-за проблемы в нашем приложении (например, из-за дефекта кода), в окружении (например, вследствие проблемы с передачей данных по сетям или с конфигурацией сервера) или в чем-то полностью внешнем (к примеру, DoS-атака).
В подразделении IT-эксплуатации с этими проблемами можно бороться с помощью золотого правила: что-то пошло не так — перезагрузи сервер. Если это не сработало, перезагрузи сервер рядом с предыдущим. Если и это не сработало, перезагрузи все серверы. Если же и это не исправило ситуацию, свали все на разработчиков, все сбои ведь происходят из-за них.
В то же время исследование, проведенное Microsoft Operations Framework (MOF) в 2001 г., показало, что организации с самым высоким уровнем обслуживания перезагружали свои серверы в 20 раз реже, чем условная средняя компания, и они в пять раз реже сталкивались с «синим экраном смерти». Другими словами, они обнаружили, что самые успешные компании гораздо лучше диагностировали и исправляли проблемы с серверами, применяя на практике то, что Кевин Бер, Жене Ким и Джордж Спаффорд назвали в своей книге The Visible Ops Handbook «культурой причинно-следственных связей». Успешные фирмы последовательно решали проблемы, используя производственную телеметрию, чтобы понять возможные причины неполадок и найти рабочие методы их устранения, в отличие от менее успешных фирм, слепо перезагружавших серверы.
Чтобы образ действий был направлен на решение проблем, нужно выстроить системы на основе непрерывно поступающих телеметрических данных. Под телеметрией обычно понимают «процесс автоматической коммуникации, с помощью которого измерения и другие данные собираются в удаленных точках и затем передаются на приемные устройства для последующего контроля». Наша цель в том, чтобы создать систему телеметрии в наших приложениях и окружении как внутри процесса разработки, так и в процессе развертывания и внедрения.
Майкл Рембетси и Патрик Макдоннелл описали, как наблюдение и контроль над созданием продукции были важнейшей частью начавшегося в 2009 г. перехода к системе DevOps в компании Etsy. Это было связано с тем, что они стандартизировали и перевели весь свой стек технологий в LAMP (Linux, Apache, MySQL и PHP), избавляясь от множества других технологий, поддерживать которые становилось все труднее.
В 2012 г. на конференции Velocity Макдоннелл рассказал, насколько рискованно это было: «Мы меняли нашу важнейшую инфраструктуру, чего клиенты никогда не заметили бы. Однако они точно заметили бы, если бы мы где-то напортачили. Нам нужно было больше показателей, чтобы можно было быть уверенными в том, что мы ничего не ломаем, проводя эти большие перемены. Это было нужно как для наших технических служб, так и для нетехнических, например для отдела маркетинга».
Далее Макдоннелл объясняет: «Мы начали аккумулировать все данные по серверам в систему мониторинга Ganglia, визуализировать ее в Graphite, программе с открытым исходным кодом, в которую мы много инвестировали. Мы собирали все данные в единое целое, начиная с бизнес-показателей и заканчивая количеством развертываний. Тогда мы модифицировали Graphite с помощью того, что называем “нашей уникальной и неповторимой методикой вертикальных линий”, отображающей на все графики показателей моменты, когда происходило развертывание. Благодаря такому подходу мы могли быстро замечать любые непредусмотренные побочные эффекты развертывания и внедрения. Мы даже начали ставить по всему офису мониторы, чтобы все могли видеть, как работают наши системы».
Обеспечивая возможность разработчикам добавлять телеметрию к их повседневной работе, они создали достаточно телеметрических систем, чтобы развертывания стали безопасными. К 2011 г. Etsy отслеживала более 200 тысяч производственных показателей на каждом уровне стека приложений (например, функциональные возможности приложения, работоспособность приложения, базы данных, операционная система, память, сетевые соединения, безопасность и так далее), а 30 наиболее важных показателей постоянно отображались на «информационной панели развертывания». К 2014 г. они отслеживали более 800 тысяч индикаторов, тем самым демонстрируя непреклонное стремление измерить все, что можно, и максимально упростить сам процесс измерения.
Как пошутил один из инженеров Etsy Йен Малпасс, «если в Etsy и есть религия, то это церковь графиков. Если что-то меняется, мы это отслеживаем. Иногда мы рисуем график того, что еще не меняется, на тот случай, если оно вдруг решит пуститься во все тяжкие… Отслеживание всего, что только можно, — ключ к быстрому продвижению вперед, но единственный способ воплотить этот принцип в жизнь — сделать так, чтобы отслеживание показателей было простым… Мы облегчаем сотрудникам задачу наблюдения за нужными им показателями сразу же, без поглощающих время изменений конфигурации или других сложных процессов».
Одним из открытий доклада 2015 State of DevOps Report было то, что в успешных организациях проблемы в процессе создания программного продукта решались в 168 раз быстрее, чем в других фирмах, причем у ведущих организаций медианное значение MTTR [106]измерялось в минутах, тогда как медианный показатель MTTR фирм с низкими показателями измерялся в днях. Две самые важные методики, позволившие минимизировать MTTR, заключались в использовании контроля версий IT-эксплуатацией и применении телеметрии и проактивного мониторинга рабочей среды.
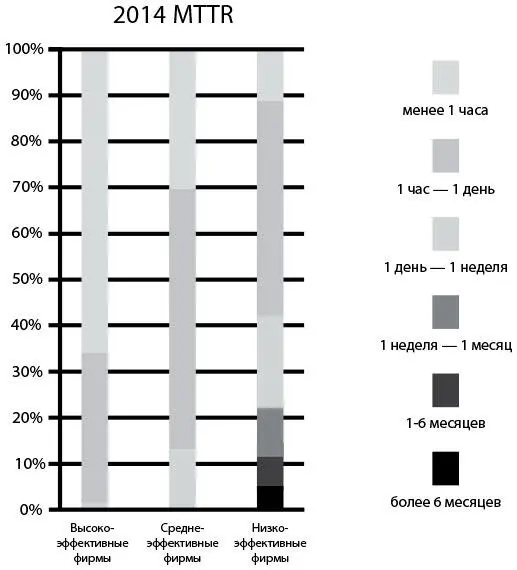
Рис. 25. Время устранения проблемы для высокоэффективных, среднеэффективных и низкоэффективных организаций (источник: отчет 2014 State of DevOps Report компании Puppet Labs)
Читать дальшеИнтервал:
Закладка:

