Джин Ким - Руководство по DevOps

- Название:Руководство по DevOps
- Автор:
- Жанр:
- Издательство:Манн, Иванов и Фербер
- Год:2018
- Город:Москва
- ISBN:9785001007500
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Джин Ким - Руководство по DevOps краткое содержание
Руководство по DevOps - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Наша цель в этой главе — вслед за Etsy построить такую систему телеметрии, чтобы мы всегда были уверены, что наши процессы в производстве протекают так, как нужно. И когда проблемы все-таки случаются, мы можем быстро определить, что пошло не так, и принять обоснованные решения, как лучше всего их разрешить, в идеале — задолго до того, как они повлияют на наших клиентов. Более того, телеметрия как раз и становится средством, позволяющим составить правильное представление о реальности и обнаружить места, где наше понимание расходится с истинным положением дел.
Эксплуатационный мониторинг и логирование — процедуры далеко не новые; многие поколения инженеров эксплуатации использовали и настраивали под себя разные платформы мониторинга (например, HP OpenView, IBM Tivoli, BMC Patrol/BladeLogic), чтобы обеспечить работоспособность производственных систем. Данные обычно собирались с помощью работающих на серверах агентов или с помощью мониторинга без агентов (например, SNMP-ловушки или наблюдение с помощью опросов). Часто для front-end был специальный графический интерфейс (GUI), а отчеты для back-end делались подробнее с помощью таких инструментов, как Crystal Reports.
Точно так же методики разработки приложений с помощью эффективного логирования и использования результатов телеметрии не есть нечто новое: практически для любого языка программирования существует множество разнообразных проработанных библиотек для логирования.
Однако в течение долгих десятилетий все, что у нас было — лишь разрозненные данные, логи созданные разработчиками, интересные только разработчикам, в эксплуатации же следят только за тем, работает ли среда или нет. В результате, когда происходит сбой, никто не может определить, почему вся система работает не так, как должна, или почему конкретный компонент выходит из строя. В результате, когда происходит сбой, никто не может определить, почему вся система работает не так, как должна, или почему конкретный компонент выходит из строя. Все это сильно осложняет попытки вернуть систему в рабочее состояние.
Чтобы отслеживать проблемы в момент возникновения, необходимо так спроектировать и организовать приложения и среду, чтобы они предоставляли телеметрию, позволяющую понять, как работает система в целом. Когда на всех уровнях стека приложения есть мониторинг и логирование, можно применять другие важные инструменты, например создание графиков и визуализацию показателей, обнаружение аномалий, проактивное оповещение и распространение информации и так далее.
В книге The Art of Monitoring Джеймс Торнбулл описал современную архитектуру мониторинга, разработанную и используемую инженерами эксплуатации в масштабных интернет-компаниях (например, Google, Amazon, Facebook). Эта архитектура часто состояла из инструментов с открытым исходным кодом (например, Nagios и Zenoss), измененных под заказчика и использованных в огромных масштабах: этого сложно было бы достичь с помощью лицензированных коммерческих программ того времени. Архитектура состоит из следующих компонентов.
• Сбор данных на уровнях бизнес-логики, приложения и среды.На каждом из этих уровней мы создаем телеметрию в виде событий, логов и показателей. Логи могут храниться в специфичных для приложения файлах на каждом сервере (например, /var/log/httpd-error.log), но будет лучше, если все логи будут отсылаться в одно и то же место, что упростит централизацию, ротацию и удаление. Такая услуга обеспечивается большинством операционных систем, например syslog для Linux, Event Log («Журнал событий») для Windows и так далее. Кроме того, мы собираем показатели на всех уровнях стека приложения, чтобы лучше понять, как ведет себя наша система. На уровне операционной системы можно собрать телеметрию работы центрального процессора, памяти, диска или использования сети с помощью таких инструментов, как collectd, Ganglia и так далее. Среди других собирающих данные инструментов можно назвать AppDynamics, New Relic и Pingdom.
• Маршрутизатор событий, ответственный за хранение событий и показателей.Этот компонент отвечает за визуализацию, отслеживание трендов, оповещение, обнаружение аномалий и многое другое. Собирая, храня и агрегируя нашу телеметрию, мы упрощаем последующий анализ и проверки работоспособности. Здесь же мы храним конфигурации, связанные с нашими службами (а также со связанными с ними приложениями и средой), и где, вероятно, оповещаем о превышении пороговых значений и проводим проверки работоспособности [107].
Собрав логи в одном месте, мы можем преобразовать их в показатели, подсчитывая их в маршрутизаторе событий; например, такое событие, как «child pid 14024 exit signal Segmentation fault», может быть подсчитано и просуммировано как один из показателей ошибки сегментации во всей производственной инфраструктуре.
Преобразовав логи в показатели, мы можем применить к ним статистические методы, например обнаружение отклонений от нормального состояния, чтобы выявлять выбросы и отклонения еще раньше. Скажем, настроить систему оповещения так, чтобы она сообщала о переходе от десяти ошибок сегментации на прошлой неделе к тысячам таких ошибок за последний час, что, конечно, требует тщательного расследования.
В дополнение к сбору телеметрии из служб и окружения необходимо также фиксировать важные события в процессе развертывания, например, когда программа проходит или проваливает автоматизированные тесты или когда мы развертываем продукт в любой среде. Кроме того, надо собирать данные, сколько времени требуется на выполнение сборок и на прохождение тестов. Так мы можем заметить условия, свидетельствующие о возможных проблемах, например если тест качества работы или сборка занимают в два раза больше времени, чем нужно. Это позволит найти и исправить ошибки до того, как они перейдут в фазу эксплуатации.
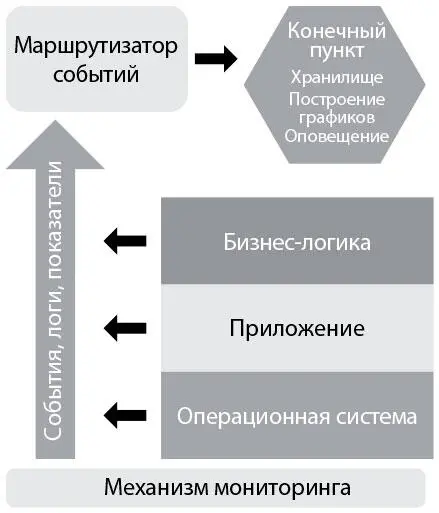
Рис. 26. Механизм мониторинга (источник: Торнбулл. The Art of Monitoring, Kindle edition, глава 2)
Далее нужно убедиться, что в нашу телеметрическую инфраструктуру легко заносить новую информацию и извлекать старую. Хорошо, если все будет организовано с помощью самообслуживающихся API, чтобы не приходилось оформлять тикет [108]и долго ждать отчета.
В идеале нужно создать телеметрическую систему, информирующую нас, когда, а также где и как именно произошло нечто интересное. Эта система должна быть удобна для анализа вручную и автоматизированно, а также данные должны быть доступны для анализа без доступа к самому приложению, предоставившему логи. Как заметил Адриан Коккрофт, «Мониторинг настолько важен, что наши системы мониторинга должны быть более доступными и более гибкими, чем то, за чем они наблюдают».
Читать дальшеИнтервал:
Закладка:

