Джин Ким - Руководство по DevOps

- Название:Руководство по DevOps
- Автор:
- Жанр:
- Издательство:Манн, Иванов и Фербер
- Год:2018
- Город:Москва
- ISBN:9785001007500
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Джин Ким - Руководство по DevOps краткое содержание
Руководство по DevOps - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
К примеру, если у нас есть сервис, поддерживающий электронную торговлю, нам нужно удостовериться, что у нас есть данные обо всех пользовательских событиях, ведущих к успешной транзакции, приносящей доход. Затем мы можем отслеживать все действия пользователя, необходимые для достижения желаемого результата.
Эти показатели будут разными в зависимости от сферы деятельности и целей компании. Например, для сайтов электронной торговли целью может быть максимизация времени, проведенного на сайте. Однако поисковым службам нужно ориентироваться на сокращение времени пребывания на странице, поскольку долгие сессии говорят о том, что пользователи не могут найти то, что хотят.
В общем случае бизнес-метрики будут частью воронки приобретения клиентов , то есть образного представления теоретических шагов, совершаемых потенциальным покупателем, решившим сделать покупку. Например, для сайта электронной торговли измеримыми событиями на этом пути будут общее время, проведенное на сайте, переходы по ссылкам на товары, добавление товаров в корзину и завершенные заказы.
Эд Бланкеншип, старший менеджер по продукции Microsoft Visual Studio Team Services, пишет: «Часто команды по разработке элемента функциональности определяют свои цели с помощью воронки приобретения клиентов. Их цель — сделать так, чтобы клиенты пользовались их функциональностью каждый день. Разные группы пользователей иногда неформально называют “зеваками”, “активными пользователями”, “вовлеченными пользователями” и “глубоко вовлеченными пользователями”. Для каждой такой стадии есть своя телеметрия».
Наша цель — сделать каждый бизнес-показатель действенным. Эти важнейшие индикаторы должны сообщать нам, как изменить продукт, и быть гибкими для экспериментирования и A/B-тестирования. Когда метрика не ведет к непосредственным действиям, скорее всего, это просто пустые индикаторы, предоставляющие мало полезной информации. Такие данные стоит хранить, но вот выставлять на обозрение не нужно и уж тем более не стоит бить из-за них тревогу.
В идеале любой, кто смотрит на наши распространители информации, должен суметь понять, как отображенные сведения связаны с целями компании, такими как доход, приобретение покупателей, коэффициент конверсии и так далее. Нужно определить и связать каждый показатель с бизнес-показателями на самых ранних стадиях определения функциональности и разработки и измерять результаты после развертывания в стадию эксплуатации. Кроме того, это помогает представителям заказчика описывать бизнес-контекст каждого элемента функциональности для всех в потоке создания ценности.
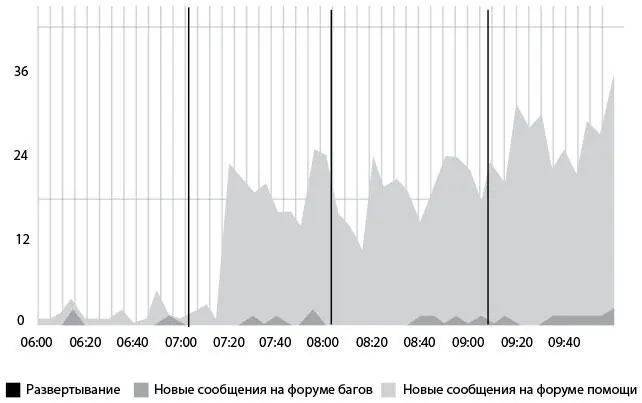
Рис. 28. Активность пользователей в связи с новой функциональностью после развертываний, измеренная в количестве форумных сообщений (источник: Майк Бриттен, “Tracking Every Release”, взято с сайта CodeasCraft.com, 8 декабря 2010 г., https://codeascraft.com/2010/12/08/track-every-release/)
Можно задать более общий бизнес-контекст, если иметь в виду и отображать на графиках периоды, важные с точки зрения ведения деятельности и высокоуровневого бизнес-планирования. Примерами могут служить временн ы е отрезки, на которые приходится большое число транзакций: пики продаж, связанные с праздниками, закрытие финансовых периодов в конце кварталов или запланированные аудиторские проверки. Эту информацию можно использовать как напоминание для того, чтобы не вносить существенные изменения в периоды, когда доступность сервиса крайне важна, или избегать каких-либо действий в разгар аудиторской проверки.
Распространяя информацию о действиях пользователей в контексте наших целей, мы получаем быструю обратную связь для команд, занятых конкретными элементами функциональности. Так они могут выяснить, действительно ли их сервисы используются и в какой степени они соответствуют бизнес-целям. В результате мы закрепляем ожидания, что мониторинг и анализ действий клиентов также часть нашей ежедневной работы, и сами лучше понимаем, как наша работа способствует достижению целей организации.
Точно так же, как и для показателей на уровне приложения, для индикаторов эксплуатационной и не эксплуатационной инфраструктуры наша цель — убедиться, что мы создаем достаточно телеметрии, чтобы быстро выяснить, действительно ли инфраструктура — одна из причин неполадки или нет. Кроме того, мы должны быть способны четко определить, что именно в инфраструктуре создает проблемы (например, базы данных, операционная система, запоминающее устройство, сетевые соединения и так далее).
Мы хотим сделать прозрачной как можно б о льшую часть инфраструктурной телеметрии, по всем компаниям, чьи программы и продукты мы используем. В идеале она должна быть организована по сервисам или по приложениям. Другими словами, когда в нашем окружении что-то идет не так, мы должны точно знать, на какие приложения и сервисы это влияет или может потенциально повлиять [114].
Раньше связи между сервисом и эксплуатационной инфраструктурой, от которой он зависел, создавались вручную (например, База данных управления конфигурациями (CMDB), ITIL или создание определений конфигурации в инструментах оповещения, например в Nagios). Однако сейчас эти связи все чаще регистрируются в сервисах автоматически, затем они открываются в динамическом режиме и используются в эксплуатации с помощью таких инструментов, как Zookeeper, Etcd, Consul и так далее.
Эти инструменты позволяют сервисам регистрироваться самостоятельно, сохраняя информацию, необходимую для других сервисов (например, IP-адрес, номера портов, URI). Такой подход решает проблему управления вручную базой данных конфигураций ITIL. Это особенно необходимо, когда сервисы состоят из сотен (а иногда тысяч и даже миллионов) узлов, каждый с динамически присваиваемым IP-адресом [115].
Вне зависимости от того, насколько просты или сложны наши службы, составление графиков по бизнес-метрикам и показателям инфраструктуры одновременно позволяет отслеживать разные проблемы. Например, мы можем увидеть, что регистрация новых пользователей упала на 20 % по сравнению с ежедневной нормой и в то же время все запросы к базам данных стали проводиться в пять раз дольше. Причины проблемы стали более ясными.
Кроме того, бизнес-метрика создает контекст для индикаторов инфраструктуры, благодаря чему облегчается совместная работа разработки и эксплуатации. По наблюдениям Джоди Малки, CTO [116]компании Ticketmaster/LiveNation, «вместо того чтобы оценивать отдел эксплуатации относительно потерянного времени, я считаю, что гораздо лучше оценивать разработку и эксплуатацию относительно реальных бизнес-последствий потерянного времени: какой доход мы должны были получить, но не смогли» [117].
Читать дальшеИнтервал:
Закладка:

