Джин Ким - Руководство по DevOps

- Название:Руководство по DevOps
- Автор:
- Жанр:
- Издательство:Манн, Иванов и Фербер
- Год:2018
- Город:Москва
- ISBN:9785001007500
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Джин Ким - Руководство по DevOps краткое содержание
Руководство по DevOps - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Оповещения можно сделать лучше, если увеличить отношение сигнала к шуму, фокусируясь на значимых отклонениях или выбросах. Предположим, что нам надо проанализировать число несанкционированных входов в систему в день. У собранных данных — распределение Гаусса (то есть нормальное распределение), совпадающее с графиком на рис. 29. Вертикальная линия в середине колоколообразной кривой — среднее, а первые, вторые и третьи стандартные отклонения, обозначенные другими вертикальными линиями, содержат 68, 95 и 99,7 % наблюдений соответственно.
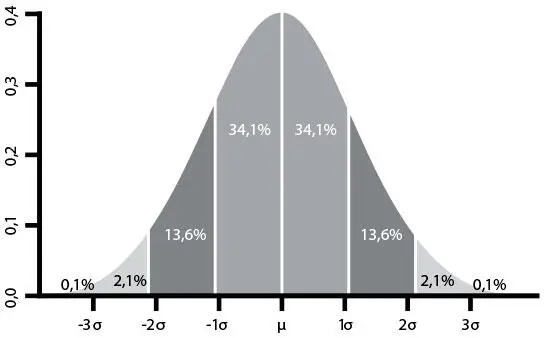
Рис. 29. Стандартные отклонения (σ) и среднее (µ) распределения Гаусса (источник: «Википедия», статья Normal Distribution, https://en.wikipedia.org/wiki/Normal_distribution)
Обычный способ использовать стандартные отклонения — время от времени проверять набор данных по какому-то показателю и сообщать, если он сильно отличается от среднего значения. Например, оповещение сработает, если число попыток несанкционированных входов в систему в день больше среднего на три величины стандартного отклонения. При условии, что данные распределены нормально, только 0,3 % всех событий будут включать сигнал тревоги.
Даже такая простая методика статистического анализа ценна, потому что никому не нужно определять пороговое значение. При отслеживании тысяч и сотен тысяч показателей это было бы невыполнимой задачей.
Далее в тексте термины телеметрия, показатель и наборы данных будут использоваться как синонимы. Другими словами, показатель (например, время загрузки страницы) будет увязываться с набором данных (например, 2 мс, 8 мс, 11 мс и так далее) Набор данных — статистический термин, обозначающий матрицу значений показателей, где каждый столбец представляет переменную, над которой производятся те или иные статистические операции.
Том Лимончелли, соавтор книги The Practice of Cloud System Administration: Designing and Operating Large Distributed Systems и бывший инженер по обеспечению надежности сайтов [118]компании Google, говорит о мониторинге показателей следующее: «Когда коллеги просят меня объяснить, что именно нужно мониторить, я шучу, что в идеальном мире мы удалили бы все имеющиеся оповещения в нашей системе наблюдения. Затем после каждого сбоя мы спрашивали бы себя: какие индикаторы могли бы предсказать этот сбой? И добавляли бы эти индикаторы в систему, настраивая соответствующие оповещения. И так снова и снова. В итоге у нас были бы только оповещения, предотвращающие сбои, тогда как обычно нас заваливает сигналами тревоги уже после того, как что-то сломалось».
На этом шаге мы воспроизведем результаты такого упражнения. Один из простейших способов добиться этого — это проанализировать самые серьезные инциденты за недавнее время (например, 30 дней) и создать список телеметрии, делающей возможной более раннюю и быструю фиксацию и диагностику проблемы, а также легкое и быстрое подтверждение того, что лекарство применено успешно.
Например, если наш веб-сервер NGINX перестал отвечать на запросы, мы могли бы взглянуть на индикаторы: они заблаговременно предупредили бы нас — что-то идет не так. Такими показателями могут быть:
• уровень приложения: увеличившееся время загрузки веб-страниц и так далее;
• уровень ОС: низкий уровень свободной памяти сервера, заканчивающееся место на диске и так далее;
• уровень баз данных: более долгие транзакции баз данных и так далее;
• уровень сети: упавшее число функционирующих серверов на балансировщике нагрузки и так далее.
Каждый из этих показателей — потенциальный предвестник аварии. Для каждого мы могли бы настроить систему оповещения, если они будут сильно отклоняться от среднего значения, чтобы мы могли принять меры.
Повторяя этот процесс для все более слабых сигналов, мы будем обнаруживать проблемы все раньше, и в результате ошибки будут затрагивать все меньше клиентов. Другими словами, мы и предотвращаем проблемы, и быстрее их замечаем и устраняем.
Проблемы телеметрии, имеющей негауссово распределение
Использование средних и стандартных отклонений для фиксации выбросов может быть очень полезным. Однако на некоторых наборах данных, используемых в эксплуатации, эти методики не будут давать желаемых результатов. Как отмечает Туфик Бубе, «нас будут будить не только в два часа ночи, но и в 2:37, 4:13, 5:17. Это происходит, когда у наших данных не нормальное распределение».
Другими словами, когда плотность распределения наблюдений описывается не показанной выше колоколообразной кривой, привычные свойства стандартных отклонений использовать нельзя. Например, представим, что мы наблюдаем за количеством скачиваний файла с нашего сайта в минуту. Нам нужно определить периоды, когда у нас необычно высокое число скачиваний. Пусть это число будет больше, чем три стандартных отклонения от среднего. Тогда мы сможем заранее увеличивать мощность или пропускную способность.
Рис. 30 показывает число одновременных скачиваний в минуту. Когда участок линии сверху графика выделен черным цветом, количество скачиваний в заданный период (иногда называемый «скользящим окном») превышает заданную величину. В противном случае линия окрашена в серый цвет.
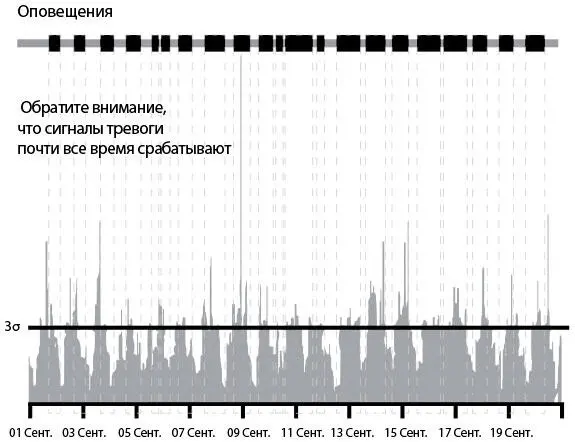
Рис. 30. Число загрузок в минуту: чрезмерное оповещение о проблемах при использовании правила трех стандартных отклонений (источник: Туфик Бубе, “Simple math for anomaly detection”)
График наглядно показывает очевидную проблему: оповещения идут практически непрерывным потоком. Это происходит потому, что почти в любой период у нас есть моменты, когда число скачиваний превышает порог в три стандартных отклонения.
Чтобы доказать это, построим гистограмму (рис. 31). На ней показана частота скачиваний в минуту. Форма гистограммы отличается от классической куполообразной кривой. Вместо этого распределение явно скошено к левому краю. Это говорит нам о том, что б о льшую часть времени у нас малое число скачиваний в минуту, но при этом число скачиваний очень часто превышает предел в три стандартных отклонения.
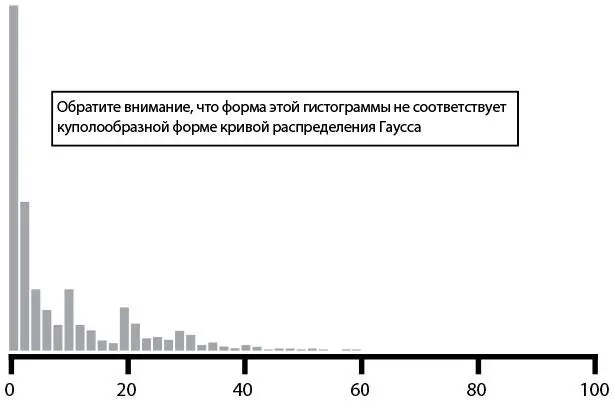
Рис. 31. Число скачиваний в минуту: гистограмма данных, имеющих негауссово распределение (источник: Туфик Бубе, “Simple math for anomaly detection”)
У многих реальных наборов данных распределение не нормально. Николь Форсгрен объясняет: «В эксплуатации у многих наших комплектов данных так называемое распределение хи-квадрат. Использование стандартных отклонений для них не только приводит к чрезмерному или недостаточному количеству оповещений, но и просто выдает бессмысленные результаты». Далее, Николь отмечает: «Когда вы считаете число одновременных скачиваний, которое на три стандартных отклонения меньше среднего, вы получаете отрицательное число. А это явно бессмысленно».
Читать дальшеИнтервал:
Закладка:

