Джин Ким - Руководство по DevOps

- Название:Руководство по DevOps
- Автор:
- Жанр:
- Издательство:Манн, Иванов и Фербер
- Год:2018
- Город:Москва
- ISBN:9785001007500
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Джин Ким - Руководство по DevOps краткое содержание
Руководство по DevOps - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Далее, все больше разработчиков начинают отправлять свой код в эксплуатацию. И, поскольку мы действуем в довольно сложной системе, мы наверняка что-то сломаем. Но теперь мы сможем быстро понять, какая именно функциональность вышла из строя, и быстро решить, нужно ли откатывать все назад или же можно решить все меньшей кровью. Это огромная победа для всей команды, все празднуют — мы на коне!
Однако команда хочет улучшить результаты развертывания, поэтому разработчики стараются проактивно получить больше отзывов от коллег о своем коде (это описано в главе 18), все помогают друг другу писать лучшие автоматизированные тесты, чтобы находить ошибки до развертывания. И, поскольку все теперь в курсе, что чем меньше вносимые изменения, тем меньше проблем у нас будет, разработчики начинают все чаще посылать все меньшие фрагменты кода в эксплуатацию. Таким образом, они убеждаются, что эти изменения проведены вполне успешно и можно переходить к следующей задаче.
Теперь мы развертываем код чаще, чем раньше, и надежность сервиса тоже становится лучше. Мы заново открыли, что секрет спокойного и непрерывного потока — в небольших и частых изменениях. Изучить и понять их может любой сотрудник.
Галбрет отмечает, что такое развитие событий идет на пользу всем, включая отдел разработки, эксплуатации и службу безопасности. «Поскольку я отвечаю и за безопасность тоже, мне становится спокойно от мысли, что мы можем быстро развертывать поправки в коде, потому что изменения внедряются на протяжении всего рабочего дня. Кроме того, меня всегда поражает, насколько все инженеры становятся заинтересованы в безопасности, когда ты находишь проблему в их коде и они могут быстро исправить ее сами».
История компании Right Media демонстрирует, что недостаточно просто автоматизировать процесс развертывания — мы также должны встроить мониторинг телеметрии в процесс внедрения кода, а также создать культурные нормы, гласящие, что все одинаково ответственны за хорошее состояние потока создания ценности.
В этой главе мы создадим механизмы обратной связи, помогающие улучшить состояние потока создания ценности на каждой стадии жизненного цикла сервиса или услуги, от проектирования продукта и его разработки до развертывания, сопровождения и снятия с эксплуатации. Такие механизмы помогут нам убедиться, что наши сервисы всегда «готовы к эксплуатации», даже если они находятся на ранних стадиях разработки. Кроме того, такой подход поможет встроить новый опыт после каждого релиза и после каждой проблемы в нашу систему, и работа станет для всех и безопаснее, и продуктивнее.
На этом шаге мы убедимся в том, что мы ведем активный мониторинг всей телеметрии, когда кто-нибудь проводит развертывание, как было продемонстрировано в истории Right Media. Благодаря этому после отправки нового релиза в эксплуатацию любой сотрудник (и из разработки, и из отдела эксплуатации) сможет быстро определить, все ли компоненты взаимодействуют так, как нужно. В конце концов, мы никогда не должны рассматривать развертывание кода или изменение продукта, пока оно не будет осуществляться в соответствии с производственной средой.
Мы добьемся цели благодаря активному мониторингу показателей нужного элемента функциональности во время развертывания кода. Так мы убедимся, что мы в продукте ничего случайно не сломали или — что еще хуже — что мы ничего не сломали в другом сервисе. Если изменения портят программу или наносят ущерб ее функциональности, мы быстро восстанавливаем ее, привлекая нужных для этого специалистов [124].
Как было описано в части III, наша цель — отловить ошибки в процессе непрерывного развертывания до того, как они дадут о себе знать в эксплуатации. Однако все равно будут ошибки, и мы их упустим, поэтому мы полагаемся на телеметрию, чтобы быстро восстановить работоспособность сервисов. Мы можем либо отключить неисправные компоненты функциональности с помощью флажков (часто это самый простой и безопасный способ, поскольку он не требует развертывания), либо закрепиться на передовой (fix forward) (то есть переписать код, чтобы избавиться от проблемы; этот код затем отправляется в эксплуатацию), либо откатывать изменения назад (roll back) (то есть возвращаться к предыдущему релизу с помощью флажков-переключателей или удаления сломанных сервисов с помощью таких стратегий развертывания, как Blue-Green и канареечные релизы и так далее).
Хотя закрепление на передовой часто рискованно, оно может быть очень надежным, если у нас есть автоматизированные тесты и процессы быстрого развертывания, а также достаточно телеметрии для быстрого подтверждения, что в эксплуатации все осуществляется правильно.
На рис. 37 показано развертывание кода на PHP в компании Etsy. После окончания оно выдало предупреждение о превышении времени исполнения. Разработчик заметил проблему через несколько минут, переписал код и отправил его в производство. Решение проблемы заняло меньше десяти минут.
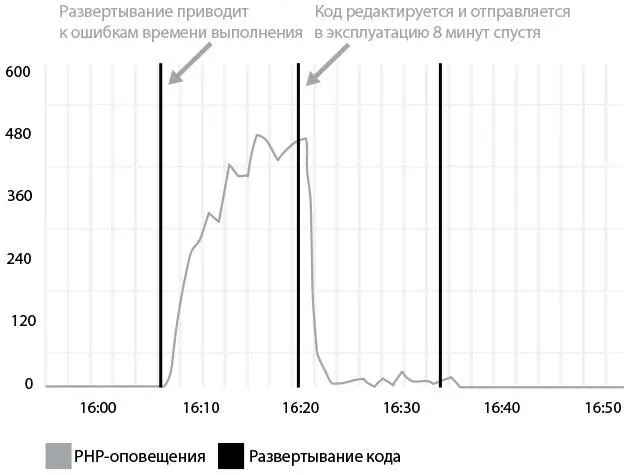
Рис. 37. Развертывание кода в Etsy.comгенерирует оповещения об ошибках времени выполнения. Они исправляются довольно быстро (источник: Майк Бриттен, “Tracking every release”)
Поскольку производственное развертывание — одна из главных причин неполадок в эксплуатации, информация о каждом внедрении и внесении изменений отображается на графиках, чтобы все сотрудники в потоке создания ценности были в курсе происходящих процессов. Благодаря этому улучшаются координация и коммуникация, а также быстрее замечаются и исправляются ошибки.
Даже если развертывания кода и релизы проходят гладко, в любой сложной системе всегда будут неожиданные проблемы, например сбои и падения в самое неподходящее время (каждую ночь в 2:00). Если их оставить без исправления, они будут источником постоянных проблем для инженеров в нижней части потока. Особенно если неполадки не видны инженерам в верхней части, ответственным за создание задач с проблемами.
Даже если устранение неполадки поручают команде разработчиков, его приоритет может быть ниже, чем создание новой функциональности. Проблема может возникать снова и снова на протяжении недель, месяцев и даже лет, приводя к хаосу и дестабилизации эксплуатации. Это хороший пример того, как команды в верхней части потока создания ценности могут оптимизировать работу для себя и в то же время ухудшить производительность всего потока создания ценности.
Читать дальшеИнтервал:
Закладка:

