Стюарт Рассел - Совместимость. Как контролировать искусственный интеллект

- Название:Совместимость. Как контролировать искусственный интеллект
- Автор:
- Жанр:
- Издательство:Альпина нон-фикшн
- Год:2021
- Город:Москва
- ISBN:978-5-0013-9370-2
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Стюарт Рассел - Совместимость. Как контролировать искусственный интеллект краткое содержание
В своей новаторской книге автор рассказывает, каким образом люди уже научились использовать ИИ, в диапазоне от смертельного автономного оружия до манипуляций нашими предпочтениями, и чему еще смогут его научить. Если это случится и появится сверхчеловеческий ИИ, мы столкнемся с сущностью, намного более могущественной, чем мы сами. Как гарантировать, что человек не окажется в подчинении у сверхинтеллекта?
Для этого, полагает Рассел, искусственный интеллект должен строиться на новых принципах. Машины должны быть скромными и альтруистичными и решать наши задачи, а не свои собственные.
О том, что это за принципы и как их реализовать, читатель узнает из этой книги, которую самые авторитетные издания в мире назвали главной книгой об искусственном интеллекте.
Все, что может предложить цивилизация, является продуктом нашего интеллекта; обретение доступа к существенно превосходящим интеллектуальным возможностям стало бы величайшим событием в истории. Цель этой книги — объяснить, почему оно может стать последним событием цивилизации и как нам исключить такой исход.
Введение понятия полезности — невидимого свойства — для объяснения человеческого поведения посредством математической теории было потрясающим для своего времени. Тем более что, в отличие от денежных сумм, ценность разных ставок и призов с точки зрения полезности недоступна для прямого наблюдения.
Первыми, кто действительно выиграет от появления роботов в доме, станут престарелые и немощные, которым полезный робот может обеспечить определенную степень независимости, недостижимую иными средствами. Даже если робот выполняет ограниченный круг заданий и имеет лишь зачаточное понимание происходящего, он может быть очень полезным.
Очевидно, действия лояльных машин должны будут ограничиваться правилами и запретами, как действия людей ограничиваются законами и социальными нормами. Некоторые специалисты предлагают в качестве решения безусловную ответственность.
Совместимость. Как контролировать искусственный интеллект - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Второе упрощающее допущение IRL состоит в том, что робот наблюдает за человеком в ситуации «единственного принимающего решения агента». Например, предположим, что робот учится в медицинском институте, чтобы стать хирургом, наблюдая за специалистом. Алгоритмы IRL предполагают, что человек выполняет операцию обычным оптимальным способом, как если бы робота рядом не было. Однако это не так: хирург мотивирован помочь роботу (как и любому другому студенту) обучиться хорошо и быстро и соответственным образом меняет свое поведение. Он может объяснять свои действия, обращать внимание на ошибки, которые следует избегать, — скажем, делать слишком глубокий разрез или шить слишком туго, — может описывать манипуляции в нештатной ситуации, если во время операции что-нибудь случилось. Никакие из этих действий не имеют смысла, если выполняешь операцию без студентов, и алгоритмы IRL не смогут понять, какие предпочтения за ними стоят. Поэтому мы должны будем обобщить IRL, перейдя от ситуации одного агента к ситуации с множественными агентами, а именно — создать алгоритмы обучения, работающие в случае, когда человек и робот являются частью общей среды и взаимодействуют друг с другом.
Человек и робот в одной среде — это пространство теории игр, как в том примере, где Алиса била пенальти в ворота Боба. В этой первой версии теории мы предполагаем, что человек имеет предпочтения и действует соответственно им. Робот не знает предпочтений человека, но все равно хочет их удовлетворить. Мы будем называть любую такую ситуацию игрой в помощника , поскольку предполагается, что робот по определению должен помогать человеку [260] Первоначальное название игры в ассистента — игра на кооперацию в рамках обратного обучения с подкреплением , или CIRL. См.: Dylan Hadfield-Menell et al., «Cooperative inverse reinforcement learning», in Advances in Neural Information Processing Systems 29, ed. Daniel Lee et al. (2016).
.
Игры в помощника подкрепляют три принципа, описанные в предыдущей главе: единственная задача робота — удовлетворить предпочтения человека, он изначально не знает, в чем они заключаются, и может больше узнать о них, наблюдая за его поведением. Пожалуй, самое интересное свойство этих игр состоит в следующем: чтобы решить игровую задачу, робот должен самостоятельно научиться интерпретировать поведение человека как источник информации о человеческих предпочтениях.
Игра в скрепку
Первый пример игры в помощника — игра в скрепку. Это очень простая игра, в которой человек Гарриет имеет стимул как-то «сигнализировать» роботу Робби о своих предпочтениях. Робби способен интерпретировать этот сигнал, потому что он может решить игровую задачу, следовательно, понять, что является истинным в отношении предпочтений Гарриет, то есть что заставило ее подать соответствующий сигнал.
Ход игры описан на рис. 12. Речь идет об изготовлении скрепок и скобок. Предпочтения Гарриет выражаются функцией выигрыша, которые зависят от количества произведенных скрепок и скобок с определенным «соотношением курсов» того и другого. Например, она может оценивать одну скрепку в 45 центов, а одну скобку в 55 центов. (Мы предполагаем, что сумма двух стоимостей всегда составляет $1; важно лишь соотношение.) Итак, если произведено 10 скрепок и 20 скобок, вознаграждение Гарриет составит 10 × 45 + 20 × 55 = $15,50. Робот Робби изначально находится в полной неопределенности относительно предпочтений Гарриет: он имеет равномерное распределение цены скрепки (она с равной вероятностью может иметь любое значение от 0 центов до $1). Гарриет делает первый ход, на котором имеет выбор, произвести ли две скрепки, две скобки или одну скрепку и одну скобку. Затем Робби может выбирать между изготовлением 90 скрепок, 90 скобок или 50 скрепок и 50 скобок [261] Числа выбраны так, чтобы игра стала интереснее.
.
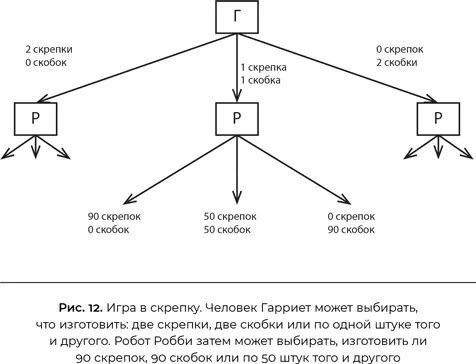
Заметьте, если бы Гарриет все делала сама, то просто изготовила бы две скобки ценностью $1,10. Но Робби наблюдает и учится на ее выборе. Что именно он усваивает? Это зависит от того, как Гарриет делает выбор. Как же она его делает? Это зависит о того, как Робби станет его интерпретировать. Похоже, мы попали в замкнутый круг! Это норма для задач теории игр, поэтому Нэш и предложил понятие равновесного решения.
Чтобы найти равновесное решение, нужно определить стратегии Гарриет и Робби, так, чтобы ни у одного из них не было стимула менять стратегию при условии, что другая остается неизменной. Стратегия Гарриет определяет, сколько скрепок и скобок изготовить, с учетом ее предпочтений; стратегия Робби определяет, сколько скрепок и скобок изготовить, с учетом действия Гарриет.
Оказывается, есть лишь одно равновесное решение, вот оно:
• Гарриет рассуждает следующим образом, опираясь на свою оценку цены скрепок:
— если цена скрепки меньше 44,6 цента, делаем 0 скрепок и 2 скобки;
— если цена скрепки от 44,6 до 55,4 цента, делаем по одной штуке того и другого;
— если цена скрепки больше 55,4 цента, делаем 2 скрепки и 0 скобок.
• Реакция Робби:
— если Гарриет делает 0 скрепок и 2 скобки, изготовим 90 скобок;
— если Гарриет делает по 1 штуке того и другого, изготовим 50 скрепок и 50 скобок;
— если Гарриет делает 2 скрепки и 0 скобок, изготовим 90 скрепок.
(Если вам интересно, как именно получено решение, смотрите детали в сносках [262].) При этой стратегии Гарриет фактически учит Робби своим предпочтениям при помощи простого кода — можно сказать, языка, — следующего из анализа равновесия. Алгоритм IRL с единственным агентом из примера об обучении хирургии не понял бы этот код. Заметьте также, что Робби никогда не получит точного знания о предпочтениях Гарриет, но он узнает достаточно, чтобы оптимально действовать в ее интересах — именно так, как действовал бы, если бы точно знал ее предпочтения. Он, скорее всего, полезен Гарриет при сформулированных допущениях и при условии, что Гарриет играет в игру правильно.
Можно также построить задачи, в которых Робби как примерный студент будет задавать вопросы, а Гарриет как хороший учитель указывать ему на подводные камни, которых следует избегать. Такое поведение возникает не потому, что мы написали сценарии для Гарриет и Робби, а потому что это оптимальное решение игры в помощника, в которой участвуют Гарриет и Робби.
Инструментальной является цель, в общем полезная в качестве подцели практически любой исходной цели. Самосохранение — одна из инструментальных целей, поскольку лишь очень немногих исходных целей легче достичь, будучи мертвым. Это ведет к проблеме выключателя : машина, имеющая фиксированную цель, не позволяет себя выключить и имеет стимул сделать свое выключение невозможным.
Читать дальшеИнтервал:
Закладка:




![Мередит Бруссард - Искусственный интеллект [Пределы возможного] [litres]](/books/1073206/meredit-brussard-iskusstvennyj-intellekt-predely.webp)




