Стюарт Рассел - Совместимость. Как контролировать искусственный интеллект

- Название:Совместимость. Как контролировать искусственный интеллект
- Автор:
- Жанр:
- Издательство:Альпина нон-фикшн
- Год:2021
- Город:Москва
- ISBN:978-5-0013-9370-2
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Стюарт Рассел - Совместимость. Как контролировать искусственный интеллект краткое содержание
В своей новаторской книге автор рассказывает, каким образом люди уже научились использовать ИИ, в диапазоне от смертельного автономного оружия до манипуляций нашими предпочтениями, и чему еще смогут его научить. Если это случится и появится сверхчеловеческий ИИ, мы столкнемся с сущностью, намного более могущественной, чем мы сами. Как гарантировать, что человек не окажется в подчинении у сверхинтеллекта?
Для этого, полагает Рассел, искусственный интеллект должен строиться на новых принципах. Машины должны быть скромными и альтруистичными и решать наши задачи, а не свои собственные.
О том, что это за принципы и как их реализовать, читатель узнает из этой книги, которую самые авторитетные издания в мире назвали главной книгой об искусственном интеллекте.
Все, что может предложить цивилизация, является продуктом нашего интеллекта; обретение доступа к существенно превосходящим интеллектуальным возможностям стало бы величайшим событием в истории. Цель этой книги — объяснить, почему оно может стать последним событием цивилизации и как нам исключить такой исход.
Введение понятия полезности — невидимого свойства — для объяснения человеческого поведения посредством математической теории было потрясающим для своего времени. Тем более что, в отличие от денежных сумм, ценность разных ставок и призов с точки зрения полезности недоступна для прямого наблюдения.
Первыми, кто действительно выиграет от появления роботов в доме, станут престарелые и немощные, которым полезный робот может обеспечить определенную степень независимости, недостижимую иными средствами. Даже если робот выполняет ограниченный круг заданий и имеет лишь зачаточное понимание происходящего, он может быть очень полезным.
Очевидно, действия лояльных машин должны будут ограничиваться правилами и запретами, как действия людей ограничиваются законами и социальными нормами. Некоторые специалисты предлагают в качестве решения безусловную ответственность.
Совместимость. Как контролировать искусственный интеллект - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Проблема выключателя составляет ядро проблемы контроля интеллектуальных систем. Если мы не можем выключить машину, потому что она нам не дает это сделать, у нас серьезные проблемы. Если можем — значит, мы сумеем контролировать ее и другими способами.
Оказывается, неопределенность в отношении цели имеет принципиальное значение для обеспечения возможности выключить машину — даже если она более интеллектуальна, чем мы. Мы видели неформальный аргумент в предыдущей главе: по первому принципу полезных машин, Робби интересуют только предпочтения Гарриет, однако, согласно второму принципу, он не знает точно, в чем они заключаются. Он знает, что не хочет сделать что-нибудь неправильно, но не знает что. Гарриет, напротив, знает это (или мы так предполагаем в данном простом случае). Следовательно, если она отключит Робби, то именно для того, чтобы не дать ему сделать что-нибудь не так, и он с удовольствием подчинится.
Чтобы уточнить это рассуждение, нужно построить формальную модель проблемы [263]. Я сделаю ее настолько простой, насколько это возможно (рис. 13).
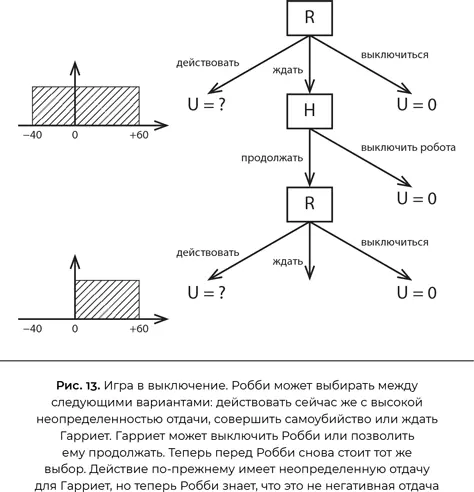
Робби, теперь выступающий в роли персонального помощника Гарриет, делает выбор первым. Он может сразу действовать — к примеру, забронировать Гарриет номер в дорогом отеле. Робот далеко не уверен, что Гарриет понравится отель и цена; допустим, равномерное распределение вероятности его чистой стоимости для Гарриет составляет для Робби от −40 до +60 со средним значением +10. Он также может «выключиться» — без драматичных последствий для себя, просто полностью выйти из процесса бронирования номера в отеле, — ценность этого действия для Гарриет мы оцениваем в ноль. Если бы у него были лишь эти два варианта, он продолжил бы действовать и забронировал номер, что подразумевало бы существенный риск сделать Гарриет несчастной. Однако мы даем Робби третий вариант выбора: изложить свой план, подождать и предоставить Гарриет его выключить. Гарриет может либо выключить робота, либо дать ему возможность продолжить и забронировать номер. Возможно, вы не понимаете, какой в этом смысл, ведь он и сам мог выбрать любой из этих вариантов.
Смысл в том, что выбор Гарриет — отключить Робби или позволить ему продолжить — дает Робби новую информацию о ее предпочтениях. Если она разрешит ему продолжать, то потому, что ценность такого шага для Гарриет является положительной. Теперь Робби верит в равномерное распределение в интервале от 0 до 60 со средним значением 30.
Итак, если оценить первоначальные варианты выбора Робби с этой точки зрения, получаем следующее:
• Выбор «действовать сейчас и забронировать номер» имеет ожидаемую ценность +10.
• Выбор «выключиться» имеет ценность 0.
• Выбор «подождать и позволить Гарриет выключить его» (если она этого хочет) ведет к двум возможным результатам:
— имеется 40 %-ная вероятность (исходя из неуверенности Робби в связи с отелем), что Гарриет он ужасно не понравится и она выключит Робби, ожидаемая ценность 0;
— имеется 60 %-ная вероятность, что Гарриет он понравится и она позволит Робби продолжить, ожидаемая ценность +30.
• Таким образом, решение «подождать» имеет ожидаемую ценность 40 % × 0 + 60 % × 30 = +18, что лучше, чем «действовать сейчас» с ценностью +10.
Итак, Робби имеет положительный стимул позволить себя выключить . Этот стимул напрямую вытекает из неопределенности, имеющейся у Робби в отношении предпочтений Гарриет. Робби сознает существующую вероятность (40 % в данном примере), что он, возможно, близок к действию, которое сделает Гарриет несчастной, и в этом случае быть выключенным предпочтительней, чем продолжать. Если бы Робби уже был уверен в предпочтениях Гарриет, то просто продолжил бы и принял решение (или выключился). Консультация с Гарриет совершенно ничего не принесла бы, поскольку, согласно твердой убежденности Робби, он и так может точно предсказать, какое решение она примет.
На самом деле можно доказать тот же результат для общего случая: пока у Робби нет полной уверенности, что он собирается сделать то же самое, что сделала бы сама Гарриет, он будет отдавать предпочтение варианту, в котором позволяет ей отключить себя [264]. Ее решение снабжает Робби информацией, а информация всегда полезна для совершенствования его решений. Напротив, если Робби уверен в решении Гарриет, то оно не приносит никакой новой информации, следовательно, у Робби нет стимула позволять ей решать.
Напрашивается несколько модификаций этой модели, заслуживающих безотлагательного рассмотрения. Первая состоит в том, чтобы приписать стоимость обращению к Гарриет с тем, чтобы она приняла решение или ответила на вопрос (то есть мы предполагаем, что Робби знает предпочтения Гарриет хотя бы в той мере, чтобы понимать, что ее время ценно). В этом случае Робби менее склонен отвлекать Гарриет, если он почти уверен в ее предпочтениях; чем выше стоимость, тем в большей неопределенности должен находиться Робби, чтобы побеспокоить Гарриет. Так оно должно быть. Если же Гарриет всерьез недовольна, когда ее отвлекают, ей не следует удивляться, что Робби временами делает то, что ей не нравится.
Вторая модификация — допустить некоторую вероятность ошибки человека, а именно, что Гарриет будет иногда выключать Робби, даже когда он предлагает разумное действие, а в некоторых случаях позволять ему продолжать действовать, несмотря на то что его предложение нежелательно. Мы можем включить вероятность человеческой ошибки в математическую модель игры в помощника и найти решение, как уже делали. Как и следовало ожидать, решение показывает, что Робби менее склонен считаться с иррациональной Гарриет, иногда действующей вопреки собственным интересам. Чем более случайно ее поведение, тем более неуверенным Робби должен быть относительно ее предпочтений, чтобы обратиться к ней. Опять-таки это в теории. Например, если Робби — автономный автомобиль, а Гарриет — непослушная двухлетняя пассажирка, Робби не должен позволить Гарриет выключить его посреди автомагистрали.
Эту модель еще многими способами можно расширить или включить в комплексные задачи, связанные с принятием решений [265]. Я уверен, однако, что основная мысль — принципиально важная связь между полезным смиренным поведением машины и ее неопределенностью в отношении человеческих предпочтений — сохранится во всех этих модификациях и усложнениях.
Возможно, читая описание игры в выключение, вы задались важным вопросом (скорее всего, у вас куча важных вопросов, но я собираюсь ответить только на этот): что происходит по мере того, как Робби получает все больше информации о предпочтениях Гарриет и неопределенность для него уменьшается? Значит ли это, что со временем он совершенно перестанет прислушиваться к человеку? Это щекотливый вопрос, на который возможны два ответа: да и да.
Читать дальшеИнтервал:
Закладка:




![Мередит Бруссард - Искусственный интеллект [Пределы возможного] [litres]](/books/1073206/meredit-brussard-iskusstvennyj-intellekt-predely.webp)




