Б Бёрнс - Распределенные системы. Паттерны проектирования

- Название:Распределенные системы. Паттерны проектирования
- Автор:
- Жанр:
- Издательство:Питер
- Год:2019
- ISBN:978-5-4461-0950-0
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Б Бёрнс - Распределенные системы. Паттерны проектирования краткое содержание
Распределенные системы. Паттерны проектирования - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
ского контекста.
Рассмотрим, например, реализацию крупномасштабной много-пользовательской игры. Мир такой игры, скорее всего, слиш-ком велик для хранения на одной машине. Маловероятно, что игроки, находящиеся в этом мире далеко друг от друга, будут как-то взаимодействовать. Следовательно, игровой мир может быть шардирован на несколько машин. Ключом шардирующей функции в этом случае будет местоположение пользователя на игровой карте. Таким образом, все игроки, находящиеся 120Часть II. Паттерны проектирования обслуживающих систем в одной части карты, будут обслуживаться одной и той же группой серверов.
Системы с «горячим»
шардированием
В идеале нагрузка на шардированный кэш должна быть равно-мерной, но во многих случаях это не так. За счет этого появ-ляются «горячие» шарды, поскольку естественные закономер-ности в распределении нагрузки приводят к тому, что на одни шарды приходится больше трафика, чем на другие. Рассмотрим, например, шардированный кэш пользователь-ских фотографий. Когда какая-то фотография приобретает «вирусную» популярность, на нее приходится несоразмерно больше трафика, чем на другие, и шард кэша, содержащий эту фотографию, становится «горячим». Когда в реплициро-ванном шардированном кэше возникает такая ситуация, этот шард можно масштабировать в соответствии с выросшей нагрузкой.
Если для шардов настроено автоматическое масштабирование, можно в зависимости от роста или падения нагрузки динами-чески выделять и освобождать ресурсы, предназначенные для реплицированных шардов. Данный процесс проиллюстриро-ван на рис. 6.3.
Сначала все три шарда обрабатывают одинаковое количество трафика. Затем трафик перераспределяется таким образом, что на шард А приходится в четыре раза больше трафика, чем на шарды Б и В. Система с «горячим» шардированием пере-мещает шард Б на машину с шардом В, а шард А реплицирует на вторую машину. Реплики теперь делят трафик поровну. Глава 6. Шардированные сервисы 121
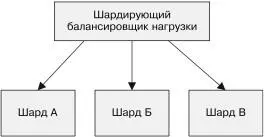
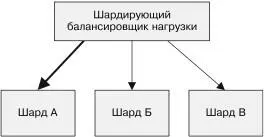
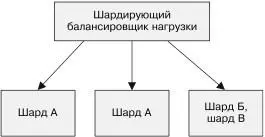
Рис. 6.3. Пример системы с «горячим» шардированием. Сначала шардынагружены равномерно, но когда нагрузка на шард A увеличивается, он реплицируется на две машины, а шарды Б и B попадают на одну
7 Паттерн Scatter/GatherДо сих пор мы изучали реплицированные системы, которые масштабируются по количеству обрабатываемых в секунду запросов (реплицированные сервисы без внутреннего состоя-
ния) либо по объему обрабатываемых данных (шардирован-ные данные). В этой главе описывается паттерн Scatter/Gather , в котором репликация используется для масштабирования по времени. В частности, паттерн Scatter/Gather позволяет добить-
ся параллелизма в обработке запросов, за счет чего вы сможете обслуживать их намного быстрее, чем при последовательной обработке.
Подобно паттернам реплицированных и шардированных си-стем, паттерн Scatter/Gather — древовидный паттерн, в котором корневой узел распределяет запросы, а терминальные узлы их обрабатывают. Однако, в отличие от реплицированных и шар-
дированных систем, запросы в Scatter/Gather-системах рас-пределяются между всеми репликами сервиса. Каждая реплика делает небольшую часть работы и возвращает результат кор-Глава 7. Паттерн Scatter/Gather 123
невому узлу. Корневой узел затем собирает частичные ответы в один общий ответ, который и возвращается клиенту. Паттерн Scatter/Gather схематически изображен на рис. 7.1.
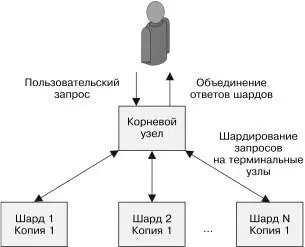
Рис. 7.1. Паттерн Scatter/Gather
Он весьма полезен, если обработка запроса подразумевает большое количество независимых действий. Паттерн Scatter/ Gather может рассматриваться как шардирование вычислений, необходимых для обработки запроса, в противовес шардирова-нию данных (шардирование данных может быть частью этого процесса).
Scatter/Gather с распределением нагрузки корневым узлом
В простейшем варианте паттерна Scatter/Gather все терми-нальные узлы идентичны, а работа распределяется между ними для ускорения обработки запроса. Этот паттерн напоминает 124Часть II. Паттерны проектирования обслуживающих систем
решение «чрезвычайно параллельной» задачи. Задачу можно разбить на множество мелких фрагментов, результаты решения которых можно склеить, чтобы получить полный результат. Разберем его принцип работы на конкретном примере. Пред-ставьте, что вам нужно обслужить запрос R , который на одном ядре выполняется за одну минуту и выдает ответ А. При созда-нии многопоточного приложения мы можем распараллелить обработку запроса на несколько ядер. На 30-ядерном процес-соре (обычно ядер 32, но для ровного счета возьмем 30) время обработки запроса снижается до 2 секунд (60 секунд машинного времени, разделенные на 30 потоков, дают 2 секунды). Но даже 2 секунды — это достаточно долго. Достижение полного парал-лелизма в рамках одного процесса практически невозможно, по-скольку пропускная способность памяти, сетевого подключения или диска становится узким местом. Вместо распараллеливания приложения на несколько ядер одной машины можно исполь-зовать паттерн Scatter/Gather, чтобы распараллелить запросы на несколько процессов, работающих на нескольких машинах. Таким образом, мы можем сократить среднее время обработки запросов, поскольку нас перестает ограничивать количество ядер процессора на одной машине.
Узким местом остается процессор, поскольку пропускная спо-собность памяти, сетевого интерфейса и жесткого диска рас-пределена на несколько машин. Кроме того, поскольку каждая машина в дереве Scatter/Gather способна обработать все за-просы, корневой узел дерева может динамически распределять нагрузку между узлами в зависимости от времени их реакции. Если по какой-то причине некоторый терминальный узел от-вечает медленнее остальных (например, на его ресурсы посягает жадный процесс-сосед), то корневой узел может динамически перераспределить нагрузку, чтобы обеспечить необходимую скорость реакции.
Глава 7. Паттерн Scatter/Gather 125
Практикум. Распределенный поиск в документах
Рассмотрим паттерн Scatter/Gather в действии на примере задачи поиска всех документов, содержащих слова «кот» и «собака», в большой базе документов. Можно открывать все документы подряд и искать в них соответствия образцу поиска, затем возвра-щать пользователю набор документов, в которых есть оба слова. Как вы можете себе представить, этот процесс довольно дли-телен, поскольку для каждого запроса необходимо открывать и считывать большое количество файлов. Чтобы ускорить об-работку, документы можно проиндексировать . Индекс, по сути, представляет собой ассоциативный массив, ключами в котором выступают отдельные слова, а значениями — списки докумен-тов, содержащих данное слово.
Читать дальшеИнтервал:
Закладка:


