Тимур Машнин - Технология хранения и обработки больших данных Hadoop

- Название:Технология хранения и обработки больших данных Hadoop
- Автор:
- Жанр:
- Издательство:неизвестно
- Год:2021
- ISBN:978-5-532-96881-3
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Тимур Машнин - Технология хранения и обработки больших данных Hadoop краткое содержание
Технология хранения и обработки больших данных Hadoop - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
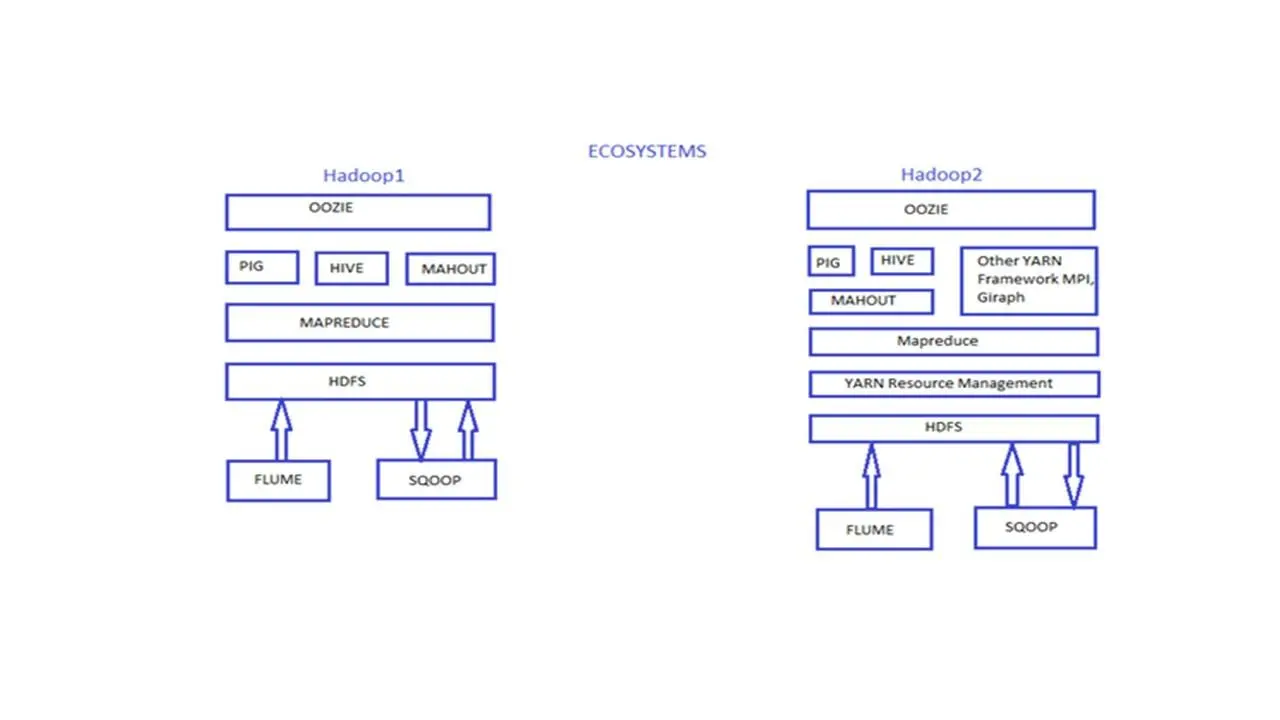
Hadoop версии 1 содержал компоненты HDFS и Map Reduce.
И Hadoop версии 1 разрабатывался только для выполнения заданий MapReduce.
А Hadoop версии 2 уже содержит компоненты HDFS и YARN/Map Reduce версии 2.
В классическом Map Reduce, когда мастер узел перестает работать, тогда все его узлы slave автоматически перестают работать.
И мы должны перезапустить весь кластер и заново начать выполнять работу.
Это единственный сценарий, когда выполнение работы может прерваться, и это создает единственную точку отказа.
Компонент YARN или Yet Another Resource Negotiator решает эту проблему благодаря своей архитектуре.
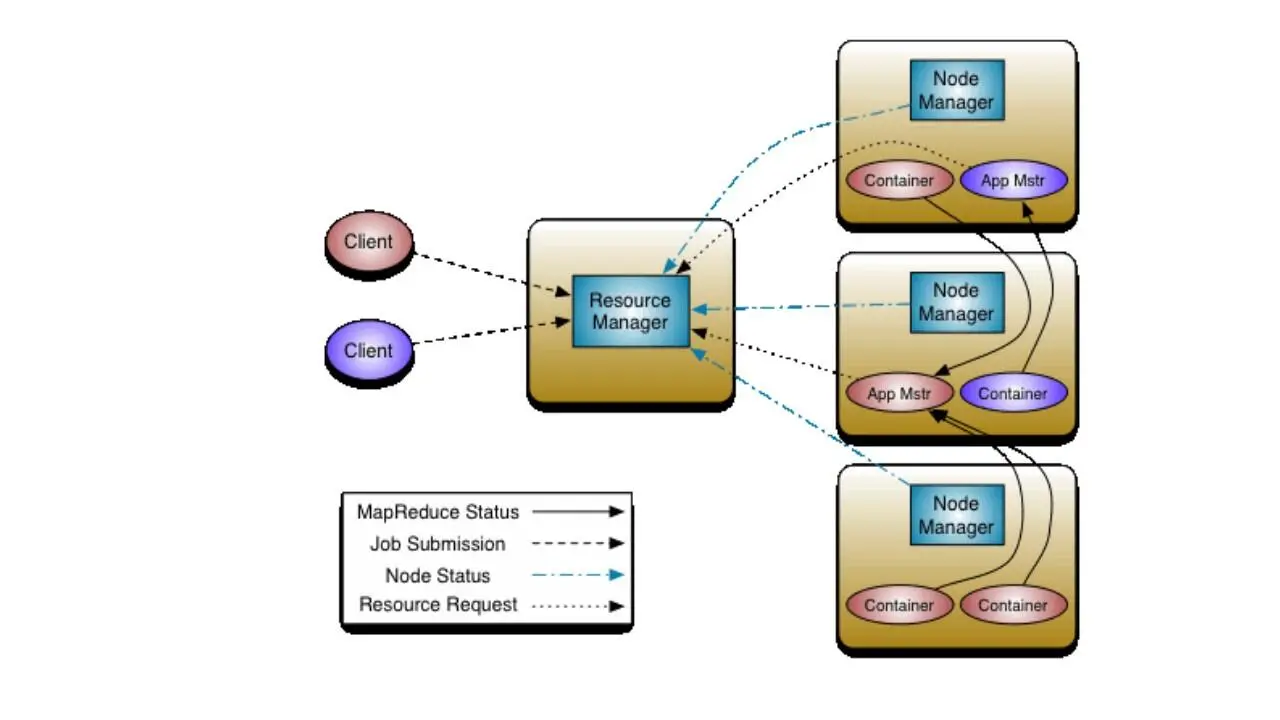
YARN основывается на концепции нескольких мастер узлов и нескольких подчиненных slave узлов, и если один мастер узел выйдет из строя, тогда другой мастер узел возобновит процесс и продолжит выполнение.
Классический Map Reduce отвечает как за управление ресурсами, так и за обработку данных.
В Hadoop версии 2, YARN разделяет функций управления ресурсами и планирования/мониторинга заданий на отдельные демоны.
YARN – это универсальная платформа для запуска любого распределенного приложения, и здесь Map Reduce – это распределенное приложение, которое работает поверх YARN.
Таким образом, YARN отвечает за управление ресурсами, то есть решает, какая работа будет выполняться и какой системой.
Тогда как Map Reduce является фреймворком программирования, который отвечает за то, как выполнить конкретную работу, используя два компонента mapper и reducer.
YARN отделяет компоненты управления ресурсами от компонентов обработки, и YARN не сводится только к MapReduce.
Диспетчер ресурсов resource manager YARN оптимизирует использование кластера и поддерживает другие рабочие процессы, кроме Map Reduce.
Поэтому здесь мы можем добавлять дополнительные программные модели, такие как обработка графов или итеративное моделирование, которые могут обрабатывать данные, используя те же кластеры и общие ресурсы.
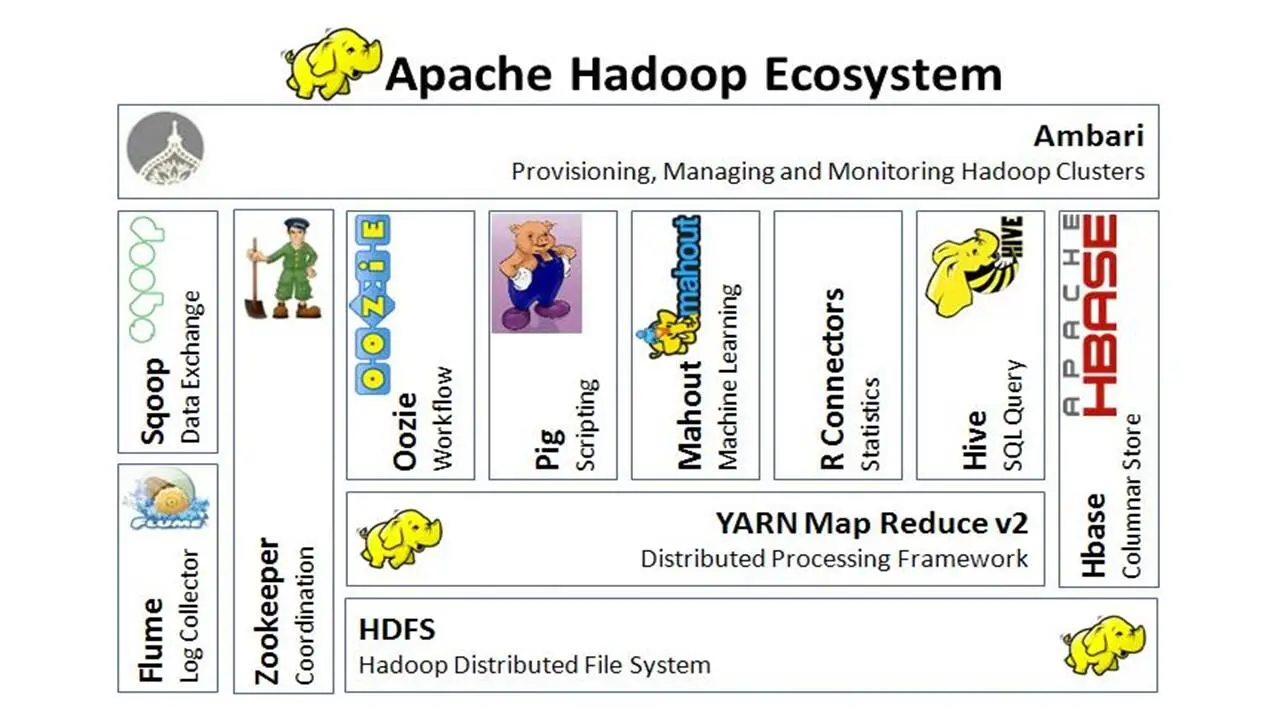
Поверх HDFS и Yarn могут работать множество компонентов, и эта архитектура также развивалась с течением времени.
Давайте посмотрим на историю и посмотрим, как вся эта экосистема Hadoop развивалась и росла со временем.
Как вы можете заметить, у многих из этих приложений смешные имена.
Как мы можем понять весь этот зоопарк, и как мы можем понять, что делает каждое из этих приложений?
Проект Hadoop возник из концепции Google MapReduce и идеи о том, как можно обрабатывать очень большие объемы данных.
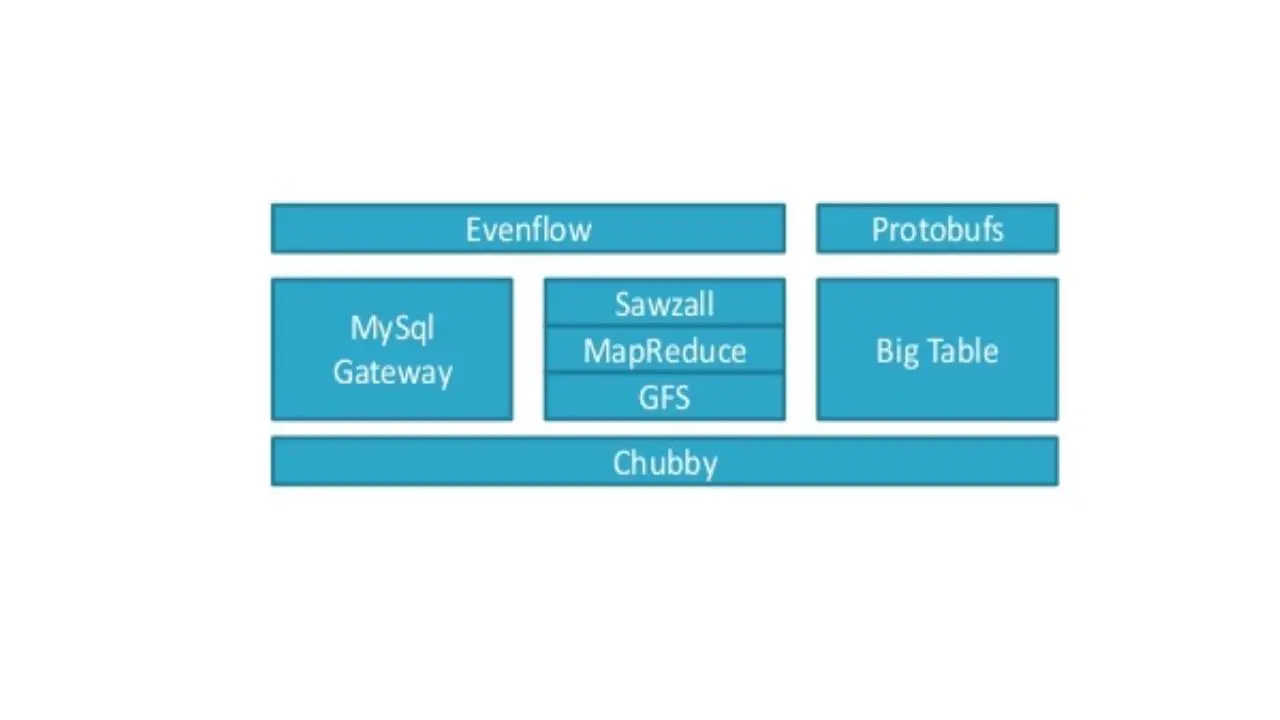
Здесь показан стек Google Big Data.
И он начинается с файловой системы Google GFS.
В Google подумали, что будет хорошей идеей использовать большое количество распределенного дешевого хранилища, и попытаться разместить там много данных.
И придумать какой-то фреймворк, который позволил бы обрабатывать все эти данные.
Таким образом, у Google появился свой оригинальный MapReduce, и они хранили и обрабатывали большие объемы данных.
Затем в Google сказали, что это действительно здорово, но нам бы очень хотелось иметь доступ к этим данным и обращаться к ним на языке, похожем на SQL.
Поэтому они создали шлюз MySQL Gateway, чтобы адаптировать данные в кластере MapReduce и иметь возможность запрашивать эти данных.
Затем они поняли, что им нужен специальный язык высокого уровня для доступа к MapReduce в кластере и отправки работы.
Так появился Sawzall.
Затем появился Evenflow и позволил связывать воедино сложные рабочие нагрузки и координировать сервисы и события.
Затем появился Дремель. Dremel – это хранилище и менеджер метаданных, который позволяет управлять данными и обрабатывать очень большой объем неструктурированных данных.
И затем, конечно, вам нужно что-то, чтобы координировать все это между собой.
Так появился Chubby в качестве системы координации, которая управляет всеми продуктами в этой экосистеме, обрабатывающей большие объемы данных.

Здесь показан стек Facebook Big Data.
И мы видим, что стек Facebook выглядит очень похожим.
Здесь есть Zookeeper, аналог Chubby, цель которого хранение и управление конфигурациями систем.
Здесь есть HBase, и таблицы в HBase служат входом и выходом для работы MapReduce.
И здесь Hive и Databee, которые обеспечивает SQL запросы.
И есть Scribe, который используется для агрегации лог данных, передаваемых в режиме реального времени с большого количества серверов.
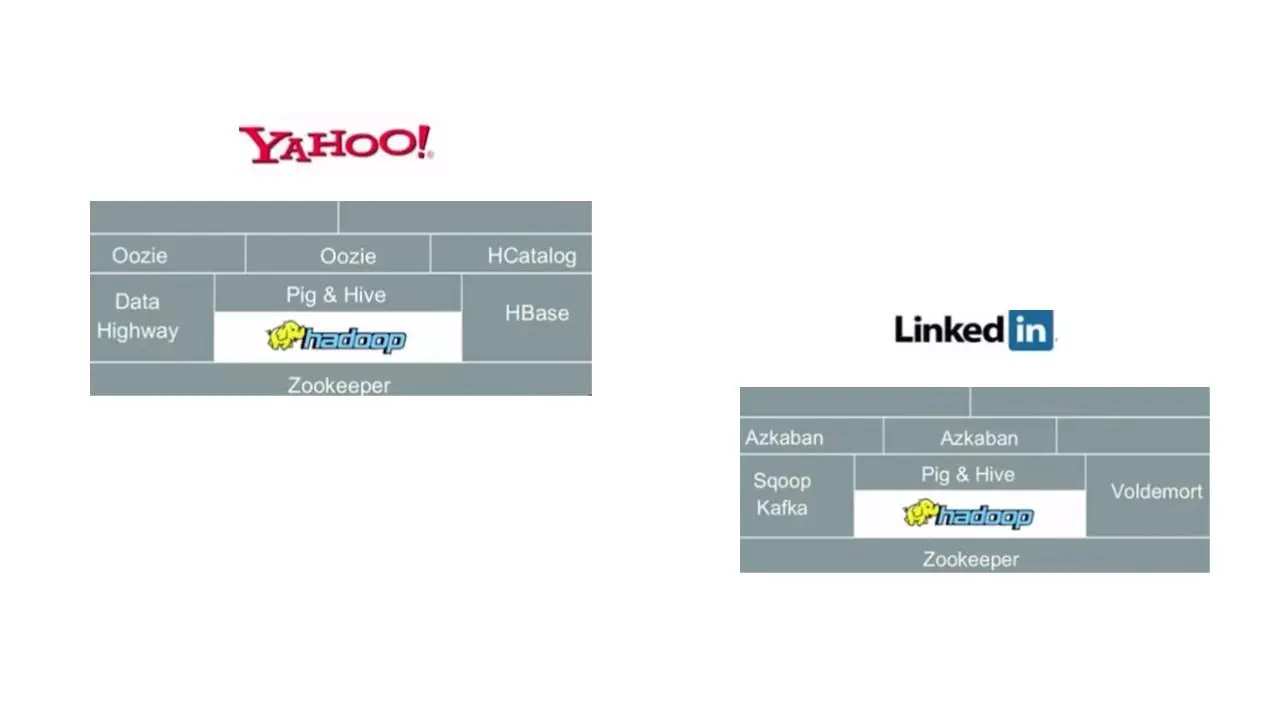
Затем, если мы посмотрим на стек Yahoo, вы увидите, что они используют те же компоненты, некоторые из них с другими именами, но для тех же целей.
LinkedIn также имеет свою версию этого стека.
И опять же, вы можете видеть, что здесь те же компоненты, некоторые из которых имеют свои реализации.
Таким образом, вы можете видеть, что из всех этих стеков возникает шаблон, который используют разные организации.
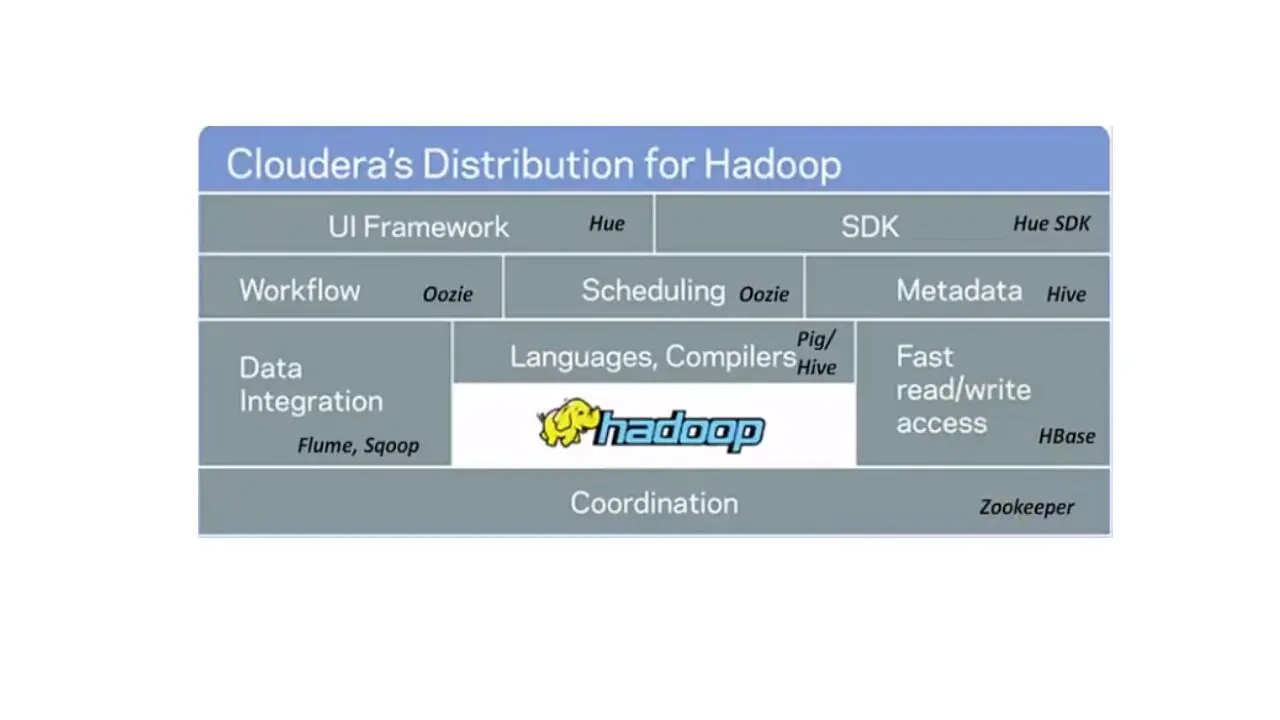
И здесь показан Hadoop стек CDH – Cloudera's distribution for Hadoop компании Cloudera.
Cloudera – это американская компания, разработчик дистрибутивов Apache Hadoop и ряда программных продуктов экосистемы Hadoop.
В этом стеке у нас есть Sqoop, инструмент, предназначенный для эффективной передачи больших данных между Hadoop и структурированными хранилищами данных, такими как реляционные базы данных.
И есть Flume – распределенный сервис для агрегирования больших объемов лог данных.
Здесь используется HBase для случайной записи и чтения данных, хранящихся в HDFS.
Oozie используется в качестве движка координации и рабочего процесса.
И Pig и Hive обеспечивают языки высокого уровня запросов данных.
И наконец здесь используется Zookeeper в качестве службы координации в основе этого стека.
И мы можем скачать и запустить виртуальную машину Cloudera, которая позволяет запускать все эти различные сервисы и узнавать, как они работают, без необходимости установки сервера.
Но сначала давайте поговорим о различных инструментах, которые мы будем использовать поверх платформы Hadoop.
С развитием вычислительной техники стало возможным управлять огромными объемами данных, которые раньше мы могли обрабатывать только на суперкомпьютерах.
Настоящий прорыв произошел, когда такие компании, как Yahoo, Google и Facebook пришли к пониманию, что им нужно что-то сделать, чтобы обрабатывать и монетизировать эти огромные объемы данных, которые они собирают.
Читать дальшеИнтервал:
Закладка: