Тимур Машнин - Технология хранения и обработки больших данных Hadoop

- Название:Технология хранения и обработки больших данных Hadoop
- Автор:
- Жанр:
- Издательство:неизвестно
- Год:2021
- ISBN:978-5-532-96881-3
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Тимур Машнин - Технология хранения и обработки больших данных Hadoop краткое содержание
Технология хранения и обработки больших данных Hadoop - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
В результате были созданы различные инструменты и собраны стеки Big Data.
И давайте начнем обсуждение этих инструментов с Apache Sqoop.
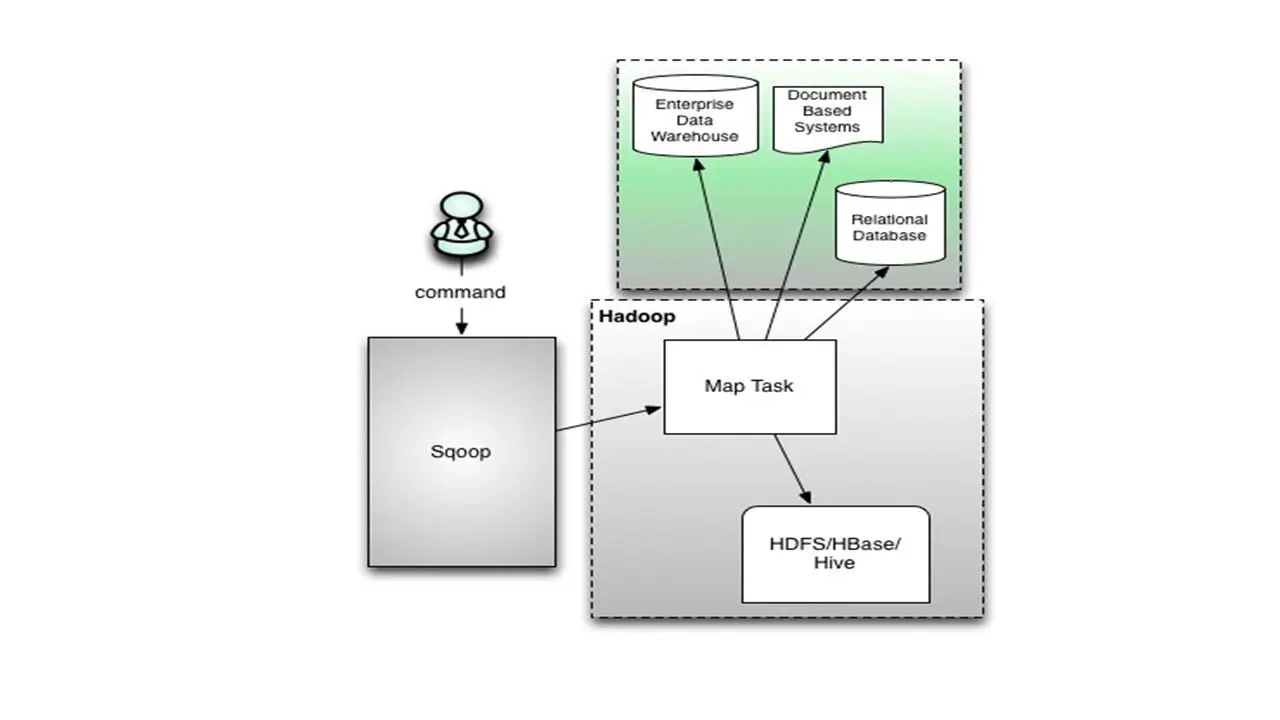
Sqoop означает SQL для Hadoop.
Это простой инструмент командной строки, который позволяет импортировать отдельные таблицы или целые базы данных в систему HDFS.
И этот инструмент генерирует классы Java, чтобы можно было взаимодействовать с данными, которые мы импортировали.
С этим инструментом Вы можете работать с данными базы данных SQL в среде Hadoop и использовать Map Reduce для запуска заданий с этими данными.
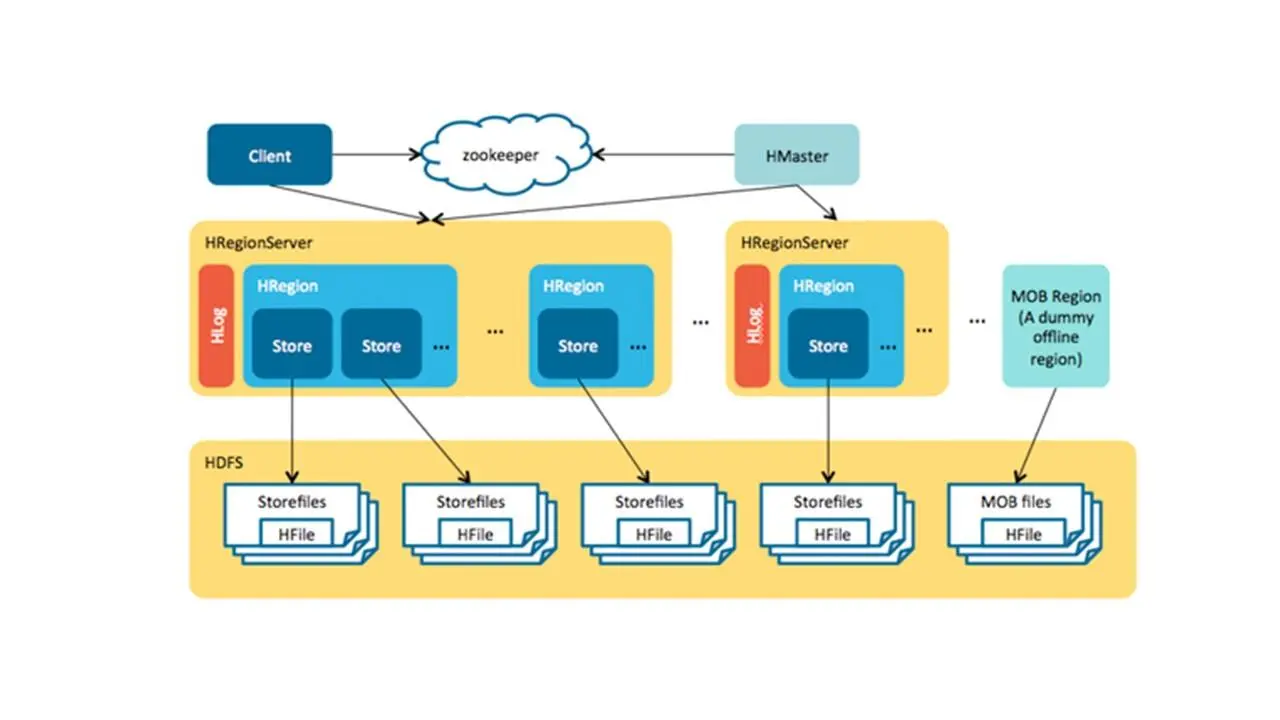
Следующий инструмент – это Hbase.
Hbase является ключевым компонентом стека Hadoop, так как он предназначен для приложений, которым требуется быстрый произвольный доступ к большому набору данных.
И Hbase основывается на Google Big Table и может обрабатывать большие таблицы данных, объединяющие миллиарды строк и миллионы столбцов.
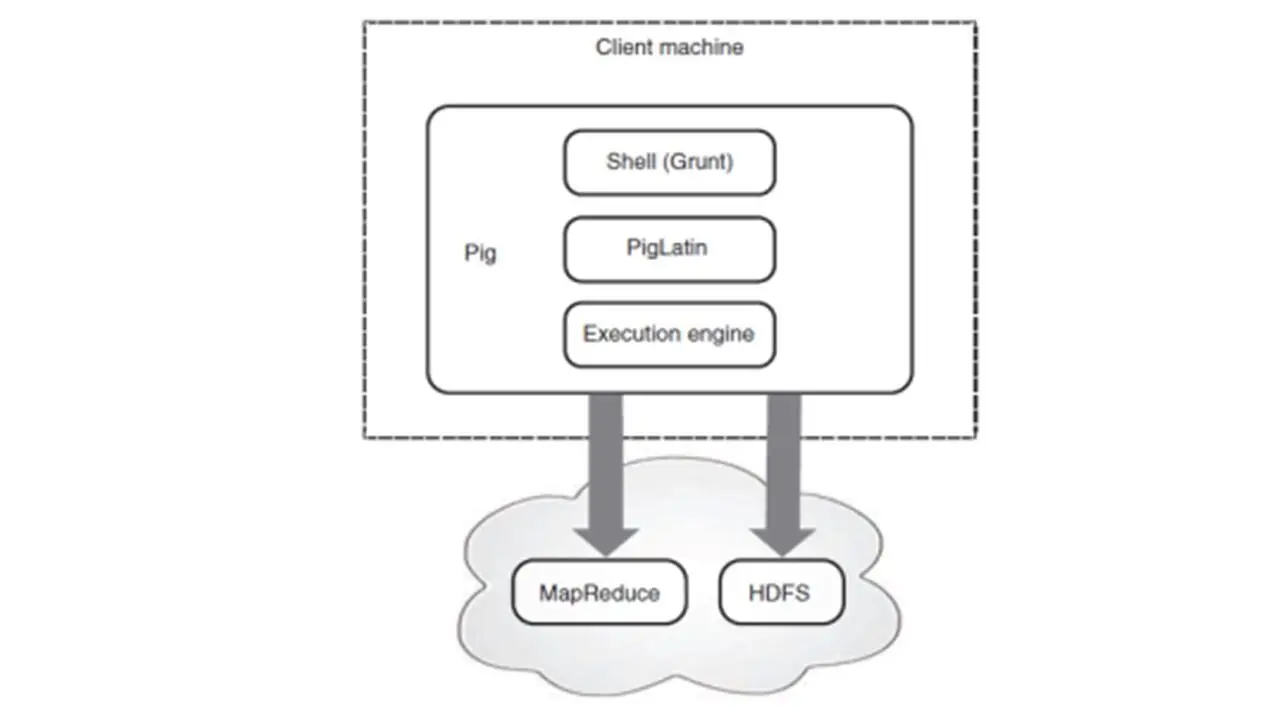
Pig – это язык скриптов, это платформа высокого уровня для создания программ MapReduce с использованием Hadoop.
Этот язык называется Pig Latin, и он предназначен для задач анализа данных как потоков данных.
Pig самодостаточен, и вы можете выполнят все необходимые манипуляции в Hadoop, просто используя pig.
Кроме того, в pig, вы можете использовать код на разных языках, таких как JRuby, JPython и Java.
И наоборот, вы можете выполнять скрипты PIG на других языках.
Таким образом, в результате вы можете использовать PIG в качестве компонента для создания гораздо более крупных и более сложных приложений.
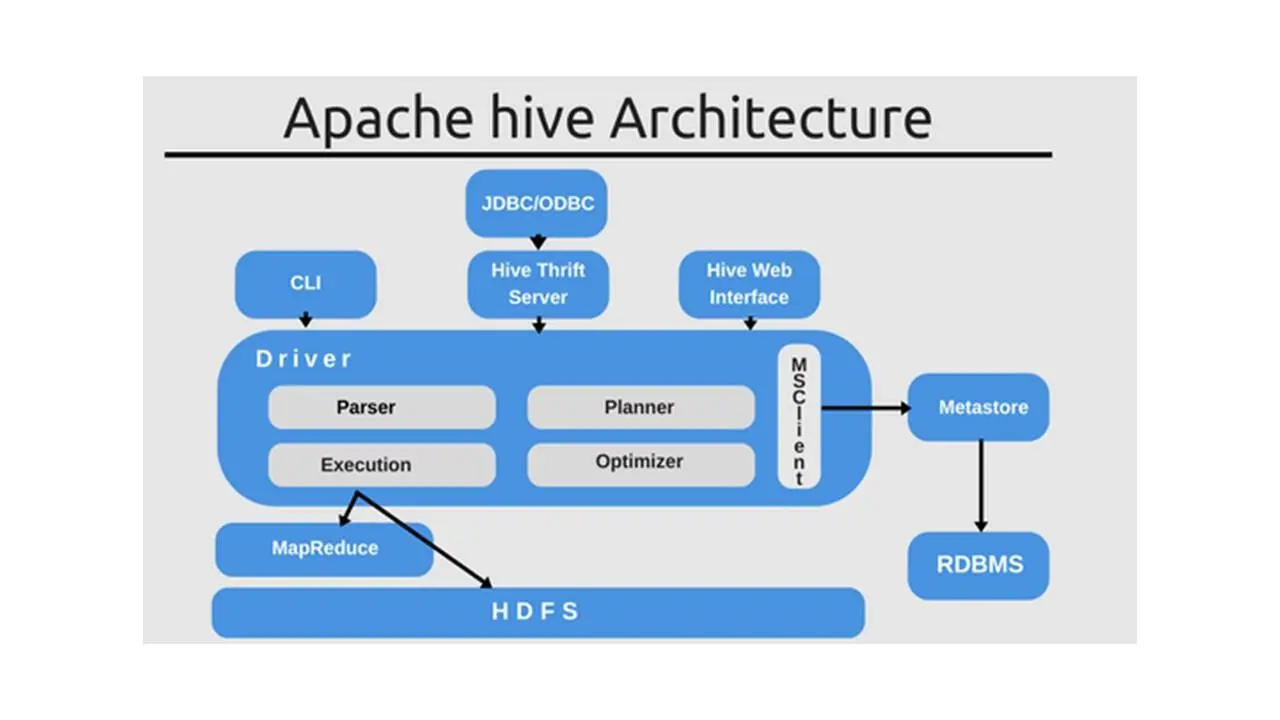
Программное обеспечение Apache Hive облегчает запросы и управление большими наборами данных, которые находятся в распределенном хранилище файлов.
Hive предоставляет механизм для проектирования структуры поверх этих данных и позволяет использовать SQL-подобные запросы для доступа к данным, которые хранятся в этом хранилище данных.
И этот язык запросов называется Hive QL.

Oozie – это система планирования рабочих процессов, которая управляет всеми нашими заданиями Hadoop.
Задания рабочего процесса Oozie – это то, что мы называем DAG или Directed Graphs.
Задания координатора Oozie – это периодические задания рабочего процесса Oozie, которые запускаются по частоте или доступности данных.
Oozie интегрирован с остальной частью стека Hadoop и может поддерживать сразу несколько различных заданий Hadoop.
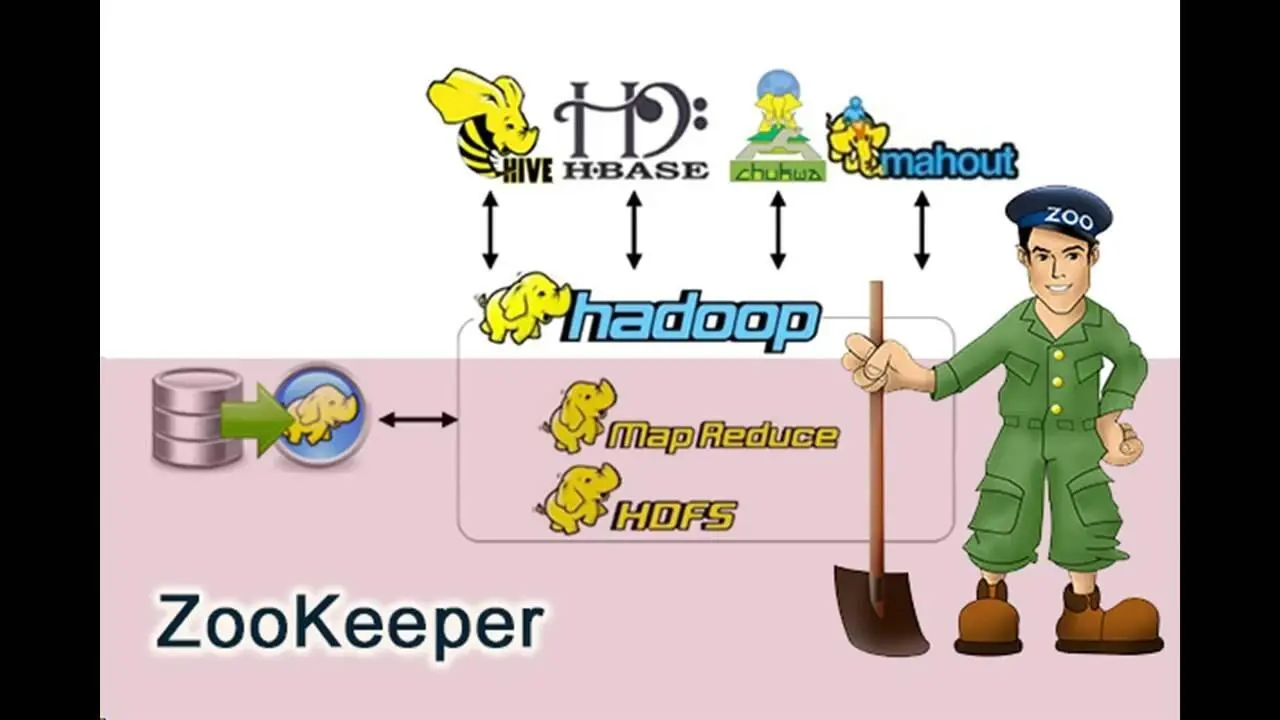
Следующий инструмент – это Zookeeper.
У нас есть большой зоопарк сумасшедших диких животных, и мы должны держать их вместе и как-то их организовывать.
Это как раз то, что делает Zookeeper.
Он предоставляет операционные сервисы для кластера Hadoop.
Он предоставляет службу распределенной конфигурации и службу синхронизации, поэтому он может синхронизировать все эти задания и реестр имен для всей распределенной системы.
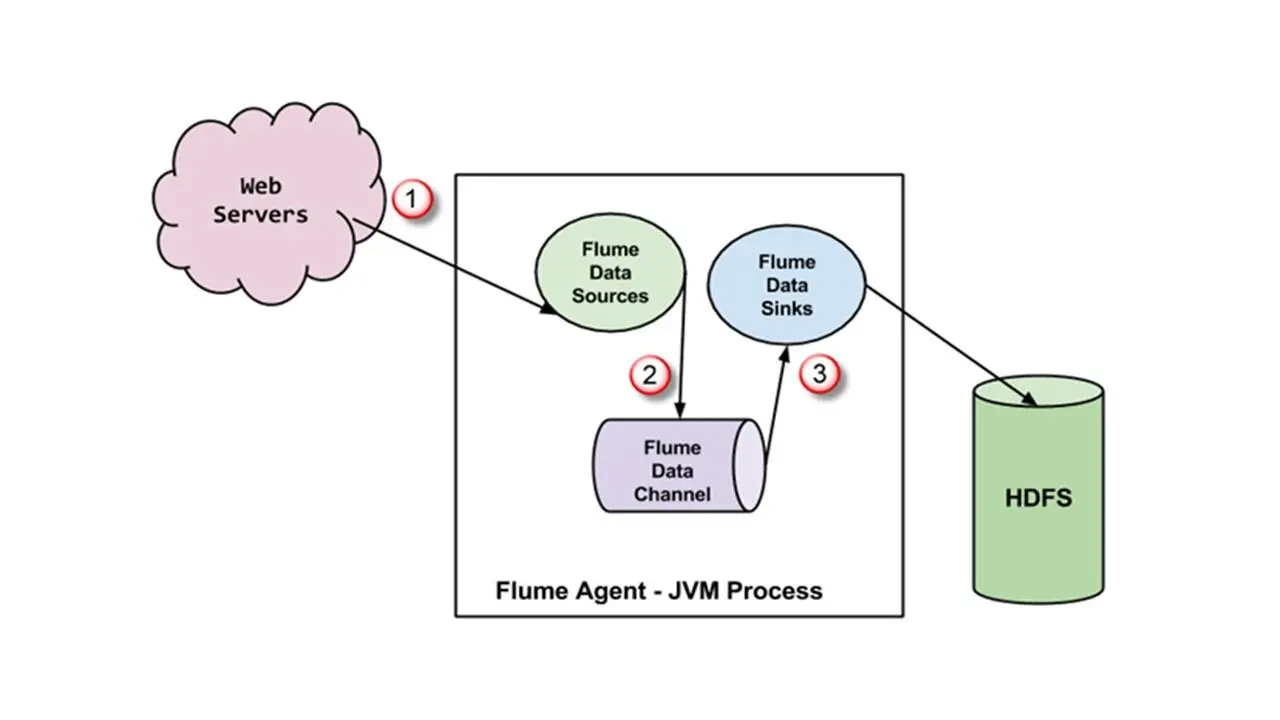
Инструмент Flume – это распределенный сервис для эффективного сбора и перемещения больших объемов данных.
Он имеет простую и очень гибкую архитектуру, основанную на потоковых данных.
И Flume использует простую расширяемую модель данных, которая позволяет применять различные виды аналитических онлайн приложений.
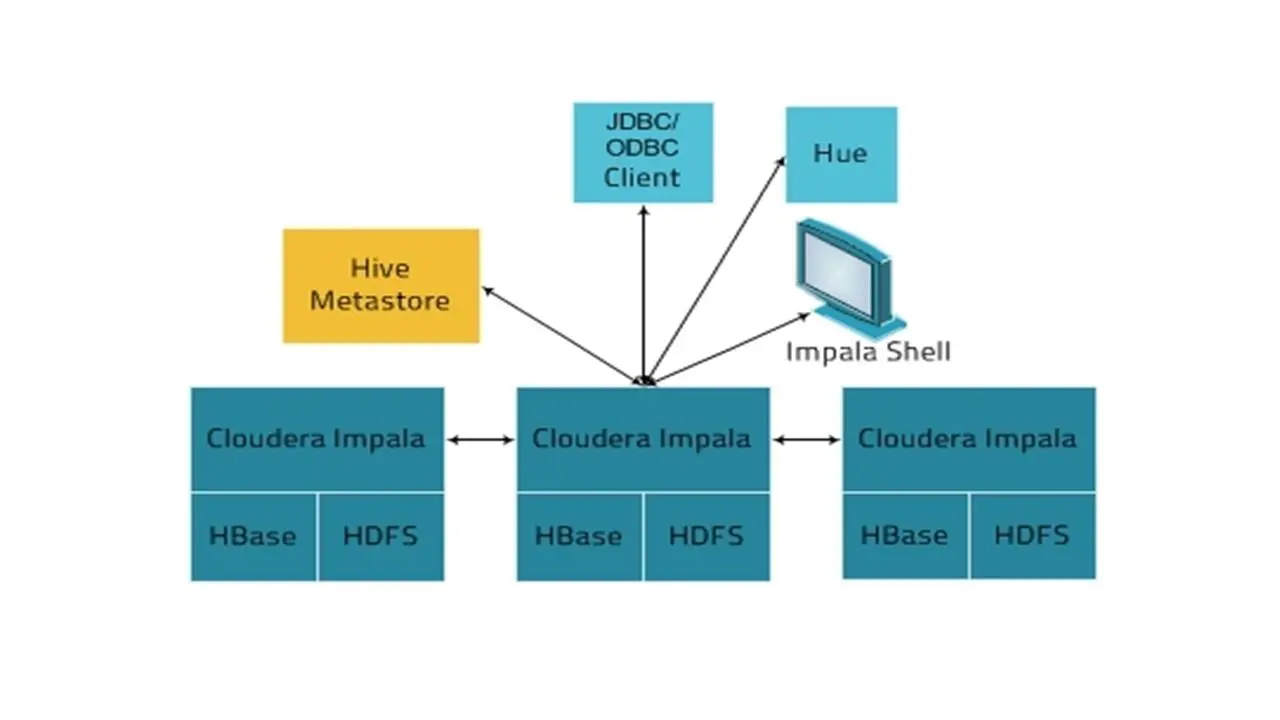
Еще один инструмент – это Impala, который был разработан специально для Cloudera, и это механизм запросов, работающий поверх Hadoop.
Impala привносит в Hadoop технологию масштабируемой параллельной базы данных.
И позволяет пользователям отправлять запросы с малыми задержками к данным, хранящимся в HTFS или Hbase, не сопровождая это масштабными перемещениями и манипулированием данными.
Impala интегрирована с Hadoop и работает в той же экосистеме.
Это обеспечивает масштабируемую технологию параллельных баз данных на вершине Hadoop.
И это позволяет отправлять SQL-подобные запросы с гораздо более высокими скоростями и с гораздо меньшей задержкой.

Еще один дополнительный компонент, это Spark.
Хотя Hadoop широко используется для анализа распределенных данных, в настоящее время существует ряд альтернатив, которые предоставляют некоторые интересные преимущества по сравнению с традиционной платформой Hadoop.
И Spark – это одна из таких альтернатив.
Apache Spark – это фреймворк экосистемы Hadoop с открытым исходным кодом для реализации распределённой обработки данных.
В отличие от классического обработчика Hadoop, реализующего двухуровневую концепцию MapReduce с дисковым хранилищем, Spark использует специализированные примитивы для рекуррентной обработки в оперативной памяти, благодаря чему позволяет получать значительный выигрыш в скорости работы для некоторых классов задач, в частности, возможность многократного доступа к загруженным в память пользовательским данным делает библиотеку привлекательной для алгоритмов машинного обучения.
И Spark поддерживает язык Scala, и предоставляет уникальную среду для обработки данных.
Для управления кластерами Spark поддерживает автономные нативные кластеры Spark, или вы можете запустить Spark поверх Hadoop Yarn.
Что касается распределенного хранилища, Spark может взаимодействовать с любой системой хранения, включая HDFS, Amazon S3 или с каким-либо другим пользовательским решением.
Cloudera QuickStart VM

Для начала работы нам нужно скачать виртуальную машину Cloudera, позволяющую ознакомиться со стеком Cloudera Hadoop.
После скачивания и распаковки архива, запустим виртуальную машину.
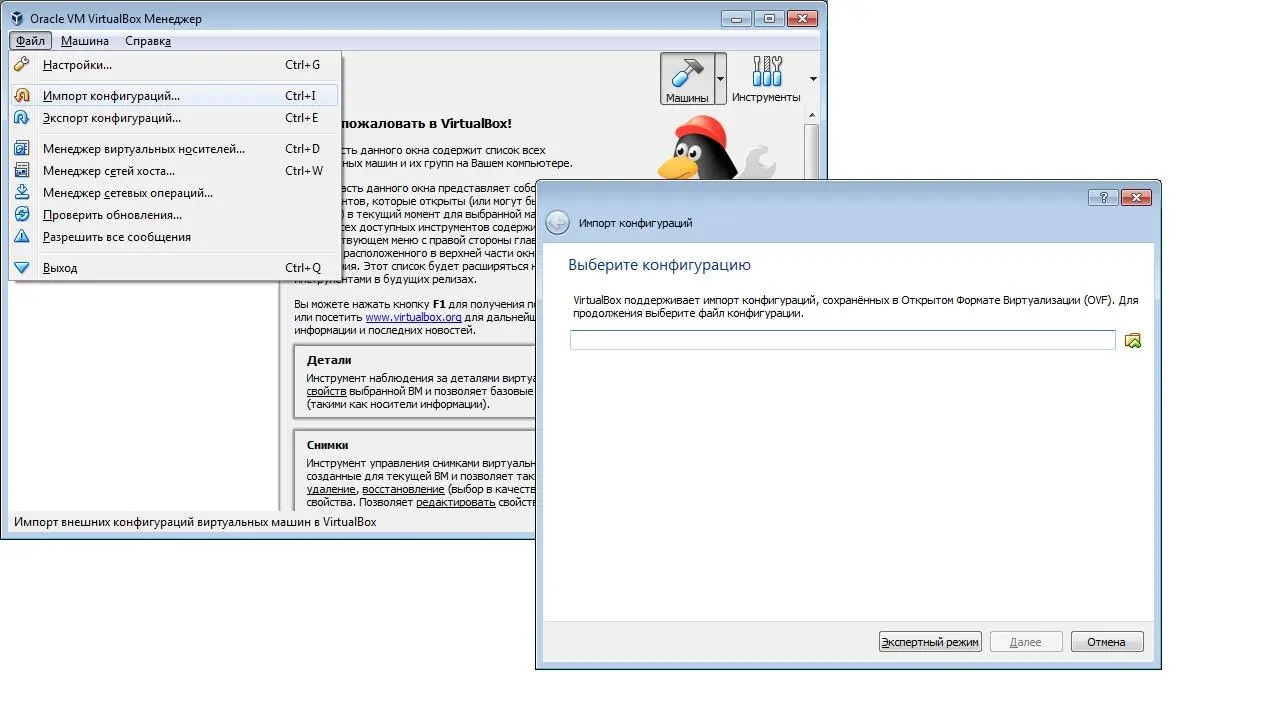
Для этого в VirtualBox импортируем скачанную конфигурацию ovf.
Читать дальшеИнтервал:
Закладка: