Тимур Машнин - Введение в облачные и распределенные информационные системы

- Название:Введение в облачные и распределенные информационные системы
- Автор:
- Жанр:
- Издательство:неизвестно
- Год:неизвестен
- ISBN:9785005303110
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Тимур Машнин - Введение в облачные и распределенные информационные системы краткое содержание
Введение в облачные и распределенные информационные системы - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Асинхронность отличает распределенные системы от параллельных систем.
Параллельные системы включают в себя многопроцессорные системы и суперкомпьютеры.
Но, по сути, при этом очень большое количество процессоров используют одну и ту же материнскую плату.
Они взаимодействуют друг с другом по тесно связанной сети, и все они имеют синхронизированные циклы или часы.
И этим параллельная система отличается от распределенной системы.
Таким образом, процесс, это автономная работающая программа, которая может иметь несколько потоков.
Процесс выполняет множество задач, которые могут быть распределены по потокам, и которые могут выполняться на одном или нескольких процессорах.
В распределенных системах, эти процессы работают на разных устройствах, системные времена которых не синхронизированы.
В параллельных системах каждый поток процесса выполняется на своем процессоре или ядре процессора, и задачи таким образом выполняются параллельно.
При этом процессоры имеют синхронизированное системное время.
MapReduce

MapReduce – это модель распределённых вычислений, представленная компанией Google.
И эта модель используется для параллельных вычислений над очень большими наборами данных в компьютерных кластерах.
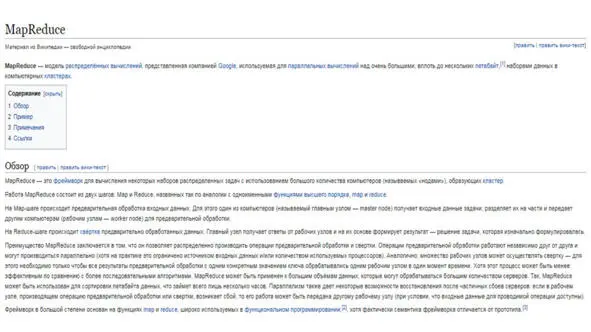
Термины map и reduce, которые составляют термин MapReduce, заимствованы из функциональных языков, таких как Lisp.
Например, вы хотите вычислить сумму квадратов.

Функция map – функция, которая может быть применена к любому из этих целых чисел и вычисляет квадрат каждого числа.
Так что map здесь является мета функцией, которая обрабатывает каждую запись.
Это первая часть.
Вторая часть – это функция reduce, которая получает на вход список соответствующих квадратов целых чисел и просто суммирует их.
reduce здесь снова является мета функцией, которая применяется к группе записей.
Предположим, что у нас есть текст, и нам нужно произвести подсчет для каждого слова, которое появляется в этом наборе данных.
Как сделать это? Особенно, когда вы имеете дело с большими объемами данных?
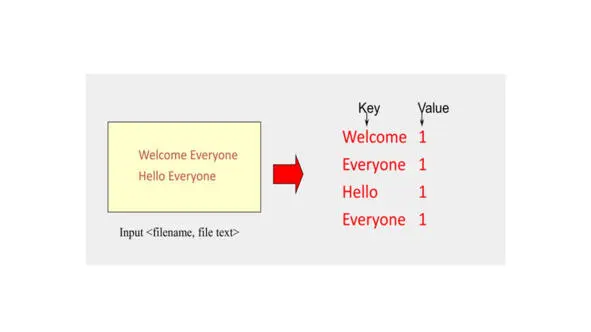
Здесь и появляется парадигма MapReduce.
Таким образом, map как задача или как объект обрабатывает отдельные записи для генерации промежуточных ключей / значений.
Если это простой файл, можно пройти через эти записи последовательно.
Но вы можете сделать этот процесс параллельным, особенно когда у вас большой набор данных.
Вы можете параллельно обрабатывать отдельные записи для генерации промежуточных пар ключ / значение.
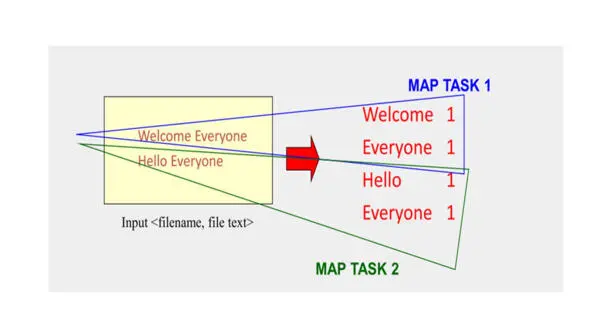
Если y вас очень большой набор данных, вы можете разделить свой входной набор данных.
И назначить задачу map для каждого куска данных.
И соответствующий результат будет таким же, как если бы у вас была только одна задача map.
И это поможет существенно ускорить процесс.
После результата map, у нас есть ввод для reduce.
Reduce производит слияние промежуточных результатов в один результат, исходя из ключей значений.
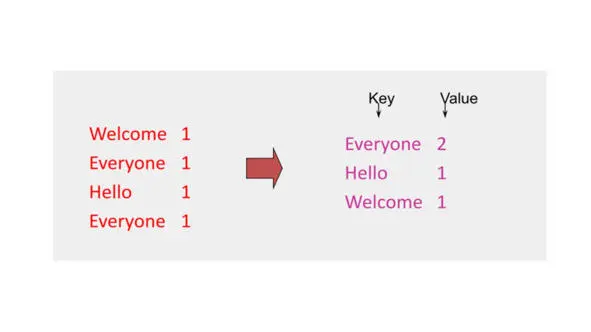
Как распараллелить эту фазу reduce?
Фаза reduce не обрабатывает эти записи независимо, другими словами, одна запись и другая запись должны обрабатываться вместе, так как они имеют одинаковые ключи.
Таким образом, единственный способ распараллелить этот процесс, это разделить задачи reduce по ключам.
Существуют разные способы разбиения ключей на задачи.
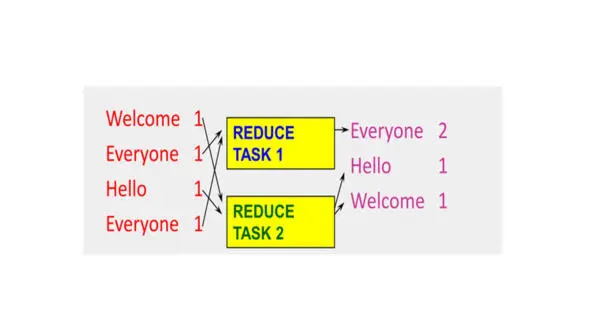
Один из способов разделения – это использование хэшей.
Вы берете ключ, и обрабатываете его хеш-функцией.
Затем делите хэш на количество задач reduce и в остатке от деления получаете к какой reduce задаче данный ключ относится.
Например, если есть 10 задач reduce, эта операция вернет значения от 0 до 9 для всех ключей.
У парадигмы MapReduce есть реализация с открытым исходным кодом Apache Hadoop, это набор утилит, библиотек и фреймворк для разработки и выполнения распределённых программ, работающих на кластерах из сотен и тысяч узлов.
Итак, вот что такое Map в Hadoop.

У вас есть MapClass, который расширяет базовый класс и реализует интерфейс.
И главная функция здесь – это map.
Эта функция принимает значение, которое в этом случае является текстом.
Значением может быть одна строка текста во входном файле.
Эта строка разбивается на слова.
И для каждого слова вы выводите пару ключ-значение.
Таким образом это промежуточная выходная пара ключ-значение.
Здесь у нас есть ReduceClass, который имеет функцию reduce, получающую на вход ключ и значения, потому что у вас могут быть много значений, связанных с данным ключом.

Эта функция reduce вызывается для каждого ключа, который относится к данной задаче reduce.
Таким образом, reduce будет проходить через все значения и суммировать их и вырабатывать пару «ключ-значение», где ключ совпадает с ключом ввода, а значение – фактически сумма входных значений.
Также у нас есть некоторый код, который имеет функцию запуска, указывая имя работы, определяя ключи и выходные значения, и в конце запуская работу.

Посмотрим пример приложения, который использует MapReduce.
Это распределенный grep.
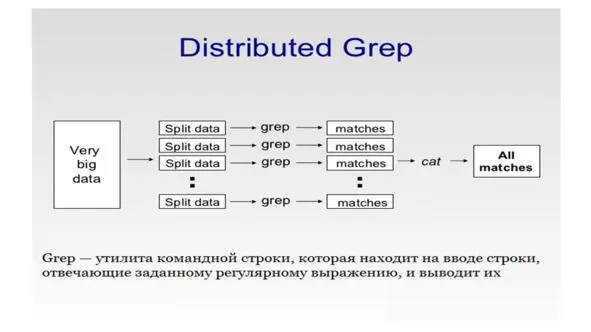
Предположим, у вас есть большой набор файлов с большими текстами в них.
И у вас есть шаблон, который может быть регулярным выражением или просто словом, или набором слов, и вы хотите вывести все строки текста, соответствующие этому шаблону.
Читать дальшеИнтервал:
Закладка: