Тимур Машнин - Введение в облачные и распределенные информационные системы

- Название:Введение в облачные и распределенные информационные системы
- Автор:
- Жанр:
- Издательство:неизвестно
- Год:неизвестен
- ISBN:9785005303110
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Тимур Машнин - Введение в облачные и распределенные информационные системы краткое содержание
Введение в облачные и распределенные информационные системы - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
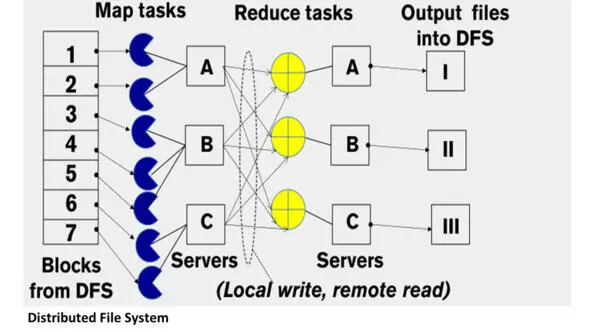
Таким образом, Map будет принимать на вход каждую строку текста и проверять ее на соответствие шаблону, а затем выводить эту строку как ключ.
Reduce будет просто копировать промежуточные данные на выход, не выполняя никакой обработки, если вы конечно не захотите, например, соединить все строки.
Решая такую простую задачу на одной машине, для больших объемов данных, вы можете потратить очень много времени.
Преимущество распределенного grep здесь в скорости обработки.
С помощью MapReduce вы можете запускать ваше приложение, даже если ваши данные распределены на нескольких серверах.
Итак, как программировать с MapReduce?
С точки зрения пользователя, пользователь записывает программу map, ее метод map, а также записывает программу reduce, и ее метод reduce.
Затем запускает работу, определяя количество задач map и reduce, и затем ожидает результата.
По сути, работа пользователя очень простая, потому что пользователю не нужно много знать о Hadoop или распределенном программировании.
Это внутри, реализация парадигмы MapReduce, и собственно планировщик должен обеспечить распараллеливание map, он должен разделить данные между различными задачами map.
И он должен передать данные из map в reduce, при этом разделяя ключи по reduce задачам.
А также необходимо распараллелить reduce.
Другими словами, необходимо запланировать сами задачи reduce.
И, наконец, необходимо реализовать хранилище для ввода map, для вывода map, которое совпадает с вводом reduce, а также реализовать вывод reduce.
Кроме того, нужно обеспечить, чтобы фаза reduce стартовала только после окончания фазы map.
Итак, как решить все эти проблемы?
В облаке распараллелить map легко, потому что каждая задача map является независимой от другой задачи map, и поэтому эти задачи map могут быть определены для выполнения любому серверу.
Обычно задачи map назначаются серверу, к которому эти данные наиболее близко находятся, чтобы уменьшить сетевые издержки.
Далее необходимо гарантировать, чтобы все исходящие записи map с одним и тем же ключом были присвоены одному и тому же reduce.
И это поможет перевести данные с map на reduce.
В этом случае вы используете функцию partitioning.
Например, как мы обсуждали ранее, может использоваться функция хэш-разбиения, когда каждому ключу присваивается номер задачи, который получается путем вычисления остатка от деления хеша ключа на количество reduce задач.
Завершить фазу reduce также легко, потому что каждая задача reduce не зависит от другой.
Каждой задаче reduce присваивается набор ключей, и эти наборы ключей не пересекаются друг с другом.
И поэтому их можно запустить независимо друг от друга.
Наконец, вам нужно реализовать хранилище.
Ввод map в начале идет из распределенной файловой системы, вывод map идет в локальную файловую систему map узла.
Ввод reduce идет из множества удаленных дисков, используя локальные файловые системы.
Вывод reduce идет в распределенную файловую систему.
Эта распределенная файловая система запускается обычно на тех же серверах, где выполняются задачи map и reduce.
Например, Apache Hadoop использует HDFS, известную как распределенная файловая система Hadoop.
Обычно эта файловая система хранит множественные копии одного и того же входного блока данных.
Она копирует файловые блоки как минимум три раза и эти три файловые копии размещаются на трех разных серверах.
И поэтому, когда запускается задача map, необходимо извлечь блок данных, который является его блоком входных данных с одного из серверов, который хранит его в настоящее время.
Задача запрашивает онлайн-файловую систему HDFS, чтобы сделать это, и эта передача выполняется быстрее, если сервер, на котором расположен этот конкретный блок, фактически является тем же сервером, на котором выполняется задача map.
Вывод map не хранится в распределенной файловой системе.
Вместо этого вывод map сохраняется на локальном диске на сервере, на котором выполняется задача map.
И ввод данных reduce производится с этих удаленных дисков.
Причина, по которой этот промежуточный траффик между map и reduce использует локальную файловую систему – это скорость передачи данных и потому что эти данные не нужны внешнему пользователю.
Наконец, когда результат reduce получен, он записывается в распределенную файловую систему обратно, где он становится доступен.
Давайте немного посмотрим, как работает планировщик.
Планировщик YARN – это планировщик, который используется в Apache Hadoop.
YARN означает Yet Another Resource Negotiator.
Он обрабатывает каждый сервер как коллекцию контейнеров.
Контейнер – это процессор с некоторой памятью.
Таким образом, каждый сервер состоит из коллекции контейнеров.
Так, например, если сервер имеет 4 ядра и 4 гигабайта ОЗУ, в каждом контейнере есть одно ядро и 1 гигабайт ОЗУ, и у этого сервера есть 4 контейнера и, по существу, он может выполнять четыре задачи по одной в каждом контейнере.
YARN имеет три основных компонента.
Это менеджер ресурсов, администраторы узлов и мастера приложений.
И существует один глобальный менеджер ресурсов, который запускает планировщика.
Существует один менеджер узла на один сервер в системе.
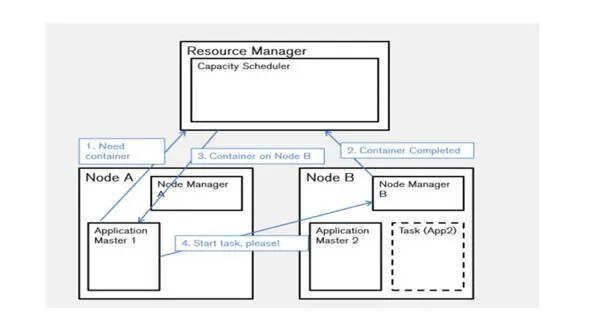
Это Daemon, который отвечает за все специфическое управление сервером, а также отвечает за мониторинг сбоев задач, которые выполняются на этой конкретной машине.
Затем есть Application Master, или мастер приложения, который также работает на одном из серверов, и отвечает за согласование контейнеров с диспетчером ресурсов и менеджерами узлов.
Он также отвечает за взаимодействие с менеджерами узлов, чтобы выяснить, умер ли какой-либо из них, чтобы перенести с него запущенные задачи.
Теперь давайте посмотрим, как MapReduce разбирается с ошибками.
Наиболее частой ошибкой является отказ самого сервера, и отказ сервера может привести к сбою нескольких компонентов Hadoop планировщика YARN.
Серверы запускают менеджеров узлов, у них запущены задачи, на одном из серверов работает диспетчер ресурсов, а также может работать мастер приложений.
И для решения проблем с отказами серверов, есть пульсация.
Менеджер узла на каждом сервере отправляет пульсацию центральному менеджеру ресурсов.
И если сервер не работает, и эта пульсация останавливается, менеджер ресурсов знает, что менеджер узла не работает.
Он дает знать об этом всем мастерам приложений, и мастера приложений перенаправляют свои задачи.
Менеджер узлов отслеживает каждую задачу, запущенную на своем сервере, поэтому, если одна из задач выходит из строя, эта задача помечается как протаивающая, и, либо менеджер узла ее перезапускает, если это возможно, либо он сообщает диспетчеру ресурсов или мастеру приложения, что эта задача не выполнена.
Читать дальшеИнтервал:
Закладка: