Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]
![Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]](/books/1150039/roman-zykov-roman-s-data-science-kak-monetizirova.webp "Обложка книги")
- Название:Роман с Data Science. Как монетизировать большие данные [litres]
- Автор:
- Жанр:
- Издательство:Издательство Питер
- Год:2021
- Город:Санкт-Петербург
- ISBN:978-5-4461-1879-3
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres] краткое содержание
Эта книга предназначена для думающих читателей, которые хотят попробовать свои силы в области анализа данных и создавать сервисы на их основе. Она будет вам полезна, если вы менеджер, который хочет ставить задачи аналитике и управлять ею. Если вы инвестор, с ней вам будет легче понять потенциал стартапа. Те, кто «пилит» свой стартап, найдут здесь рекомендации, как выбрать подходящие технологии и набрать команду. А начинающим специалистам книга поможет расширить кругозор и начать применять практики, о которых они раньше не задумывались, и это выделит их среди профессионалов такой непростой и изменчивой области. Книга не содержит примеров программного кода, в ней почти нет математики.
В формате PDF A4 сохранен издательский макет.
Роман с Data Science. Как монетизировать большие данные [litres] - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Датасет
Датасет – это набор данных, чаще всего в виде таблицы, который был выгружен из хранилища (например, через SQL) или получен иным способом. Таблица состоит из столбцов и строк, обычно именуемых как записи. В машинном обучении сами столбцы бывают независимыми переменными (independent variables), или предикторами (predictors), или чаще фичами (features), и зависимыми переменными (dependent variables, outcome). Такое разделение вы встретите в литературе. Задачей машинного обучения является обучение модели, которая, используя независимые переменные (фичи), сможет правильно предсказать значение зависимой переменной (как правило, в датасете она одна).
Основные два вида переменных – категориальные и количественные. Категориальная (categorical) переменная содержит текст или цифровое кодирование «категории». В свою очередь, она может быть:
• Бинарной (binary) – может принимать только два значения (примеры: да/нет, 0/1).
• Номинальной (nominal) – может принимать больше двух значений (пример: да/нет/не знаю).
• Порядковой (ordinal) – когда порядок имеет значение (пример, ранг спортсмена, номер строки в поисковой выдаче).
Количественная (quantitative) переменная может быть:
• Дискретной (discrete) – значение подсчитано счетом, например, число человек в комнате.
• Непрерывной (continuous) – любое значение из интервала, например, вес коробки, цена товара.
Рассмотрим пример. Есть таблица с ценами на квартиры (зависимая переменная), одна строка (запись) на квартиру, у каждой квартиры есть набор атрибутов (независимы) со следующими столбцами:
• Цена квартиры – непрерывная, зависимая.
• Площадь квартиры – непрерывная.
• Число комнат – дискретная (1, 2, 3…).
• Санузел совмещен (да/нет) – бинарная.
• Номер этажа – порядковая или номинальная (зависит от задачи).
• Расстояние до центра – непрерывная.
Описательная статистика
Самое первое действие после выгрузки данных из хранилища – сделать разведочный анализ (exploratory data analysis), куда входит описательная статистика (descriptive statistics) и визуализация данных, возможно, очистка данных через удаление выбросов (outliers).
В описательную статистику обычно входят различные статистики по каждой из переменных во входном датасете:
• Количество непустых значений (non missing values).
• Количество уникальных значений.
• Минимум/максимум.
• Среднее значение.
• Медиана.
• Стандартное отклонение.
• Перцентили (percentiles) – 25 %, 50 % (медиана), 75 %, 95 %.
Не для всех типов переменных их можно посчитать – например, среднее значение можно рассчитать только для количественных переменных. В статистистических пакетах и библиотеках статистического анализа уже есть готовые функции, которые считают описательные статистики. Например, в библиотеке pandas для Python есть функция describe, которая сразу выведет несколько статистик для одной или всех переменных датасета:
s = pd.Series([4–1, 2, 3])
s.describe()
count 3.0
mean 2.0
std 1.0
min 1.0
25 % 1.5
50 % 2.0
75 % 2.5
max 3.0
Хотя эта книга не является учебником по статистике, дам вам несколько полезных советов. Часто в теории подразумевается, что мы работаем с нормально распределенными данными, гистограмма которых выглядит как колокол (рис. 4.1).
Очень рекомендую проверять это предположение хотя бы на глаз. Медиана – значение, которое делит выборку пополам. Например, если 25-й и 75-й перцентиль находятся на разном расстоянии от медианы, это уже говорит о смещенном распределении. Еще один фактор – сильное различие между средним и медианой; в нормальном распределении они практически совпадают. Вы будете часто иметь дело с экспоненциальным распределением, если анализируете поведение клиентов, – например, в Ozon.ru время между последовательными заказами клиента будет иметь экспоненциальное распределение.
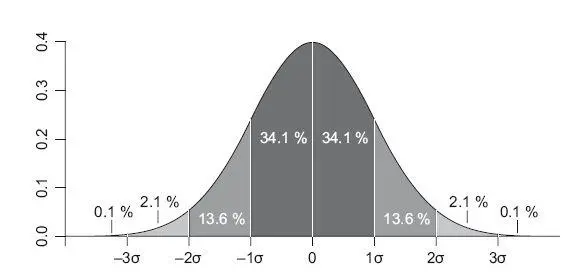
Рис. 4.1.Нормальное распределение и Шесть Сигм
Среднее и медиана для него отличаются в разы. Поэтому правильная цифра – медиана, значение, которое делит выборку пополам. В примере с Ozon.ru это время, в течение которого 50 % пользователей делают следующий заказ после первого. Медиана также более устойчива к выбросам в данных. Если же вы хотите работать со средними, например, из-за ограничений статистического пакета, да и технически среднее считается быстрее, чем медиана, то в случае экспоненциального распределения можно его обработать натуральным логарифмом. Чтобы вернуться в исходную шкалу данных, нужно полученное среднее обработать обычной экспонентой.
Перцентиль – значение, которое заданная случайная величина не превышает с фиксированной вероятностью. Например, фраза «25-й перцентиль цены товаров равен 150 рублям» означает, что 25 % товаров имеют цену меньше или равную 150 рублям, остальные 75 % товаров дороже 150 рублей.
Для нормального распределения, если известно среднее и стандартное отклонение, есть полезные теоретически выведенные закономерности – 95 % всех значений попадает в интервал на расстоянии двух стандартных отклонений от среднего в обе стороны, то есть ширина интервала составляет четыре сигмы. Возможно, вы слышали такой термин, как Шесть сигм (six sigma, рис. 4.1), – эта цифра характеризует производство без брака. Так вот, этот эмпирический закон следует из нормального распределения: в интервал шести стандартных отклонений вокруг среднего (по три в каждую сторону) укладывается 99.99966 % значений – идеальное качество. Перцентили очень полезны для поиска и удаления выбросов из данных. Например, при анализе экспериментальных данных вы можете принять то, что все данные вне 99-го перцентиля – выбросы, и удалять их.
Графики
Хороший график стоит тысячи слов. Основные виды графиков, которыми пользуюсь я:
• гистограммы;
• диаграмма рассеяния (scatter chart);
• график временного ряда (time series) с линией тренда;
• график «ящики с усами» (box plot, box and whiskers plot).
Гистограмма (рис. 4.2) – наиболее полезный инструмент анализа. Она позволяет визуализировать распределение по частотам появления какого-то значения (для категориальной переменной) или разбить непрерывную переменную на диапазоны (bins). Второе используется чаще, и если к такому графику дополнительно предоставить описательные статистики, то у вас будет полная картина, описывающая интересующую вас переменную. Гистограмма – это простой и интуитивно понятный инструмент.
График диаграммы рассеяния (scatterplot, рис. 4.3) позволяет увидеть зависимость двух переменных друг от друга. Строится он просто: на горизонтальной оси – шкала независимой переменной, на вертикальной оси – шкала зависимой. Значения (записи) отмечаются в виде точек. Также может добавляться линия тренда. В продвинутых статистических пакетах можно интерактивно пометить выбросы.
Читать дальшеИнтервал:
Закладка:









