Владстон Феррейра Фило - Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]
![Владстон Феррейра Фило - Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]](/books/1060455/vladston-ferrejra-filo-teoreticheskij-minimum-po-co.webp "Обложка книги")
- Название:Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]
- Автор:
- Жанр:
- Издательство:Питер
- Год:2018
- Город:СПб.
- ISBN:978-5-4461-0587-8
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Владстон Феррейра Фило - Теоретический минимум по Computer Science [Все что нужно программисту и разработчику] краткое содержание
Владстон Феррейра Фило знакомит нас с вычислительным мышлением, позволяющим решать любые сложные задачи. Научиться писать код просто — пара недель на курсах, и вы «программист», но чтобы стать профи, который будет востребован всегда и везде, нужны фундаментальные знания. Здесь вы найдете только самую важную информацию, которая необходима каждому разработчику и программисту каждый день. cite
Владстон Феррейра Фило
Теоретический минимум по Computer Science [Все что нужно программисту и разработчику] - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
AVL-дерево (AVL tree) — это еще один подвид сбалансированных деревьев. Оно требует немного большего времени для вставки и удаления элементов, чем красно-черное дерево, но, как правило, обладает лучшим балансом. Это означает, что оно позволяет получать элементы быстрее, чем красно-черное дерево. AVL-деревья часто используются для оптимизации производительности в сценариях, для которых характерна высокая интенсивность чтения.
Данные часто хранятся на магнитных дисках, которые считывают их большими блоками. В этих случаях используется обобщенное двоичное B-дерево (B-tree). В таких деревьях узлы могут хранить более одного элемента и иметь более двух дочерних узлов, что позволяет им эффективно оперировать данными в больших блоках. Как мы вскоре увидим, B-деревья обычно используются в системах управления базами данных.
Двоичная куча
Двоичная куча (binary heap) — особый тип двоичного дерева поиска, в котором можно мгновенно найти самый маленький (или самый большой) элемент. Эта структура данных особенно полезна для реализации очередей с приоритетом. Операция получения минимального (или максимального) элемента имеет сложность O (1), потому что он всегда является корневым узлом дерева. Поиск и вставка узлов здесь по-прежнему стоят O (log n ). Кучи подчиняются тем же правилам размещения узлов, что и двоичные деревья поиска, но есть одно ограничение: родительский узел должен быть больше (либо меньше) обоих своих дочерних узлов (рис. 4.9).
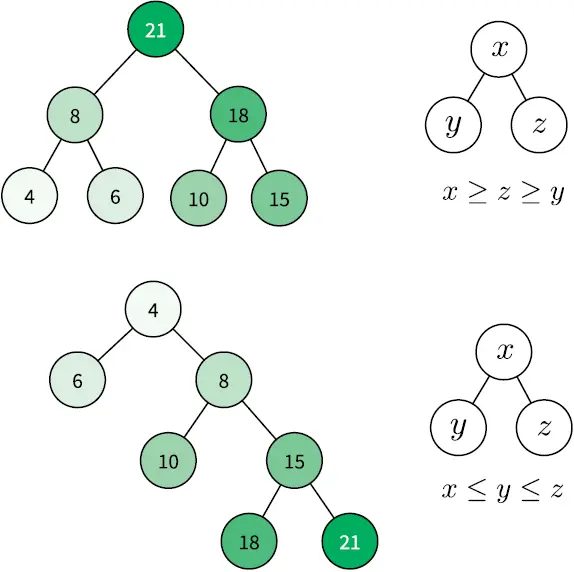
Рис. 4.9.Узлы, организованные как двоичная куча max-heap (вверху) и двоичная куча min-heap (внизу) [50] Двоичная куча min-heap характерна тем, что значение в любой ее вершине не больше , чем значения ее потомков; в двоичной куче max-heap, наоборот, значение в любой вершине не меньше , чем значения ее потомков. — Примеч. пер.
Обращайтесь к двоичной куче всегда, когда планируете часто иметь дело с максимальным (либо минимальным) элементом множества.
Граф
Граф (graph) аналогичен дереву. Разница состоит в том, что у него нет ни дочерних, ни родительских узлов (вершин) и, следовательно, нет корневого узла. Данные свободно организованы в виде узлов (вершин) и дуг (ребер) так, что любой узел может иметь произвольное число входящих и исходящих ребер.
Это самая гибкая из всех структур, она используется для представления почти всех типов данных. Например, графы идеальны для социальной сети, где узлы — это люди, а ребра — дружеские связи.
Хеш-таблица
Хеш-таблица (hash table) — это структура данных, которая позволяет находить элементы за O (1). Поиск занимает постоянное время вне зависимости от того, ищете вы среди 10 млн элементов или всего среди 10.
Так же, как массив, хеш для хранения данных требует предварительного выделения большого блока последовательной памяти. Но, в отличие от массива, его элементы хранятся не в упорядоченной последовательности. Позиция, занимаемая элементом, «волшебным образом» задается хеш-функцией . Это специальная функция, которая на входе получает данные, предназначенные для хранения, и возвращает число, кажущееся случайным. Оно интерпретируется как позиция в памяти, куда будет помещен элемент.
Это позволяет нам получать элементы немедленно. Заданное значение сначала пропускается через хеш-функцию. Она выдает точную позицию, где элемент должен находиться в памяти. Если элемент был сохранен, то вы найдете его в этой позиции.
Однако с хеш-таблицами возникают проблемы: иногда хеш-функция возвращает одинаковую позицию для разных входных данных. Такая ситуация называется хеш-коллизией . Когда она происходит, все такие элементы должны быть сохранены в одной позиции в памяти (эта проблема решается, например, посредством связного списка, который начинается с заданного адреса). Хеш-коллизии влекут за собой издержки процессорного времени и памяти, поэтому их желательно избегать.
Хорошая хеш-функция должна возвращать разные значения для разных входных данных. Следовательно, чем шире диапазон значений, которые может вернуть хеш-функция, тем больше будет доступно позиций для данных и меньше вероятность возникновения хеш-коллизии. Поэтому нужно гарантировать, чтобы в хеш-таблице оставалось незанятым по крайней мере 50 % пространства. В противном случае коллизии начнут происходить слишком часто и производительность хеш-таблицы значительно упадет.
Хеш-таблицы часто используются для реализации словарей и множеств. Они позволяют выполнять операции вставки и удаления быстрее, чем структуры данных, основанные на деревьях.
С другой стороны, для корректной работы хеш-таблицы требуют выделения очень большого блока непрерывной памяти.
Подведем итоги
Мы узнали, что структуры данных определяют конкретные способы организации элементов в памяти компьютера. Разные структуры данных требуют разных операций для хранения, удаления, поиска и обхода хранящихся данных. Чудодейственного средства не существует: всякий раз нужно выбирать, какую структуру данных использовать в соответствии с текущей ситуацией.
Еще мы узнали, что вместо структур данных лучше иметь дело с АТД. Они освобождают код от деталей, связанных с обработкой данных, и позволяют легко переключаться с одной структуры на другую без каких-либо изменений в коде.
Не изобретайте колесо заново, пытаясь с нуля создавать базовые структуры данных и абстрактные типы данных (если только вы не делаете это ради забавы, обучения или исследования). Пользуйтесь проверенными временем сторонними библиотеками обработки данных. Большинство языков имеет встроенную поддержку этих структур.
Полезные материалы
• Балансировка двоичного дерева поиска (Balancing a Binary Search Tree, Stoimen, см. https://code.energy/stoimen).
• Лекция Корнелльского университета по абстрактным типам данных и структурам данных (Cornell Lecture on Abstract Data Types and Data Structures, см. https://code.energy/cornell-adt).
• Конспекты IITKGP по абстрактным типам данных (IITKGP notes on Abstract Data Types, см. https://code.energy/iitkgp).
• Реализация дерева поиска на «интерактивном Python» (Search Tree Implementation by “Interactive Python”, см. https://code.energy/python-tree).
Глава 5. Алгоритмы
[Программирование является] привлекательным занятием не только потому, что оно перспективно с экономической и научной точек зрения, но и потому, что оно во многом может стать эстетическим опытом, как сочинение стихов или музыки.
Дональд КнутЧеловечество изыскивает решения все более и более трудных задач. В большинстве случаев вам приходится иметь дело с задачами, над примерными аналогами которых уже потрудились многие разработчики. Вполне вероятно, что они придумали эффективные алгоритмы, которые можно брать и использовать. Когда вы решаете задачи, вашим первым шагом всегда должен быть поиск существующих алгоритмов [51] Ситуация, когда найдена новая, неисследованная задача, — это редкость. Когда исследователи находят новую задачу, они пишут об этом научную работу.
. В этой главе мы займемся исследованием хорошо известных алгоритмов, которые:
Интервал:
Закладка:









