Владстон Феррейра Фило - Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]
![Владстон Феррейра Фило - Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]](/books/1060455/vladston-ferrejra-filo-teoreticheskij-minimum-po-co.webp "Обложка книги")
- Название:Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]
- Автор:
- Жанр:
- Издательство:Питер
- Год:2018
- Город:СПб.
- ISBN:978-5-4461-0587-8
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Владстон Феррейра Фило - Теоретический минимум по Computer Science [Все что нужно программисту и разработчику] краткое содержание
Владстон Феррейра Фило знакомит нас с вычислительным мышлением, позволяющим решать любые сложные задачи. Научиться писать код просто — пара недель на курсах, и вы «программист», но чтобы стать профи, который будет востребован всегда и везде, нужны фундаментальные знания. Здесь вы найдете только самую важную информацию, которая необходима каждому разработчику и программисту каждый день. cite
Владстон Феррейра Фило
Теоретический минимум по Computer Science [Все что нужно программисту и разработчику] - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
SELECT country, AVG(age)
FROM customers
GROUP BY country
ORDER BY country;
Он вернет сортированный список стран, где проживают ваши клиенты, вместе со средним возрастом клиентов по каждой стране. SQL предоставляет и другие агрегатные функции. Например, замените AVG(age) на MAX(age), и вы получите возраст самого старого клиента в каждой стране.
Иногда бывает нужно изучить информацию из строки и строк, с которыми она связана. Представьте, что у вас есть таблица с заказами и таблица с клиентами. Таблица orders имеет внешний ключ для ссылки на клиентов. Чтобы найти информацию о клиентах, сделавших дорогостоящие заказы, придется выбрать данные из обеих таблиц. Но вам не нужно запрашивать их по отдельности и сопоставлять записи самостоятельно. Для этого в языке SQL имеется специальная команда:
SELECT DISTINCT customers.name, customers.phone
FROM customers
JOIN orders ON orders.customer = customers.id
WHERE orders.amount > 100.00;
Этот запрос вернет имена и телефонные номера клиентов, сделавших заказы на сумму более 100 долларов. Команда SELECT DISTINCT заставляет СУБД вернуть каждого клиента только один раз. JOIN позволяет делать очень гибкие запросы [59] Существует несколько способов выполнить операцию JOIN — см. https://code.energy/joins .
, но эта гибкость имеет свою цену. Соединения обходятся дорого. Базе данных придется рассмотреть все сочетания строк из таблиц, которые вы объединяете в своем запросе. Администратор базы данных должен всегда принимать во внимание произведение числа строк объединяемых таблиц. Для очень больших таблиц соединения становятся невыполнимыми. Оператор JOIN — это самый мощный инструмент и одновременно главная слабость реляционных баз данных.
Индексация
Чтобы от первичного ключа таблицы была польза, необходимо иметь возможность быстро получить запись по ID. Для этого СУБД строит вспомогательный индекс , содержащий ID строк, и соответствующие им адреса в памяти (рис. 6.4). По сути, индекс — это сбалансированное двоичное дерево поиска (см. раздел «Структуры» предыдущей главы). Каждая строка в таблице соответствует узлу в дереве.
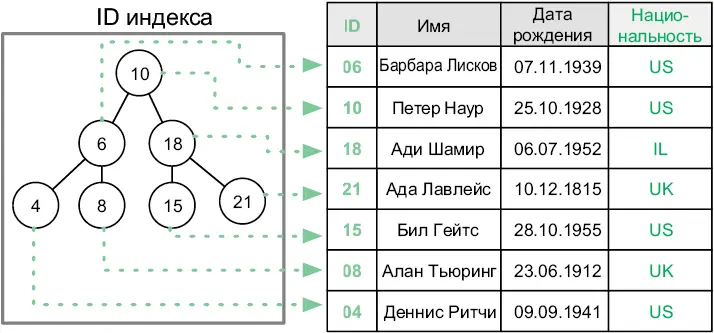
Рис. 6.4.Индекс, отображающий значения ID и расположение соответствующих строк
Ключи узлов — это значения в индексируемом поле. Чтобы найти запись с заданным значением, мы ищем его в дереве. Найдя узел, мы получаем адрес, который он хранит, и используем его для выборки записи. Поиск по двоичному дереву имеет сложность O (log n ), поэтому нахождение записей в больших таблицах выполняется быстро.
Обычно СУБД создает индекс для каждого первичного ключа в базе данных. Но если часто приходится искать записи по другим полям (например, искать клиентов по именам), можно поручить СУБД создать для них дополнительные индексы.
Ограничения уникальности.Индексы часто создаются автоматически для полей, которые имеют ограничение уникальности. При вставке новой строки СУБД должна обследовать всю таблицу, чтобы удостовериться, что ни одно ограничение уникальности не нарушено. Не будь индекса, такая проверка означала бы, что нужно свериться со всеми строками в таблице. При помощи индекса мы можем быстро выполнить поиск и, например, обнаружить, что значение, которое мы пытаемся вставить, уже присутствует. Индексация полей, имеющих ограничение уникальности, необходима для быстрой вставки элементов.
Сортировка.Индексы помогают выбирать строки в порядке сортировки по индексированным полям. Например, если имеется индекс для поля name («имя»), мы можем получить строки, отсортированные по имени, без дополнительных вычислений. Если применить команду ORDER BY к полю без индекса, СУБД придется отсортировать данные в памяти, прежде чем выполнить запрос. Многие СУБД могут даже отказаться выполнять запрос, требующий произвести сортировку по неиндексированному полю, если в работу будет вовлечено слишком много строк.
Если вы должны отсортировать строки сначала по стране, а затем по возрасту, наличие индекса в поле age («возраст») или в поле country («страна») не сильно вам поможет. Индекс в country позволяет выбирать строки, отсортированные по стране, но затем вам потребуется вручную сортировать по возрасту элементы, которые имеют одинаковую страну. Когда требуется сортировка по двум полям, используются комбинированные, или объединенные, индексы . Они индексируют многочисленные поля и не способны помочь искать элементы быстрее, зато позволяют легко получать данные, отсортированные по нескольким полям.
Производительность.Итак, индексы — это круто: они позволяют делать сверхбыстрые запросы и мгновенно получать доступ к отсортированным данным. Тогда почему у нас нет индексов для всех полей в каждой таблице? Проблема в том, что, когда новая запись вставляется в таблицу или удаляется из нее, приходится обновлять все индексы, чтобы отразить это изменение. Если индексов много, то обновление, вставка или удаление строк могут стать в вычислительном плане дорогостоящими операциями (вспомним про балансировку дерева). Более того, индексы занимают ограниченное дисковое пространство.
Вы должны следить за тем, как ваше приложение использует базу данных. СУБД обычно поставляются вместе с инструментами, которые помогают это делать. Они могут «объяснять» запросы, сообщая, какие индексы использовались, а также сколько строк необходимо было последовательно просканировать, чтобы выполнить запрос. Если ваши запросы тратят впустую слишком много времени, последовательно сканируя данные в некоем поле, то добавьте для этого поля индекс и посмотрите, будет ли польза. Например, если вы часто ищете в базе данных людей конкретного возраста, то определение индекса для поля age позволит СУБД сразу отбирать строки, соответствующие конкретному возрасту. Вы сэкономите время, избежав последовательного просмотра базы данных с дальнейшей фильтрацией строк, не соответствующих требуемому возрасту.
Если вы хотите настроить базу данных, чтобы повысить ее производительность, чрезвычайно важно знать, какие индексы стоит сохранять, а какие — отбрасывать. Если доступ к БД главным образом осуществляется в режиме чтения, а обновляется она редко, может иметь смысл создать больше индексов. Плохая индексация — главная причина замедлений в коммерческих системах. Небрежные системные администраторы зачастую не задаются вопросом, как выполняются типичные запросы, — они просто индексируют произвольные поля, которые, по их мнению, будут способствовать производительности. Этого не стоит делать! Воспользуйтесь «объясняющими» инструментами, чтобы проверить свои запросы и создать индексы только там, где они нужны.
Читать дальшеИнтервал:
Закладка:









