Владстон Феррейра Фило - Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]
![Владстон Феррейра Фило - Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]](/books/1060455/vladston-ferrejra-filo-teoreticheskij-minimum-po-co.webp "Обложка книги")
- Название:Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]
- Автор:
- Жанр:
- Издательство:Питер
- Год:2018
- Город:СПб.
- ISBN:978-5-4461-0587-8
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Владстон Феррейра Фило - Теоретический минимум по Computer Science [Все что нужно программисту и разработчику] краткое содержание
Владстон Феррейра Фило знакомит нас с вычислительным мышлением, позволяющим решать любые сложные задачи. Научиться писать код просто — пара недель на курсах, и вы «программист», но чтобы стать профи, который будет востребован всегда и везде, нужны фундаментальные знания. Здесь вы найдете только самую важную информацию, которая необходима каждому разработчику и программисту каждый день. cite
Владстон Феррейра Фило
Теоретический минимум по Computer Science [Все что нужно программисту и разработчику] - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Транзакции
Представим, что скрытный швейцарский банк  не ведет учета денежных переводов: его база данных просто хранит баланс счетов. Предположим, что кто-то хочет перечислить деньги со своего счета на счет друга в том же банке. Две операции должны быть выполнены в базе данных банка — денежную сумму нужно вычесть из одного баланса и прибавить к другому.
не ведет учета денежных переводов: его база данных просто хранит баланс счетов. Предположим, что кто-то хочет перечислить деньги со своего счета на счет друга в том же банке. Две операции должны быть выполнены в базе данных банка — денежную сумму нужно вычесть из одного баланса и прибавить к другому.
Сервер БД обычно позволяет многочисленным клиентам читать и записывать данные одновременно — исполнение операций в последовательном режиме сделало бы любую СУБД слишком медленной. Но вот подвох: если кто-то запросит общий баланс всех счетов после регистрации вычитания, но до соответствующего добавления, то какая-то сумма будет отсутствовать. Или вот вариант похуже: а что, если система окажется обесточена между этими двумя операциями? Когда сервер снова заработает, будет трудно выяснить причину расхождения в данных.
Нам нужны способы, которыми СУБД выполняла бы либо все изменения, входящие в многосоставную операцию, либо сохраняла данные неизменными. С этой целью системы баз данных поддерживают транзакции . Транзакция — список операций, которые должны быть выполнены атомарно [60] Атомарные операции выполняются одноэтапно: они не могут быть выполнены наполовину.
. Транзакции упрощают жизнь программиста: вместо него за обеспечение непротиворечивости данных отвечает СУБД. От программиста только требуется обертывать зависимые операции в соответствующие команды:
START TRANSACTION;
UPDATE vault SET balance = balance + 50 WHERE id=2;
UPDATE vault SET balance = balance — 50 WHERE id=1;
COMMIT;
Запомните: выполнение многосоставных обновлений без транзакций рано или поздно создаст беспорядочные, непредсказуемые и трудные в обнаружении противоречия в ваших данных.
6.2. Нереляционная модель
Реляционные базы данных замечательны, однако у них есть некоторые недостатки. По мере усложнения приложения в его реляционную базу данных приходится добавлять все больше таблиц. Запросы становятся все менее понятными. И, главное, все чаще приходится прибегать к соединениям (JOIN), требующим большого объема вычислений и создающим в системе узкие места.

Рис. 6.5 [61] Любезно предоставлено http://geek-and-poke.com .
Нереляционная модель не использует табличные связи. Она почти никогда не требует объединять информацию из нескольких записей. Поскольку нереляционные СУБД используют языки запросов, отличные от SQL, они также называются базами данных NoSQL.
Документные хранилища
Наиболее известным типом баз данных NoSQL являются документные хранилища . В них записи хранятся в том виде, в котором они необходимы приложению. Рис. 6.6, приведенный ниже, сравнивает табличный и документный способы хранения постов в блоге.
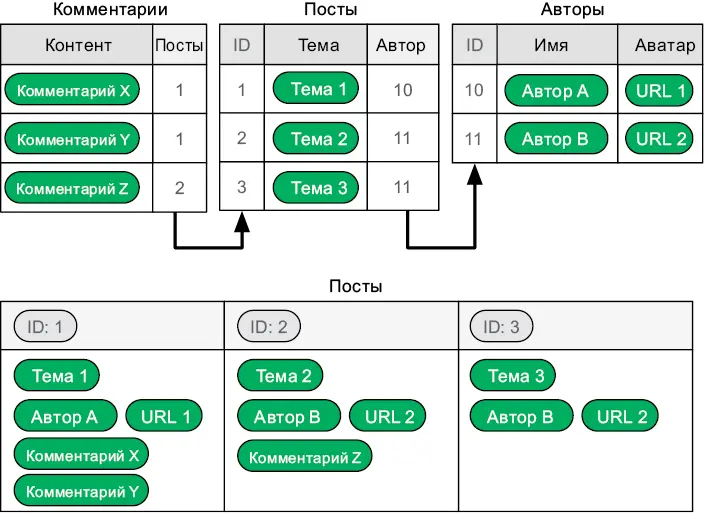
Рис. 6.6.Данные в реляционной модели (вверху) и данные в NoSQL (внизу)
Заметили, что все данные о сообщении копируются в соответствующую ему запись? Нереляционная модель предполагает возможность дублирования информации при необходимости. Однако дублированные данные сложно своевременно обновлять и поддерживать их непротиворечивость. С другой стороны, группируя соответствующие данные, документное хранилище может предложить бо́льшую гибкость:
• вам не нужно соединять строки;
• можно обойтись без фиксированных схем;
• каждая запись может иметь собственное сочетание полей.
В документных хранилищах вообще нет таблиц и строк. Вместо них есть записи, называемые документами . Связанные между собой документы группируются в коллекцию .
Документы имеют поле первичного ключа, поэтому их можно связывать друг с другом. Но операции JOIN в документных хранилищах неэффективны. Иногда они даже невозможны, в этом случае вам придется следить за связями между документами самостоятельно. И то и другое плохо — если документы имеют общие данные, их приходится дублировать.
Как и реляционные базы данных, базы данных NoSQL создают индексы для полей с первичным ключом. Также можно определять дополнительные индексы для полей, которые часто запрашиваются или сортируются.
Хранилища «ключ — значение»
Хранилище «ключ — значение» — это простейшая форма организованного хранения данных. В основном используется для кэширования. Например, когда некто запрашивает определенную веб-страницу на сервере, тот должен выбрать соответствующие ей данные из БД и использовать их для конструирования HTML-разметки, которую увидит пользователь. В сайтах с высокой посещаемостью, где случаются тысячи параллельных доступов, делать это становится невозможным.
Для решения проблемы мы используем хранилище «ключ — значение» как механизм кэширования. Ключом является требуемый URL-адрес, значением — HTML-разметка соответствующей веб-страницы. В следующий раз, когда кто-то запросит тот же URL-адрес, готовый код HTML просто будет извлечен из хранилища «ключ — значение» через ключ-адрес.
Если вам приходится раз за разом выполнять медленную операцию, всегда приводящую к одному и тому же результату, рассмотрите возможность его кэширования. Вам не обязательно использовать хранилище «ключ — значение», кэш может содержаться и в базах данных другого типа. Однако когда кэш запрашивается очень часто, система хранилищ данных типа «ключ — значение» — наилучший вариант.
Графовые базы данных
В графовой базе данных записи хранятся в виде вершин, а связи — в виде ребер. Вершины не привязаны к фиксированной схеме и могут содержать данные в разном формате. Графовая структура делает эффективной работу с записями в соответствии с их связями. Вот как информация из рис. 6.6 будет выглядеть в форме графа:
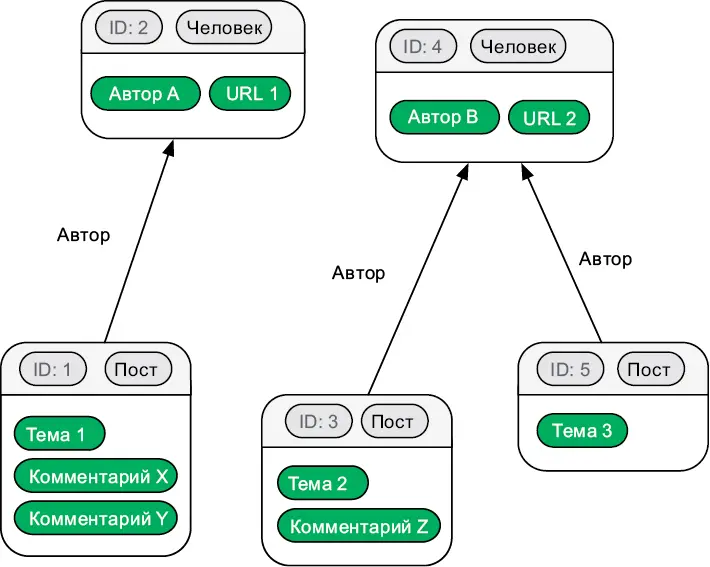
Рис. 6.7.Информация блога, хранящаяся в графовой базе данных
Это самый гибкий тип баз данных. Избавившись от таблиц и коллекций, вы можете хранить сетевые данные интуитивно понятным способом. Если бы вы решили нарисовать станции метро и остановки наземного общественного транспорта на доске, вы не стали бы изображать их в табличной форме. Вы бы использовали круги, прямоугольники и стрелки. Графовые БД позволяют хранить информацию именно таким образом.
Если ваши данные похожи на сеть, подумайте об использовании графовой базы данных. Этот тип БД особенно полезен, когда между компонентами данных много важных связей. Графовые базы данных также позволяют выполнять различные типы граф-ориентированных запросов. Например, если вы храните данные об общественном транспорте в графе, можете прямо запросить лучший маршрут между двумя остановками в одну сторону или туда и обратно.
Читать дальшеИнтервал:
Закладка:









