Владстон Феррейра Фило - Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]
![Владстон Феррейра Фило - Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]](/books/1060455/vladston-ferrejra-filo-teoreticheskij-minimum-po-co.webp "Обложка книги")
- Название:Теоретический минимум по Computer Science [Все что нужно программисту и разработчику]
- Автор:
- Жанр:
- Издательство:Питер
- Год:2018
- Город:СПб.
- ISBN:978-5-4461-0587-8
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Владстон Феррейра Фило - Теоретический минимум по Computer Science [Все что нужно программисту и разработчику] краткое содержание
Владстон Феррейра Фило знакомит нас с вычислительным мышлением, позволяющим решать любые сложные задачи. Научиться писать код просто — пара недель на курсах, и вы «программист», но чтобы стать профи, который будет востребован всегда и везде, нужны фундаментальные знания. Здесь вы найдете только самую важную информацию, которая необходима каждому разработчику и программисту каждый день. cite
Владстон Феррейра Фило
Теоретический минимум по Computer Science [Все что нужно программисту и разработчику] - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Большие данные
Популярный в последнее время термин «большие данные» (big data) описывает ситуации обработки данных, которые чрезвычайно сложны с точки зрения объема, скорости или разнообразия [62] В профессиональных кругах это называется «три V»: volume (объем), velocity (скорость) и variety (разнообразие). Некоторые добавляют еще два аспекта: variability (переменчивость) и veracity (достоверность), превращая термин в «пять V».
. «Объем» больших данных — это, например, обработка тысяч терабайт информации в случае с БАК [63] Большой адронный коллайдер, или БАК, — это самый большой ускоритель частиц в мире. Во время эксперимента его датчики генерируют 1000 терабайт данных в секунду.
. «Скорость» применительно к большим данным означает, что вы должны сохранять миллион записей в секунду без задержек или быстро выполнять миллиарды запросов на чтение. «Разнообразие» означает, что данные не имеют строгой структуры, и потому становится очень трудно с ними справляться, используя традиционные реляционные базы данных.
Каждый раз, когда вам требуется искать нестандартный подход к управлению данными по причине их объема, скорости или разнообразия, вы можете смело сказать, что имеете дело с большими данными. Для выполнения некоторых современных научных экспериментов (к примеру, связанных с БАК или SKA [64] Антенная решетка площадью в квадратный километр, или SKA (от англ. Square Kilometer Array), — это группа телескопов, которые планируется ввести в строй в 2020 году. Они будут генерировать 1 млн терабайт данных каждый день.
) специалисты уже проводят исследования в области мегаданных , предполагающей хранение и анализ миллионов терабайт информации.
Большие данные часто связаны с нереляционными базами данных из-за их повышенной гибкости. Многие типы приложений, работающих с большими данными, практически невозможно реализовать при помощи реляционных баз данных.
SQL против NoSQL
Реляционные БД ориентированы на данные: они максимизируют структурирование данных и устраняют их дублирование независимо от того, в каком виде те требуются. Нереляционные БД, напротив, ориентированы на применение: они облегчают доступ к данным и их использование в соответствии с вашими потребностями.
Мы видели, что базы данных NoSQL позволяют быстро и эффективно сохранять крупные, изменчивые и неструктурированные данные. Не беспокоясь о фиксированных схемах и миграциях схемы, вы можете разрабатывать свои решения гораздо быстрее. Нереляционные базы данных для многих программистов естественней и проще.
Однако нужно помнить: какой бы крутой ни была ваша нереляционная база данных, ответственность за обновление дублированной информации по всем документам и коллекциям лежит только на вас . Только вы должны принимать меры для поддержания информации в непротиворечивом состоянии. Запомните: большая мощь этих БД идет рука об руку с большой ответственностью.
6.3. Распределенная модель
Существует несколько ситуаций, в которых для поддержания базы данных должен работать не один компьютер, а несколько, действующих координированно.
• Базы данных объемом в нескольких сотен терабайт. Найти одиночный компьютер с таким большим пространством хранения нереально.
• СУБД, обрабатывающие несколько тысяч одновременных запросов в секунду [65] Сразу после финального матча на чемпионате мира 2014 года по футболу Twitter испытал пиковую нагрузку в более чем 10 000 твитов в секунду.
. Никакой одиночный компьютер не имеет достаточных возможностей по передаче данных по сети или по их обработке, чтобы справиться с такой нагрузкой.
• Жизненно важные базы данных, как, например, те, что регистрируют высоту и скорость самолета, находящегося в конкретном воздушном пространстве. Полагаться на одиночный компьютер в этом случае слишком рискованно — если он выйдет из строя, база данных станет недоступной.
Для таких ситуаций существуют СУБД, способные работать на нескольких скоординированных компьютерах, образующие распределенные базы данных . Давайте рассмотрим наиболее распространенные способы организации таких БД.
Репликация с одним ведущим
Один компьютер является ведущим и получает все запросы к базе данных. Он подключен к нескольким другим, ведомым компьютерам. Каждый из них содержит реплику, или копию, базы данных. Когда ведущий компьютер получает запросы на запись, он направляет их ведомым, обеспечивая их синхронизацию (рис. 6.8).
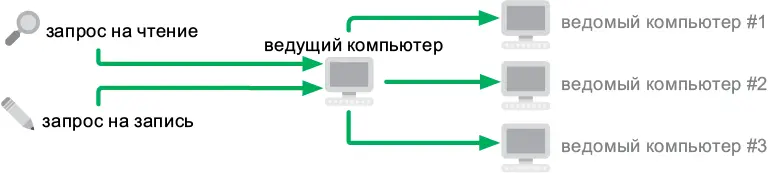
Рис. 6.8.Распределенная база данных с одним ведущим компьютером
При такой организации ведущий компьютер способен обслужить больше запросов на чтение, потому что может делегировать их ведомым компьютерам. Система становится надежнее: если основной компьютер выключается, ведомые машины автоматически координируются и выбирают новый ведущий компьютер. Благодаря этому система не прекращает свою работу.
Репликация с многочисленными ведущими
Если ваша СУБД должна обрабатывать большое количество одновременных запросов на запись, то один-единственный ведущий компьютер не справится с этой задачей. В таком случае все компьютеры в кластере становятся ведущими. Для равного распределения входящих запросов на чтение и запись между машинами используется балансировщик нагрузки (рис. 6.9).
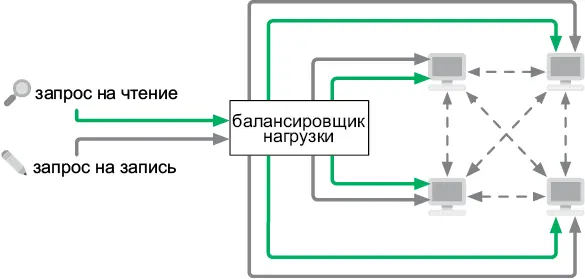
Рис. 6.9.Распределенная база данных с многочисленными ведущими машинами
Каждый компьютер подключен ко всем остальным, находящимся в кластере. Они делят запросы на запись между собой, в результате чего все остаются синхронизованными. Каждый из них имеет копию всей базы данных.
Фрагментирование
Если БД получает много запросов на запись с большими объемами данных, бывает чрезвычайно трудно синхронизировать ее везде в кластере. Некоторые компьютеры могут не иметь достаточного пространства для размещения всех данных полностью. Одно из решений состоит в том, чтобы поделить базу данных между компьютерами. Поскольку каждый из них владеет лишь ее частью, маршрутизатор направляет запросы соответствующей машине (рис. 6.10).
Такая конфигурация способна обрабатывать многочисленные запросы на чтение и запись в случае с очень большими базами данных. Но с ней возможна проблема: если машина в кластере выходит из строя, фрагмент данных, за который она отвечала, становится недоступен. Для снижения риска фрагментирование можно использовать в сочетании с репликацией (рис. 6.11).
Читать дальшеИнтервал:
Закладка:









