Энтони Уильямс - Параллельное программирование на С++ в действии. Практика разработки многопоточных программ

- Название:Параллельное программирование на С++ в действии. Практика разработки многопоточных программ
- Автор:
- Жанр:
- Издательство:ДМК Пресс
- Год:2012
- Город:Москва
- ISBN:978-5-94074-448-1
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Энтони Уильямс - Параллельное программирование на С++ в действии. Практика разработки многопоточных программ краткое содержание
Книга «Параллельное программирование на С++ в действии» не предполагает предварительных знаний в этой области. Вдумчиво читая ее, вы научитесь писать надежные и элегантные многопоточные программы на С++11. Вы узнаете о том, что такое потоковая модель памяти, и о том, какие средства поддержки многопоточности, в том числе запуска и синхронизации потоков, имеются в стандартной библиотеке. Попутно вы познакомитесь с различными нетривиальными проблемами программирования в условиях параллелизма.
Параллельное программирование на С++ в действии. Практика разработки многопоточных программ - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
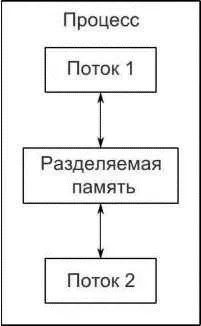
Рис. 1.4. Коммуникация между двумя параллельно исполняемыми потоками в одном процессе
Благодаря общему адресному пространству и отсутствию защиты данных от доступа со стороны разных потоков накладные расходы, связанные с наличием нескольких потоков, существенно меньше, так как на долю операционной системы выпадает гораздо меньше учетной работы, чем в случае нескольких процессов. Однако же за гибкость разделяемой памяти приходится расплачиваться — если к некоторому элементу данных обращаются несколько потоков, то программист должен обеспечить согласованность представления этого элемента во всех потоках. Возникающие при этом проблемы, а также средства и рекомендации по их разрешению рассматриваются на протяжении всей книги, а особенно в главах 3, 4, 5 и 8. Эти проблемы не являются непреодолимыми, надо лишь соблюдать осторожность при написании кода. Но само их наличие означает, что коммуникацию между потоками необходимо тщательно продумывать.
Низкие накладные расходы на запуск потоков внутри процесса и коммуникацию между ними стали причиной популярности этого подхода во всех распространенных языках программирования, включая С++, даже несмотря на потенциальные проблемы, связанные с разделением памяти. Кроме того, в стандарте С++ не оговаривается встроенная поддержка межпроцессной коммуникации, а, значит, приложения, основанные на применении нескольких процессов, вынуждены полагаться на платформенно-зависимые API. Поэтому в этой книге мы будем заниматься исключительно параллелизмом на основе многопоточности, и в дальнейшем всякое упоминание о параллелизме предполагает использование нескольких потоков.
Определившись с тем, что понимать под параллелизмом, посмотрим, зачем он может понадобиться в приложениях.
1.2. Зачем нужен параллелизм?
Существует две основных причины для использования параллелизма в приложении: разделение обязанностей и производительность. Я бы даже рискнул сказать, что это единственные причины — если внимательно приглядеться, то окажется, что все остальное сводится к одной или к другой (или к обеим сразу). Ну, конечно, если не рассматривать в качестве аргумента «потому что я так хочу».
1.2.1. Применение параллелизма для разделения обязанностей
Разделение обязанностей почти всегда приветствуется при разработке программ: если сгруппировать взаимосвязанные и разделить несвязанные части кода, то программа станет проще для понимания и тестирования и, стало быть, будет содержать меньше ошибок. Использовать распараллеливание для разделения функционально не связанных между собой частей программы имеет смысл даже, если относящиеся к разным частям операции должны выполняться одновременно: без явного распараллеливания нам пришлось бы либо реализовать какую-то инфраструктуру переключения задач, либо то и дело обращаться к коду из посторонней части программы во время выполнения операции.
Рассмотрим приложение, имеющее графический интерфейс и выполняющее сложные вычисления, например DVD-проигрыватель на настольном компьютере. У такого приложения два принципиально разных набора обязанностей: во-первых, читать данные с диска, декодировать изображение и звук и своевременно посылать их графическому и звуковому оборудованию, чтобы при просмотре фильма не было заминок, а, во-вторых, реагировать на действия пользователя, например, на нажатие кнопок «Пауза», «Возврат в меню» и даже «Выход». Если бы приложение было однопоточным, то должно было бы периодически проверять, не было ли каких-то действий пользователя, поэтому код воспроизведения DVD перемежался бы кодом, относящимся к пользовательскому интерфейсу Если же для разделения этих обязанностей использовать несколько потоков, то код интерфейса и воспроизведения уже не будут так тесно переплетены: один поток может заниматься отслеживанием действий пользователя, а другой - воспроизведением. Конечно, как-то взаимодействовать они все равно должны, например, если пользователь нажимает кнопку «Пауза», но такого рода взаимодействия непосредственно связаны с решаемой задачей.
В результате мы получаем «отзывчивый» интерфейс, так как поток пользовательского интерфейса обычно способен немедленно отреагировать на запрос пользователя, даже если реакция заключается всего лишь в смене формы курсора на «занято» или выводе сообщения «Подождите, пожалуйста» на время, требуемое для передачи запроса другому потоку для обработки. Аналогично, несколько потоков часто создаются для выполнения постоянно работающих фоновых задач, например, мониторинга изменений файловой системы в приложении локального поиска. Такое использование потоков позволяет существенно упростить логику каждого потока, так как взаимодействие между ними ограничено немногими четко определенными точками, а не размазано по всей программе.
В данном случае количество потоков не зависит от количества имеющихся процессорных ядер, потому что программа разбивается на потоки ради чистоты дизайна, а не в попытке увеличить производительность.
1.2.2. Применение параллелизма для повышения производительности
Многопроцессорные системы существуют уже десятки лет, но до недавнего времени они использовались исключительно в суперкомпьютерах, больших ЭВМ и крупных серверах. Однако ныне производители микропроцессоров предпочитают делать процессоры с 2, 4, 16 и более ядрами на одном кристалле, а не наращивать производительность одного ядра. Поэтому все большее распространение получают настольные компьютеры и даже встраиваемые устройства с многоядерными процессорами. Увеличение вычислительной мощи в этом случае связано не с тем, что каждая отдельная задача работает быстрее, а с тем, что несколько задач исполняются параллельно.
В прошлом программист мог откинуться на спинку стула и наблюдать, как его программа работает все быстрее с каждым новым поколением процессоров, без каких-либо усилий с его стороны. Но теперь, как говорит Герб Саттер, «время бесплатных завтраков закончилось» [Sutter 2005]. Если требуется, чтобы программа выигрывала от увеличения вычислительной мощности, то ее необходимо проектировать как набор параллельных задач . Поэтому программистам придется подтянуться, и те, кто до сих пор не обращал внимания на параллелизм, должны будут добавить его в свой арсенал.
Существует два способа применить распараллеливание для повышения производительности. Первый, самый очевидный, разбить задачу на части и запустить их параллельно, уменьшив тем самым общее время выполнения. Это распараллеливание по задачам . Хотя эта процедура и представляется простой, на деле все может сильно усложниться из-за наличия многочисленных зависимостей между разными частями. Разбиение можно формулировать как в терминах обработки: один поток выполняет одну часть обработки, другой — другую, так и в терминах данных: каждый поток выполняет одну и ту же операцию, но с разными данными. Последний вариант называется распараллеливание по данным .
Читать дальшеИнтервал:
Закладка: