Энтони Уильямс - Параллельное программирование на С++ в действии. Практика разработки многопоточных программ

- Название:Параллельное программирование на С++ в действии. Практика разработки многопоточных программ
- Автор:
- Жанр:
- Издательство:ДМК Пресс
- Год:2012
- Город:Москва
- ISBN:978-5-94074-448-1
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Энтони Уильямс - Параллельное программирование на С++ в действии. Практика разработки многопоточных программ краткое содержание
Книга «Параллельное программирование на С++ в действии» не предполагает предварительных знаний в этой области. Вдумчиво читая ее, вы научитесь писать надежные и элегантные многопоточные программы на С++11. Вы узнаете о том, что такое потоковая модель памяти, и о том, какие средства поддержки многопоточности, в том числе запуска и синхронизации потоков, имеются в стандартной библиотеке. Попутно вы познакомитесь с различными нетривиальными проблемами программирования в условиях параллелизма.
Параллельное программирование на С++ в действии. Практика разработки многопоточных программ - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
Простейший способ распределения данных заключается в том, чтобы назначить первые N элементов одному потоку, следующие N — другому и так далее, как показано на рис. 8.1, хотя это и не единственное решение. Как бы ни были распределены данные, каждый поток обрабатывает только назначенные ему элементы, никак не взаимодействуя с другими потоками до тех пор, пока не завершит обработку.
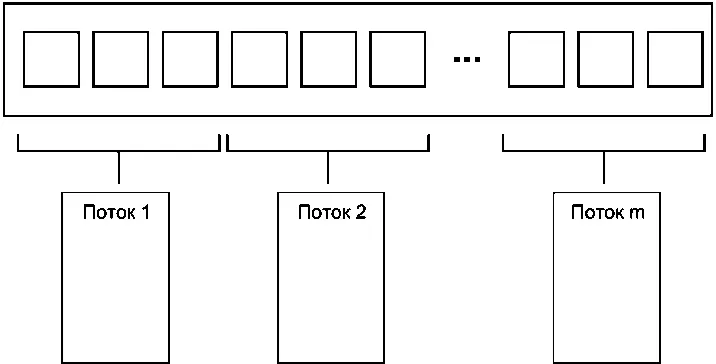
Рис. 8.1.Распределение последовательных блоков данных между потоками
Такая организация программы знакома каждому, кто программировал в системах Message Passing Interface (МРI) [17] http://www.mpi-forum.org/
или OpenMP [18] http://www.openmp.org/
: задача разбивается на множество параллельных подзадач, рабочие потоки выполняют их параллельно, а затем результаты объединяются на стадии редукции . Этот подход применён в примере функции accumulateиз раздела 2.4; в данном случае и параллельные задачи, и финальный шаг редукции представляют собой аккумулирование. Для простого алгоритма for_eachфинальный шаг отсутствует, так как нечего редуцировать.
Понимание того, что последний шаг является редукцией, важно; в наивной реализации, представленной в листинге 2.8, финальная редукция выполняется как последовательная операция. Однако часто и ее можно распараллелить; операция accumulateпо сути дела сама является редукцией, поэтому функцию из листинга 2.8 можно модифицировать таким образом, чтобы она вызывала себя рекурсивно, если, например, число потоков больше минимального количества элементов, обрабатываемых одним потоком. Или запрограммировать рабочие потоки так, чтобы по завершении задачи они выполняли некоторые шаги редукции, а не запускать каждый раз новые потоки.
Хотя это действенная техника, применима она не в любой ситуации. Иногда данные не удается заранее распределить равномерно, а как это сделать, становится понятно только в процессе обработки. Особенно наглядно это проявляется в таких рекурсивных алгоритмах, как Quicksort; здесь нужен другой подход.
8.1.2. Рекурсивное распределение данных
Алгоритм Quicksort состоит из двух шагов: разбиение данных на две части — до и после опорного элемента в смысле требуемого упорядочения, и рекурсивная сортировка обеих «половин». Невозможно распараллелить этот алгоритм, разбив данные заранее, потому что состав каждой «половины» становится известен только в процессе обработки элементов. Поэтому распараллеливание по необходимости должно быть рекурсивным. На каждом уровне рекурсии производится больше вызовов функции quick_sort, потому что предстоит отсортировать элементы, меньшие опорного, и большие опорного. Эти рекурсивные вызовы не зависят друг от друга, так как обращаются к разным элементам, поэтому являются идеальными кандидатами для параллельного выполнения. На рис. 8.2 изображено такое рекурсивное разбиение.
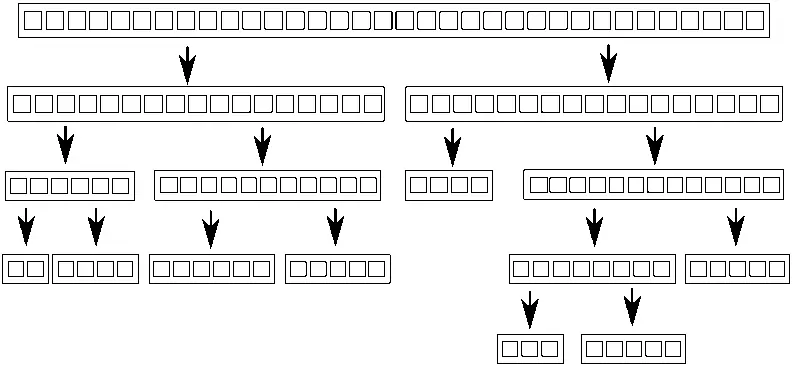
Рис. 8.2.Рекурсивное разбиение данных
В главе 4 была приведена подобная реализация. Вместо того чтобы просто вызывать функцию рекурсивно для большей и меньшей «половины», мы с помощью std::async()на каждом шаге запускали асинхронную задачу для меньшей половины. Вызывая std::async(), мы просим стандартную библиотеку С++ самостоятельно решить, имеет ли смысл действительно выполнять задачу в новом потоке или лучше сделать это синхронно.
Это существенно: при сортировке большого набора данных запуск нового потока для каждого рекурсивного вызова быстро приводит к образованию чрезмерного количества потоков. Как мы увидим ниже, когда потоков слишком много, производительность может не возрасти, а наоборот упасть . Кроме того, если набор данных очень велик, то потоков может просто не хватить. Сама идея рекурсивного разбиения на задачи хороша, нужно только строже контролировать число запущенных потоков. В простых случаях с этим справляется std::async(), но есть и другие варианты.
Один из них — воспользоваться функцией std::thread::hardware_concurrency()для выбора нужного числа потоков, как мы делали в параллельной версии accumulate()из листинга 2.8. Тогда вместо того чтобы запускать новый поток для каждого рекурсивного вызова, мы можем просто поместить подлежащий сортировке блок данных в потокобезопасный стек типа того, что был описан в главах 6 и 7. Если потоку больше нечего делать — потому что он закончил обработку всех своих блоков или потому что ждет, когда необходимый ему блок будет отсортирован, то он может взять блок из стека и заняться его сортировкой.
В следующем листинге показана реализация этой идеи.
Листинг 8.1.Параллельный алгоритм Quicksort с применением стека блоков, ожидающих сортировки
template
struct sorter { ← (1)
struct chunk_to_sort {
std::list data;
std::promise > promise;
};
thread_safe_stack chunks; ← (2)
std::vector threads; ← (3)
unsigned const max_thread_count;
std::atomic end_of_data;
sorter():
max_thread_count(std::thread::hardware_concurrency() - 1),
end_of_data(false) {}
~sorter() { ← (4)
end_of_data = true; ← (5)
for (unsigned i = 0; i < threads.size(); ++i) {
threads[i].join(); ← (6)
}
}
void try_sort_chunk() {
boost::shared_ptr chunk = chunks.pop();← (7)
if (chunk) {
sort_chunk(chunk); ← (8)
}
}
std::list do_sort(std::list& chunk_data) { ← (9)
if (chunk_data.empty()) {
return chunk_data;
}
std::list result;
result.splice(result.begin(), chunk_data, chunk_data.begin());
T const& partition_val = *result.begin();
typename std::list::iterator divide_point = ← (10)
std::partition(chunk_data.begin(), chunk_data.end(),
[&](T const& val) {return val < partition_val; });
chunk_to_sort new_lower_chunk;
new_lower_chunk.data.splice(new_lower_chunk.data.end(),
chunk_data, chunk_data.begin(),
divide_point);
std::future > new_lower =
new_lower_chunk.promise.get_future();
chunks.push(std::move(new_lower_chunk)); ← (11)
if (threads.size() < max_thread_count) { ← (12)
threads.push_back(std::thread(&sorter::sort_thread, this));
}
std::list new_higher(do_sort(chunk_data));
result.splice(result.end(), new_higher);
while (new_lower.wait_for(std::chrono::seconds(0)) !=
std::future_status::ready) { ← (13)
try_sort_chunk(); ← (14)
}
result.splice(result.begin(), new_lower.get());
return result;
}
void sort_chunk(boost::shared_ptr const& chunk) {
chunk->promise.set_value(do_sort(chunk->data));← (15)
}
void sort_thread() {
while (!end_of_data) { ← (16)
try_sort_chunk(); ← (17)
Интервал:
Закладка: