Алексей Молчанов - Системное программное обеспечение. Лабораторный практикум

- Название:Системное программное обеспечение. Лабораторный практикум
- Автор:
- Жанр:
- Издательство:Array Издательство «Питер»
- Год:2005
- Город:Санкт-Петербург
- ISBN:978-5-469-00391-4
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Алексей Молчанов - Системное программное обеспечение. Лабораторный практикум краткое содержание
Книга ориентирована на студентов, обучающихся в технических вузах по специальностям, связанным с вычислительной техникой. Но она будет также полезна всем, чья деятельность так или иначе касается разработки программного обеспечения.
Системное программное обеспечение. Лабораторный практикум - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
8. Во всем множестве правил Р грамматики G(VT,VN,P,S) ищется правило, у которого правая часть совпадает с цепочкой γ (по условиям грамматик предшествования все правые части правил должны быть различны, поэтому может быть найдено или одно такое правило, или ни одного). Если правило найдено, то в стек помещается нетерминальный символ из левой части правила, иначе, если правило не найдено, это значит, что входная строка символов не принимается МП-автоматом, алгоритм прерывается и выдает сообщение об ошибке. Следует отметить, что при выполнении свертки считывающая головка автомата не сдвигается и текущий входной символ a iостается неизменным. После выполнения свертки необходимо вернуться к шагу 2.
После завершения алгоритма решение о принятии цепочки зависит от содержимого стека. Автомат принимает цепочку, если в результате завершения алгоритма он находится в состоянии, когда в стеке находятся начальный символ грамматики S и символ
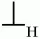
Выполнение алгоритма может быть прервано, если на одном из его шагов возникнет ошибка. Тогда входная цепочка не принимается.
Алгоритм «сдвиг-свертка» для грамматики операторного предшествования игнорирует нетерминальные символы. Поэтому имеет смысл преобразовать исходную грамматику таким образом, чтобы оставить в ней только один нетерминальный символ. Это преобразование заключается в том, что все нетерминальные символы в правилах грамматики заменяются на один нетерминальный символ (чаще всего – целевой символ грамматики).
Построенная в результате такого преобразования грамматика называется остовной грамматикой, а само преобразование – остовным преобразованием [1, 7].
Остовное преобразование не ведет к созданию эквивалентной грамматики и выполняется только для упрощения работы алгоритма (который при выборе правил все равно игнорирует нетерминальные символы) после построения матрицы предшествования. Полученная в результате остовного преобразования грамматика может не являться однозначной, но все необходимые данные о порядке применения правил содержатся в матрице предшествования и распознаватель остается детерминированным. Поэтому остовное преобразование может выполняться без потерь информации только после построения матрицы предшествования. При этом также необходимо следить, чтобы в грамматике не возникло неоднозначностей из-за одинаковых правых частей правил, которые могут появиться в остовной грамматике. Вывод, полученный при разборе на основе остовной грамматики, называют результатом остовного разбора, или остовным выводом.
По результатам остовного разбора можно построить соответствующий ему вывод на основе правил исходной грамматики. Однако эта задача не представляет практического интереса, поскольку остовной вывод отличается от вывода на основе исходной грамматики только тем, что в нем отсутствуют шаги, связанные с применением цепных правил, и не учитываются типы нетерминальных символов. Для компиляторов же распознавание цепочек входного языка заключается не в нахождении того или иного вывода, а в выявлении основных синтаксических конструкций исходной программы с целью построения на их основе цепочек языка результирующей программы. В этом смысле типы нетерминальных символов и цепные правила не несут никакой полезной информации, а напротив, только усложняют обработку цепочки вывода. Поэтому для реального компилятора нахождение остовного вывода является даже более полезным, чем нахождение вывода на основе исходной грамматики. Найденный остовной вывод в дальнейших преобразованиях уже не нуждается. [4]
В общем виде последовательность построения распознавателя для КС-грамматики операторного предшествования G(VT,VN,P,S) можно описать следующим образом:
1. На основе множества правил грамматики Р построить множества крайних левых и крайних правых символов для всех нетерминальных символов грамматики
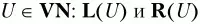
2. На основе множества правил грамматики Р и построенных на шаге 1 множеств L(U) и R(U) построить множества крайних левых и крайних правых терминальных символов для всех нетерминальных символов грамматики
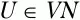
: L t(U) и R t(U).
3. На основе построенных на шаге 2 множеств L t(U) и R t(U) для всех терминальных символов грамматики
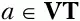
заполняется матрица операторного предшествования.
4. Исходная грамматика G(VT,VN,P,S) преобразуется в остовную грамматику G'(VT,{S},P,S) с одним нетерминальным символом.
5. На основе построенной матрицы предшествования и остовной грамматики строится распознаватель на базе алгоритма «сдвиг-свертка» для грамматик операторного предшествования.
Важно, что алгоритм распознавателя может быть реализован вне зависимости от матрицы предшествования и правил исходной грамматики. Тогда, меняя матрицу и правила, один и тот же алгоритм можно использовать для распознавания входных цепочек любой грамматики операторного предшествования.
Далее в примере выполнения работы проиллюстрирован именно такой подход к построению распознавателя.
Требования к выполнению работы
Порядок выполнения работы
Для выполнения лабораторной работы требуется написать программу, которая выполняет лексический анализ входного текста в соответствии с заданием, порождает таблицу лексем и выполняет синтаксический разбор текста по заданной грамматике с построением дерева разбора. Текст на входном языке задается в виде символьного (текстового) файла. Синтаксис входного языка и перечень допустимых лексем указаны в задании. Допускается исходить из условия, что текст содержит не более одного предложения входного языка.
При наличии во входном файле текста, соответствующего заданному языку, программа должна строить и отображать дерево синтаксического разбора. Если же текст во входном файле содержит ошибки (лексические или синтаксические), программа должна выдавать сообщения о наличии ошибок во входном тексте и корректно завершать свое выполнение.
Рекомендуется разбить программу на три составные части: лексический анализ, построение цепочки вывода и построение дерева вывода. Лексический анализатор должен выделять в тексте лексемы языка и заменять их на терминальный символ грамматики (который в задании обозначен как a). Полученная после лексического анализа цепочка должна рассматриваться во второй части программы в соответствии с алгоритмом разбора. При неудачном завершении алгоритма выдается сообщение об ошибке, при удачном – строится цепочка вывода. После построения цепочки вывода на ее основе строится дерево разбора, в котором символы a последовательно заменяются на лексемы из таблицы лексем.
Читать дальшеИнтервал:
Закладка: