Дмитрий Красота - Введение в Python

- Название:Введение в Python
- Автор:
- Жанр:
- Издательство:неизвестно
- Год:неизвестен
- ISBN:нет данных
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Дмитрий Красота - Введение в Python краткое содержание
--------
Файл изготовлен по материалам сайта http://pythonicway.com/
Введение в Python - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
Возьмем в качестве примера следующий скрипт. Программа спрашивает у пользователя число и делит сто на это число:
1 | a = float(input("Введите число "))
2 | print (100 / a)
Если пользователь введет информацию, которую мы от него ожидаем, то все сработает как нужно.
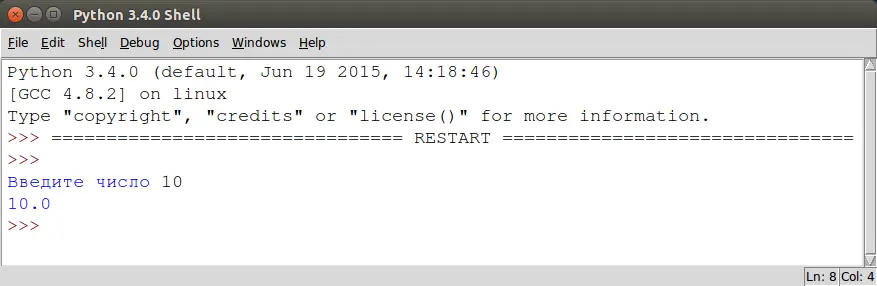
Вот что произойдет просто потому, что мы не учли, что на ноль делить нельзя.
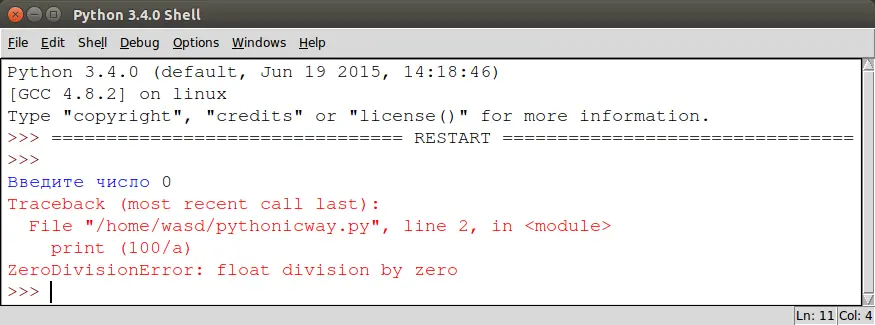
А вот что случится, если кто-то специально попытается поломать программу.
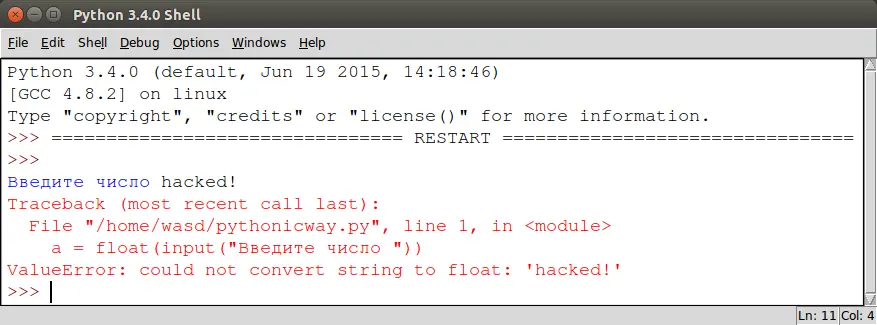
Чем сложнее программа, тем больше у нее уязвимых мест, которые вам придется учитывать в процессе разработки. Pythonпредлагает следующий механизм обработки исключительных ситуаций.
Уязвимый код заключается в блок try, после которого следует блок except, которому может задаваться возможная ошибка и реакция на нее:
1 | try:
2 | a =float(input("Введите число: "))
3 | except ValueError:
4 | print ("Это не число!")
В данном примере программа пытается конвертировать информацию введенную пользователем в тип float, если же при этом возникнет ошибка класса ValueError, то выводится строка "This is not a valid number". В блоке except мы можем задать те классы ошибок на которые данный блок должен сработать, если мы не укажем ожидаемый класс ошибок, то блок будет реагировать на любую возникшую ошибку.
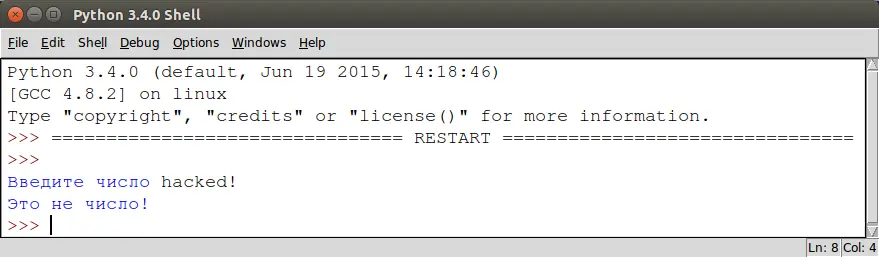
Блок try может содержать неограниченное количество блоков except:
1 | try:
2 | a =float(input ("Введите число: ")
3 | print (100 / a)
4 | except ValueError:
5 | print ("Это не число")
6 | except ZeroDivisionError:
7 | print ("На ноль делить нельзя")
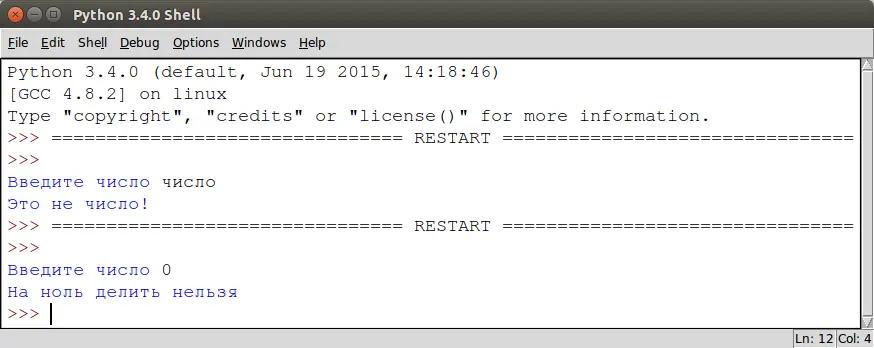
Кроме того мы можем добавить пустой блок except, который будет срабатывать на непредвиденную выше ошибку. Пустой блок except всегда должен идти последним:
1 | try:
2 | a =float(input ("Введите число: ")
3 | print (100 / a)
4 | except ValueError:
5 | print ("Это не число")
6 | except ZeroDivisionError:
7 | print ("На ноль делить нельзя")
8 | except:
9 | print ("Неожиданная ошибка.")
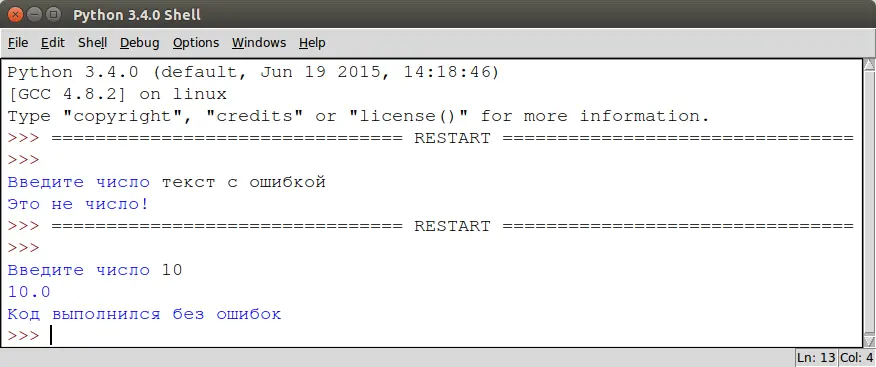
Блоку except можно добавить необязательный блок else, который сработает в случае, если программа выполнилась без ошибок:
1 | try:
2 | a =float(input ("Введите число: ")
3 | print (100 / a)
4 | except ValueError:
5 | print ("Это не число")
6 | except ZeroDivisionError:
7 | print ("На ноль делить нельзя")
8 | except:
9 | print ("Неожиданная ошибка.")
10 | else:
11 | print ("Код выполнился без ошибок")
В результате, мы получим следующее.
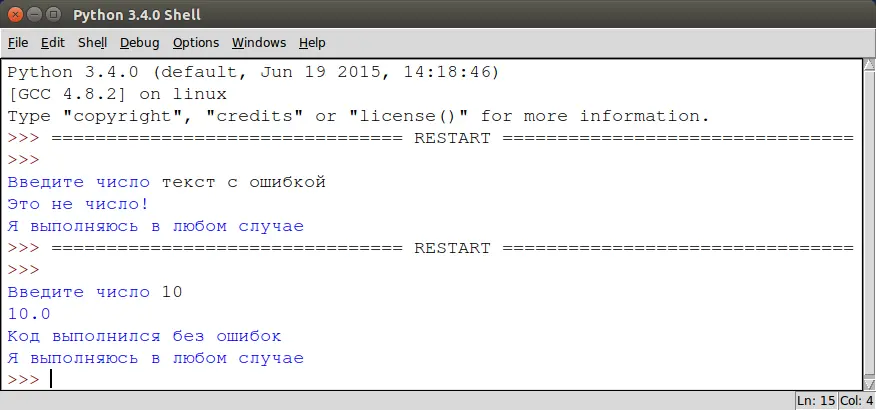
Также у блока except есть еще один необязательный блок finally, который сработает независимо от того, выполнился код с ошибками или без:
1 | try:
2 | a =float(input ("Введите число: ")
3 | print (100 / a)
4 | except ValueError:
5 | print ("Это не число")
6 | except ZeroDivisionError:
7 | print ("На ноль делить нельзя")
8 | except:
9 | print ("Неожиданная ошибка.")
10 | else:
11 | print ("Код выполнился без ошибок")
12 | finally:
13 | print ("Я выполняюсь в любом случае!")
Таким образом, используя обработку исключительных ситуаций, вы можете защитить программу от взлома, непредвиденного поведения и в будущем получить детальную информацию по логическим ошибкам, содержащимся в ней.
HTML парсер на Python
Published: 08 April 2015
Учитывая современное развитие Интернета, было бы кощунством не написать приложение, взаимодействующее со всемирной паутиной. Сегодня мы напишем простенький html-парсер на Python. Наше приложение будет читать код указанной страницы сайта и сохранять все ссылки в ней в отдельный файл. Это приложение может помочь SEO-аналитикам и веб-разработчикам.
Писать будем на Python 3, в котором есть встроенный класс для html-парсера из модуля html.parser
| from html.parser import HTMLParser
Так же нам понадобится функция urlopen из модуля urllib
| from urllib.request import urlopen
Именно функция urlopen будет получать исходный код указанной странички.
Наша задача таким образом перегрузить функционал существующего класса HTMLParser, чтобы он соответствовал нашей задаче.
| class MyHTMLParser(HTMLParser):
| def __init__(self, site_name, * args, * * kwargs):
| # список ссылок
| self.links = []
| # имя сайта
| self.site_name = site_name
| # вызываем __init__ родителя
| super().__init__( * args, * * kwargs)
| # при инициализации "скармливаем" парсеру содержимое страницы
| self.feed(self.read_site_content())
| # записываем список ссылок в файл
self.write_to_file()
Базовый класс HTMLParser имеет несколько методов, нас в данном случае интересуют метод handle_start_tag. Этот метод вызывается каждый раз, когда наш парсер встречает в тексте октрывающий html-тэг.
| def handle_starttag(self, tag, attrs):
| # проверяем является ли тэг тэгом ссылки
| if tag == 'a':
| # находим аттрибут адреса ссылки
| for attr in attrs:
| if attr[0] = = 'href':
| # проверяем эту ссылку методом validate() (мы его еще напишем)
| if not self.validate(attr[0]):
| # вставляем адрес в список ссылок
self.links.append(attr[1])
Напишем вспомогательный метод validate:
| def validate(self, link):
| """ Функция проверяет стоит ли добавлять ссылку в список адресов.
| В список адресов стоит добавлять если ссылка:
| 1) Еще не в списке ссылок
| 2) Не вызывает javascript-код
| 3) Не ведет к какой-либо метке. (Не содержит #)
| """
return link in self.links or'#'inlink or'javascript:' inlink
Создадим метод, который будет открывать указанную страницу и выдавать ее содержимое.
def read_site_content(self):
return str(urlopen(self.site_name).read())
Осталось добавить возможность записи списка ссылок на диск в читабельном формате:
| def write_to_file(self):
| # открываем файл
| f =open('links.txt', 'w')
Интервал:
Закладка:

