Миран Липовача - Изучай Haskell во имя добра!

- Название:Изучай Haskell во имя добра!
- Автор:
- Жанр:
- Издательство:ДМК Пресс
- Год:2012
- Город:Москва
- ISBN:978-5-94074-749-9
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Миран Липовача - Изучай Haskell во имя добра! краткое содержание
Язык Haskell имеет множество впечатляющих возможностей, но главное его свойство в том, что меняется не только способ написания кода, но и сам способ размышления о проблемах и возможных решениях. Этим Haskell действительно отличается от большинства языков программирования. С его помощью мир можно представить и описать нестандартным образом. И поскольку Haskell предлагает совершенно новые способы размышления о проблемах, изучение этого языка может изменить и стиль программирования на всех прочих.
Ещё одно необычное свойство Haskell состоит в том, что в этом языке придаётся особое значение рассуждениям о типах данных. Как следствие, вы помещаете больше внимания и меньше кода в ваши программы.
Вне зависимости от того, в каком направлении вы намерены двигаться, путешествуя в мире программирования, небольшой заход в страну Haskell себя оправдает. А если вы решите там остаться, то наверняка найдёте чем заняться и чему поучиться!
Эта книга поможет многим читателям найти свой путь к Haskell.
Отображения, монады, моноиды и другое! Всё сказано в названии: «Изучай Хаскель во имя добра!» – весёлый иллюстрированный самоучитель по этому сложному функциональному языку.
С помощью оригинальных рисунков автора, отсылке к поп-культуре, и, самое главное, благодаря полезным примерам кода, эта книга обучает основам функционального программирования так, как вы никогда не смогли бы себе представить.
Вы начнете изучение с простого материала: основы синтаксиса, рекурсия, типы и классы типов. Затем, когда вы преуспеете в основах, начнется настоящий мастер-класс от профессионала: вы изучите, как использовать аппликативные функторы, монады, застежки, и другие легендарные конструкции Хаскеля, о которых вы читали только в сказках.
Продираясь сквозь образные (и порой безумные) примеры автора, вы научитесь:
• Смеяться в лицо побочным эффектам, поскольку вы овладеете техниками чистого функционального программирования.
• Использовать волшебство «ленивости» Хаскеля для игры с бесконечными наборами данных.
• Организовывать свои программы, создавая собственные типы, классы типов и модули.
• Использовать элегантную систему ввода-вывода Хаскеля, чтобы делиться гениальностью ваших программ с окружающим миром.
Нет лучшего способа изучить этот мощный язык, чем чтение «Изучай Хаскель во имя добра!», кроме, разве что, поедания мозга его создателей. Миран Липовача (Miran Lipovača) изучает информатику в Любляне (Словения). Помимо его любви к Хаскелю, ему нравится заниматься боксом, играть на бас-гитаре и, конечно же, рисовать. У него есть увлечение танцующими скелетами и числом 71, а когда он проходит через автоматические двери, он притворяется, что на самом деле открывает их силой своей мысли.
Изучай Haskell во имя добра! - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Алгоритм
Итак, сигнатура функции будет следующей:
quicksort :: (Ord a) => [a] –> [a]
Ничего удивительного тут нет. Базовый случай? Пустой список, как и следовало ожидать. Отсортированный пустой список – это пустой список. Затем следует основной алгоритм: отсортированный список – это список, в котором все элементы, меньшие либо равные «голове» списка, идут впереди (в отсортированном порядке), посередине следует «голова» списка, а потом – все элементы, большие «головы» списка (также отсортированные). Заметьте, в определении мы упомянули сортировку дважды, так что нам, возможно, придётся делать два рекурсивных вызова в теле функции. Также обратите внимание на то, что мы описали алгоритм, просто дав определение отсортированному списку. Мы не указывали явно: «делай это, затем делай то…» В этом красота функционального программирования! Как нам отфильтровать список, чтобы получить только те элементы, которые больше «головы» списка, и те, которые меньше? С помощью генераторов списков.
Если у нас, скажем, есть список [5,1,9,4,6,7,3]и мы хотим отсортировать его, этот алгоритм сначала возьмёт «голову», которая равна 5, и затем поместит её в середину двух списков, где хранятся элементы меньшие и большие «головы» списка. То есть в нашем примере получается следующее: [1,4,3] ++ [5] ++ [9,6,7]. Мы знаем, что когда список будет отсортирован, число 5будет находиться на четвёртой позиции, потому что есть три числа меньше и три числа больше 5. Теперь, если мы отсортируем списки [1,4,3]и [9,6,7], то получится отсортированный список! Мы сортируем эти два списка той же самой функцией. Рано или поздно мы достигнем пустого списка, который уже отсортирован – в силу своей пустоты. Проиллюстрируем (цветной вариант рисунка приведён на форзаце книги):
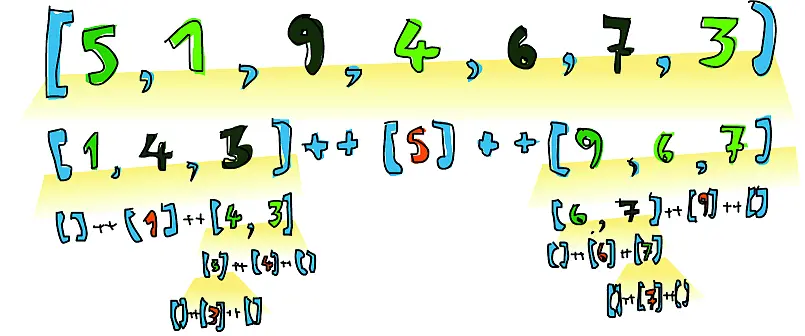
Элемент, который расположен на своём месте и больше не будет перемещаться, выделен оранжевым цветом. Если вы просмотрите элементы слева направо, то обнаружите, что они отсортированы. Хотя мы решили сравнивать все элементы с «головами», можно использовать и другие элементы для сравнения. В алгоритме быстрой сортировки элемент, с которым производится сравнение, называется опорным . На нашей картинке такие отмечены зелёным цветом. Мы выбрали головной элемент в качестве опорного, потому что его легко получить при сопоставлении с образцом. Элементы, которые меньше опорного, обозначены светло-зелёным цветом; элементы, которые больше, – темно-зелёным. Желтоватый градиент демонстрирует применение быстрой сортировки.
Определение
quicksort :: (Ord a) => [a] –> [a]
quicksort [] = []
quicksort (x:xs) =
let smallerSorted = quicksort [a | a <���– xs, a <= x]
biggerSorted = quicksort [a | a <���– xs, a > x]
in smallerSorted ++ [x] ++ biggerSorted
Давайте немного «погоняем» функцию – так сказать, испытаем её в действии:
ghci> quicksort [10,2,5,3,1,6,7,4,2,3,4,8,9]
[1,2,2,3,3,4,4,5,6,7,8,9,10]
ghci> quicksort "съешь ещё этих мягких французских булок, да выпей чаю"
" ,ааабвгдеееёзииийккклмнопрсстууфхххцчшщъыьэюя"
Ура! Это именно то, чего я хотел!
Думаем рекурсивно
Мы уже много раз использовали рекурсию, и, как вы, возможно, заметили, тут есть определённый шаблон. Обычно вы определяете базовые случаи, а затем задаёте функцию, которая что-либо делает с рядом элементов, и функцию, применяемую к оставшимся элементам. Неважно, список ли это, дерево либо другая структура данных. Сумма – это первый элемент списка плюс сумма оставшейся его части. Произведение списка – это первый его элемент, умноженный на произведение оставшейся части. Длина списка – это единица плюс длина «хвоста» списка. И так далее, и тому подобное…

Само собой разумеется, у всех упомянутых функций есть базовые случаи. Обычно они представляют собой некоторые сценарии выполнения, при которых применение рекурсивного вызова не имеет смысла. Когда имеешь дело со списками, это, как правило, пустой список. Когда имеешь дело с деревьями, это в большинстве случаев узел, не имеющий потомков.
Похожим образом обстоит дело, если вы рекурсивно обрабатываете числа. Обычно мы работаем с неким числом, и функция применяется к тому же числу, но модифицированному некоторым образом. Ранее мы написали функцию для вычисления факториала – он равен произведению числа и факториала от того же числа, уменьшенного на единицу. Такой рекурсивный вызов не имеет смысла для нуля, потому что факториал не определён для отрицательных чисел. Часто базовым значением становится нейтральный элемент. Нейтральный элемент для умножения – 1, так как, умножая нечто на 1, вы получаете это самое нечто. Таким же образом при суммировании списка мы полагаем, что сумма пустого списка равна нулю, нуль – нейтральный элемент для сложения. В быстрой сортировке базовый случай – это пустой список; он же является нейтральным элементом, поскольку если присоединить пустой список к некоторому списку, мы снова получим исходный список.
Итак, пытаясь мыслить рекурсивным образом при решении задачи, попробуйте придумать, в какой ситуации рекурсивное решение не подойдёт, и понять, можно ли использовать этот вариант как базовый случай. Подумайте, что является нейтральным элементом, как вы будете разбивать параметры функции (например, списки обычно разбивают на «голову» и «хвост» путём сопоставления с образцом) и для какой части примените рекурсивный вызов.
5
Функции высшего порядка
Функции в языке Haskell могут принимать другие функции как параметры и возвращать функции в качестве результата. Если некая функция делает что-либо из вышеперечисленного, её называют функцией высшего порядка (ФВП). ФВП – не просто одна из значительных особенностей характера программирования, присущего языку Haskell, – она по большей части и определяет этот характер. Как выясняется, ФВП незаменимы, если вы хотите программировать исходя из того, что вы хотите получить, вместо того чтобы продумывать последовательность шагов, описывающую, как это получить. Это очень мощный способ решения задач и разработки программ.
Каррированные функции

Каждая функция в языке Haskell официально может иметь только один параметр. Но мы определяли и использовали функции, которые принимали несколько параметров. Как же такое может быть? Да, это хитрый трюк! Все функции, которые принимали несколько параметров, были каррированы . Функция называется каррированной, если она всегда принимает только один параметр вместо нескольких. Если потом её вызвать, передав этот параметр, то результатом вызова будет новая функция, принимающая уже следующий параметр.
Читать дальшеИнтервал:
Закладка:

