Денис Соломатин - Основы статистической обработки педагогической информации

- Название:Основы статистической обработки педагогической информации
- Автор:
- Жанр:
- Издательство:неизвестно
- Год:2020
- ISBN:978-5-532-04389-3
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Денис Соломатин - Основы статистической обработки педагогической информации краткое содержание
Основы статистической обработки педагогической информации - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Модулярная арифметика: %/% (целочисленное деление) и %% (остаток), здесь x == y * (x %/% y) + (x %% y). Модулярная арифметика очень удобный инструмент, потому что позволяет представлять большие целые числа сравнительно небольшими остатками. Например, в наборе данных flights можно выделить полные часы и оставшиеся минуты из общей продолжительности полёта, представленной в формате ЧЧММ или ЧММ (dep_time). Тогда вместо хранения и выполнения различных операций над одним большим числом, можно будет хранить и выполнять операции над двумя маленькими:
transmute(flights,
dep_time,
час = dep_time %/% 100,
минута = dep_time %% 100)
Логарифмические функции: log(), log2(), log10(), являются невероятно полезным преобразованием при работе с данными, диапазон которых охватывает несколько порядков наблюдаемой величины. Они также преобразуют мультипликативные операции в аддитивные, к этой особенности вернемся в разделе, посвященном моделированию. При прочих равных условиях, рекомендуется использовать функцию log2() так как её значения легко интерпретировать: разница в 1 на логарифмической линейке соответствует удвоению в исходном масштабе, а разница в -1 соответствует делению пополам.
Смещения: вперёд lead() и назад lag() позволяют просматривать последующие и предыдущие значения списка. Бывают необходимо вычислить приращение аргумента, например, х – lag(x), или проверить неизменность его значений, выражением x != lag(x). Смещения особенно полезны в сочетании с group_by(), но не будем забегать вперёд.
Накопительные и скользящие агрегаторы: R предоставляет функции для вычисления накапливаемой суммы cumsum(), произведения cumprod(), минимума cummin() и максимума cummax() элементов списка; кроме того, dplyr имеет функцию cummean() для вычисления среднего значения. Если нужны скользящие агрегаторы, когда сумма вычисляется по скользящему окну, то обращаются к функционалу пакета RcppRoll.
Логические сравнения: < (меньше), <= (не больше), > (больше), >= (не меньше), != (не равны), и == (равны), о них мы узнали ранее. Напомню лишь, если осуществляется сложная последовательность логических операций, то настоятельно рекомендуется сохранять промежуточные значения в отдельных вспомогательных переменных, чтобы проверить значение выражения на каждом шаге вычислений.
Ранжирование: объединяет в себе целый ряд функций, начиная с min_rank(), которая осуществляет вычисление простого порядкового номера (например, 1-й, 2-й, 3-й, 4-й). По умолчанию присваиваются меньшие номера меньшим значениям, но можно воспользоваться функцией desc() для обращения порядка значений аргумента, чтобы придать наибольшие порядковым номера наименьшим значениям элементов исходного списка. Если min_rank() не делает то, что нужно, загляните в описание функций ранжирования на страницах справки для получения более подробной информации.
Упражнения
1. На переменные, хранящие длительность перелёта, удобно смотреть, но трудно выполнять операции над ними, так как они не совсем порядковые числа, за 159 (которое символизирует 1 час, 59 минут) идет сразу 200 (2 часа ровно). Конвертируйте их в более удобное представление, чтобы хранилось общее количество минут начиная с полуночи.
2. Сравните значения часы_полёта с опоздание_в_каждом_часе. Что надеялись увидеть и что увидели? Что нужно сделать, чтобы исправить ошибку?
3. Найдите 10 самых задерживаемых рейсов, используя функции ранжирования. Как это связано? Внимательно прочитайте текст документация по min_rank().
4. Что возвращает 2:4 – 5:8 и почему?
5. Какие тригонометрические функции определены в R?
Последняя ключевая функция summary(), – она собирает сводную статистику по переменным при помощи вспомогательных функций. Например, среднее значение (mean) переменной dep_delay посчитается в переменную средняя_задержка_рейсов:
summarise(flights, средняя_задержка_рейсов = mean(dep_delay, na.rm = TRUE))
Ниже объясним подробно, что значит последний параметр na.rm = TRUE. Функция summary() не очень полезна, если используется без вспомогательной функции group_by(), которая переключает разбивает анализ всего набора данных на отдельные группы. Когда вызывается функция из пакета dplyr на сгруппированных данных, автоматически подключается group_by() для распараллеливания вычислений в целях повышения производительности и дробления информации. Например, если применить точно такой же вызов как в предыдущем примере, но для сгруппированных по дате записях, то на выходе получится средняя задержка по дням:
сгруппированные_по_дням <���– group_by(flights, year, month, day)
summarise(сгруппированные_по_дням,
средняя_задержка_рейсов_по_датам = mean(dep_delay, na.rm = TRUE))
Вызов функций group_by() совместно с summary() чаще всего используется при работе в пакете dplyr для получения статистических отчетов по группам. Но прежде, чем погрузиться в детали, дополнительно изложим одну техническую идею, касающуюся обработки информации путём её направления по специальным каналам. Представьте, что хотим исследовать закономерность между расстоянием и средней задержкой рейса для каждого пункта назначения. Опираясь на имеющиеся знания о возможностях dplyr, для этого достаточно использовать такой код:
группы_рейсов_по_месту_назначения <���– group_by(flights, dest)
задержки <���– summarise(группы_рейсов_по_месту_назначения,
опозданий = n(), средняя_длина_маршрута = mean(distance, na.rm = TRUE),
средняя_задержка = mean(arr_delay, na.rm = TRUE))
Оставим в выборке рейсы имеющие более сотни регулярных опозданий и, например, не на московских направлениях:
задержки <���– filter(задержки, опозданий > 100, dest != "MSK")
Визуализируем оставшиеся записи:
ggplot(data = задержки, mapping =
aes(x = средняя_длина_маршрута, y = средняя_задержка)) +
geom_point(aes(size = опозданий), alpha = 1/5) +
geom_smooth(se = FALSE)
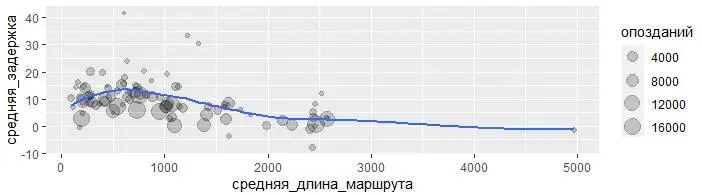
Похоже, что задержки растут с увеличением расстояния до ~750 миль, а затем сокращаются. Неужели, когда рейсы становятся длиннее, появляется возможность компенсировать опоздание находясь в полёте?
Предварительно было пройдено три вспомогательных этапа подготовки данных:
1. Сгруппированы рейсы по направлениям.
2. В каждой из групп усреднены расстояния, длительность задержки и вычислено количество опоздавших рейсов.
3. Отфильтрованы шумы и аэропорт, который не подчиняется законам логики.
Этот код немного перегружен, так как каждому промежуточному блоку данных присвоено имя. Вспомогательные таблицы сохранялись, даже когда их содержимое не востребовано на заключительном этапе, и замедляли анализ. Но есть отличный способ справиться с обозначенной проблемой посредством настройки каналов передачи данных служебным оператором %>%:
задержки <���– flights %>%
group_by(dest) %>%
Читать дальшеИнтервал:
Закладка:









