Е. Миркес - Учебное пособие по курсу «Нейроинформатика»

- Название:Учебное пособие по курсу «Нейроинформатика»
- Автор:
- Жанр:
- Издательство:КРАСНОЯРСКИЙ ГОСУДАРСТВЕННЫЙ ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ
- Год:2002
- Город:Красноярск
- ISBN:нет данных
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Е. Миркес - Учебное пособие по курсу «Нейроинформатика» краткое содержание
Данное учебное пособие подготовлено на основе курса лекций по дисциплине «Нейроинформатика», читавшегося с 1994 года на факультете Информатики и вычислительной техники Красноярского государственного технического университета.
Несколько слов о структуре пособия. Далее во введении приведены учебный план по данному курсу, задания на лабораторные работы. Следующие главы содержат одну или несколько лекций. Материал, приведенный в главах, несколько шире того, что обычно дается на лекциях. В приложения вынесены описания программ, используемых в данном курсе (Clab и Нейроучебник), и проект стандарта нейрокомпьютера, включающий в себя два уровня — уровень запросов компонентов универсального нейрокомпьютера и уровень языков описания отдельных компонентов нейрокомпьютера.
Данное пособие является электронным и включает в себя программы, необходимые для выполнения лабораторных работ.
Учебное пособие по курсу «Нейроинформатика» - читать онлайн бесплатно полную версию (весь текст целиком)
Интервал:
Закладка:
5. Записать G m+1 -1.
Таким образом эта процедура требует m + n + mn +3 m ² операций. Тогда как стандартная схема полного пересчета потребует:
1. Вычислить всю матрицу Грама ( nm ( m +1)/2 операций).
2. Методом Гаусса привести левую квадратную матрицу к единичному виду (2 m ³+ m ²- m операций).
3. Записать G m+1 -1.
Всего 2 m ³+ m ²– m + nm ( m +1)/2 операций, что в m раз больше.
Используя ортогональную сеть (6), удалось добиться независимости способности сети к запоминанию и точному воспроизведению эталонов от степени коррелированности эталонов. Так, например, ортогональная сеть смогла правильно воспроизвести все буквы латинского алфавита в написании, приведенном на рис. 1.
Основным ограничением сети (6) является малое число эталонов — число линейно независимых эталонов должно быть меньше размерности системы n .
Тензорные сети
Для увеличения числа линейно независимых эталонов, не приводящих к прозрачности сети, используется прием перехода к тензорным или многочастичным сетям [75, 86, 93, 293].
В тензорных сетях используются тензорные степени векторов. k- ой тензорной степенью вектора x будем называть тензор x ⊗k, полученный как тензорное произведение k векторов x.
Поскольку в данной работе тензоры используются только как элементы векторного пространства, далее будем использовать термин вектор вместо тензор. Вектор x ⊗kявляется n k -мерным вектором. Однако пространство L ({x ⊗k}) имеет размерность, не превышающую величину , где — число сочетаний из p по q . Обозначим через {x ⊗k} множество k- х тензорных степеней всех возможных образов.
Теорема. При k в множестве {x ⊗k} линейно независимыми являются векторов. Доказательство теоремы приведено в последнем разделеданной главы.
Небольшая модернизация треугольника Паскаля, позволяет легко вычислять эту величину. На рис. 2 приведен «тензорный» треугольник Паскаля. При его построении использованы следующие правила:
1. Первая строка содержит двойку, поскольку при n= 2 в множестве X всего два неколлинеарных вектора.
2. При переходе к новой строке, первый элемент получается добавлением единицы к первому элементу предыдущей строки, второй — как сумма первого и второго элементов предыдущей строки, третий — как сумма второго и третьего элементов и т. д. Последний элемент получается удвоением последнего элемента предыдущей строки.

Рис. 2. “Тензорный” треугольник Паскаля
В табл. 1 приведено сравнение трех оценок информационной емкости тензорных сетей для некоторых значений n и k. Первая оценка — n k — заведомо завышена, вторая — — дается формулой Эйлера для размерности пространства симметричных тензоров и третья — точное значение.
Таблица 1.
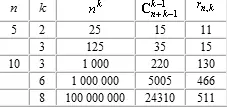
Как легко видеть из таблицы, уточнение при переходе к оценке r n,k является весьма существенным. С другой стороны, предельная информационная емкость тензорной сети (число правильно воспроизводимых образов) может существенно превышать число нейронов, например, для 10 нейронов тензорная сеть валентности 8 имеет предельную информационную емкость 511.
Легко показать, что если множество векторов { x i } не содержит противоположно направленных, то размерность пространства L ({x ⊗k}) равна числу векторов в множестве { x i }.
Сеть (2) для случая тензорных сетей имеет вид
(9)
а ортогональная тензорная сеть
(10)
где r ij -1— элемент матрицы Γ -1({x ⊗k}).
Рассмотрим, как изменяется степень коррелированности эталонов при переходе к тензорным сетям (9)
Таким образом, при использовании сетей (9) сильно снижается ограничение на степень коррелированности эталонов. Для эталонов, приведенных на рис. 1, данные о степени коррелированности эталонов для нескольких тензорных степеней приведены в табл. 2.
Таблица 2. Степени коррелированности эталонов, приведенных на рис. 1, для различных тензорных степеней.
| Тензорная степень | Степень коррелированности | Условия | ||||
|---|---|---|---|---|---|---|
| C AB | C AC | C BC | C AB+C AC | C AB+C BC | C AC+C BC | |
| 1 | 0.74 | 0.72 | 0.86 | 1.46 | 1.60 | 1.58 |
| 2 | 0.55 | 0.52 | 0.74 | 1.07 | 1.29 | 1.26 |
| 3 | 0.41 | 0.37 | 0.64 | 0.78 | 1.05 | 1.01 |
| 4 | 0.30 | 0.26 | 0.55 | 0.56 | 0.85 | 0.81 |
| 5 | 0.22 | 0.19 | 0.47 | 0.41 | 0.69 | 0.66 |
| 6 | 0.16 | 0.14 | 0.40 | 0.30 | 0.56 | 0.54 |
| 7 | 0.12 | 0.10 | 0.35 | 0.22 | 0.47 | 0.45 |
| 8 | 0.09 | 0.07 | 0.30 | 0.16 | 0.39 | 0.37 |
Анализ данных, приведенных в табл. 2, показывает, что при тензорных степенях 1, 2 и 3 степень коррелированности эталонов не удовлетворяет первому из достаточных условий ( ), а при степенях меньше 8 — второму ( ).
Таким образом, чем выше тензорная степень сети (9), тем слабее становится ограничение на степень коррелированности эталонов. Сеть (10) не чувствительна к степени коррелированности эталонов.
Сети для инвариантной обработки изображений
Для того, чтобы при обработке переводить визуальные образов, отличающиеся только положением в рамке изображения, в один эталон, применяется следующий прием [91]. Преобразуем исходное изображение в некоторый вектор величин, не изменяющихся при сдвиге (вектор инвариантов). Простейший набор инвариантов дают автокорреляторы — скалярные произведения образа на сдвинутый образ, рассматриваемые как функции вектора сдвига.
В качестве примера рассмотрим вычисление сдвигового автокоррелятора для черно-белых изображений. Пусть дан двумерный образ S размером p×q=n. Обозначим точки образа как s ij . Элементами автокоррелятора Ac ( S ) будут величины , где s ij =0 при выполнении любого из неравенств i < 1, i > p , j < 1, j > q . Легко проверить, что автокорреляторы любых двух образов, отличающихся только расположением в рамке, совпадают. Отметим, что a ij=a -i,-j при всех i,j , и a ij =0 при выполнении любого из неравенств i < 1- p , i > p -1, j < 1- q , j > q -1. Таким образом, можно считать, что размер автокоррелятора равен p ×(2 q +1).
Автокорреляторная сеть имеет вид
(11)
Сеть (11) позволяет обрабатывать различные визуальные образы, отличающиеся только положением в рамке, как один образ.
Конструирование сетей под задачу
Интервал:
Закладка: