Анатолий Фоменко - Числа против лжи.

- Название:Числа против лжи.
- Автор:
- Жанр:
- Издательство:Астрель, АСТ
- Год:2011
- Город:Москва
- ISBN:978-5-17-075911-8
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Анатолий Фоменко - Числа против лжи. краткое содержание
Начиная с 1973 года, исследованием проблемы занялся А.Т. Фоменко, а через некоторое время — под его руководством — группа математиков Московского государственного университета им. М.В. Ломоносова. А.Т. Фоменко и его коллегами были созданы новые математико-статистические методы обнаружения дубликатов (повторов), содержащихся в летописях.
Разработаны новые методы датирования событий. Вскрыты ошибки в принятой сегодня хронологии. Излагается «история истории»: кем, когда и как была создана принятая сегодня версия «древности». Как математика помогает вычислять даты древних событий? Почему картина звездного неба, записанная в известном библейском Апокалипсисе, указывает на конец XV века? Приводится один из главных результатов Новой Хронологии, а именно, «глобальная хронологическая карта», позволившая обнаружить поразительные сдвиги в хронологии, с помощью которых средневековая история X–XVII веков была искусственно «удлинена» хронологами XVII–XVIII веков.
Книга является уникальным событием в международной научной жизни, она не оставит равнодушным ни одного читателя. От читателя не требуется никаких специальных знаний. Нужен лишь интерес к всеобщей и русской истории и желание разобраться в ее многочисленных загадках. Книга предназначена для самых широких кругов читателей, интересующихся применением естественно-научных методов в истории.
Числа против лжи. - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
8) После применения к списку D летописных династий возмущений типов (1) и (2), см. выше, оказалось, что получается примерно 15×10 11 виртуальных династий. То есть, в множестве vir(D) оказывается примерно 15×10 11точек.
2.4. Результат эксперимента: коэффициент c(а, b) хорошо различает зависимые и независимые династии царей
Вычислительный эксперимент, проведенный в 1977–1979 годах мною совместно с М. Замалетдиновым и П. Пучковым, подтвердил принцип малых искажений. А именно, оказалось, что для заведомо зависимых летописных династий а и b число ВССД = с(а, b) всегда не превышает 10 8и обычно колеблется от 10 12до 10 10. При вероятностной интерпретации это означает, что если рассматривать наблюдаемую близость двух зависимых летописных династий как случайное событие, то его вероятность мала, событие исключительно редкое, поскольку реализуется единственный из ста миллиардов шансов.
Выяснилось далее, что если две летописные династии а и b изображают две заведомо разные реальные династии, то коэффициент ВССД = с(а, b) «существенно больше». А именно, он всегда не меньше чем 10 3, то есть «велик». Как и в случае с коэффициентом p(X, Y) здесь важны, конечно, не абсолютные значения ВССД = с(а, b), а разница в несколько порядков между «зависимой зоной» и «независимой зоной», см. рис. 5.23.
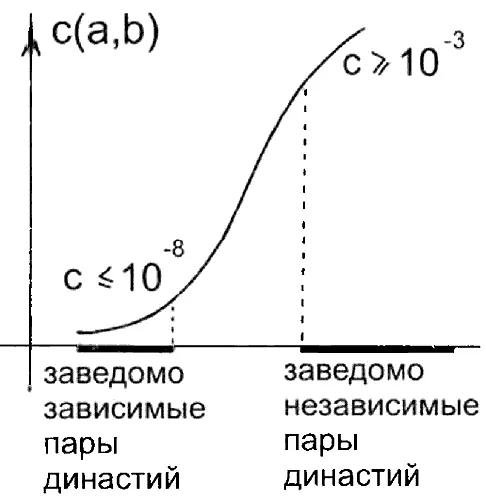
Рис. 5.23. Коэффициент с(а, b) позволяет различать зависимые и независимые пары династий.
Итак, при помощи коэффициента ВССД удалось обнаружить существенное различие между заведомо зависимыми и заведомо независимыми летописными династиями.
2.5. Метод датирования царских династий и метод обнаружения фантомных династических дубликатов
Итак, при помощи коэффициента с(а, b) можно достаточно уверенно различать зависимые и независимые пары летописных династий. Важный экспериментальный факт состоит в том, что летописцы ошибаются «не слишком сильно». Во всяком случае, их ошибки существенно меньше величины, различающей независимые династии.
Это позволяет, в рамках проведенного эксперимента, предложить новый метод распознавания зависимых летописных династий и методику датировки неизвестных династий. Поступая по аналогии с предыдущим пунктом, вычисляем для неизвестной династии d коэффициент с(a, d), где а — известные, уже датированные летописные династии. Допустим, что мы обнаружили династию а, для которой коэффициент с(a, d) мал, то есть не превышает 10 8. Это дает нам основание утверждать, что династии a и d зависимы с вероятностью 1 - с(а, d). То есть, летописные династии a и d, по-видимому, соответствуют одной реальной династии M, датировка которой нам уже известна. Тем самым, мы датируем летописную династию d.
Эта методика проверена на средневековых династиях с заранее известной датировкой. Эффективность методики полностью подтвердилась [904], [908].
Этот же метод позволяет обнаруживать в «скалигеровском учебнике по истории» фантомные дубликаты. А именно, если мы найдем две летописные династии а и b, для которых коэффициент с(а, b) не превышает 10 8, это дает основания предполагать, что перед нами — просто два экземпляра, две версии описания какой-то одной и той же реальной династии М. Которая размножилась на страницах разных летописей, помещенных затем в разные места «скалигеровского учебника».
Повторим еще раз, что любые выводы или гипотезы, апеллирующие к «похожести» или, напротив, «непохожести» династий, могут считаться осмысленными только в том случае, когда они опираются на обширные численные эксперименты, подобные проведенным нами. В противном случае на первое место выступают туманные субъективные соображения, обсуждать которые вряд ли стоит.
3. Принцип затухания частот
Метод упорядочивания исторических текстов во времени
Принцип затухания частот и основанный на нем метод предложен и разработан мною в [884], [886], [888], [1129], [891], [895], [898], [901], [1130].
Настоящий метод позволяет находить хронологически правильный порядок отдельных фрагментов текста, обнаруживать в нем дубликаты на основе анализа, например, совокупности собственных имен, упомянутых в тексте. Как и в предыдущих методиках, мы стремимся к созданию метода датировки, основанного на численных, количественных характеристиках текстов и не обязательно требующего анализа смыслового содержания текстов, которое может быть весьма многозначно и расплывчато.
Если в документе упомянуты какие-либо «знаменитые», ранее известные нам персонажи, описанные в других, уже датированных хрониках, то это позволяет датировать описанные в тексте события. Однако если такое отождествление сразу не удается и если, кроме того, описаны события нескольких поколений с большим количеством ранее неизвестных действующих лиц, то задача установления тождества персонажей с ранее известными усложняется. Для краткости назовем фрагмент текста, описывающий события одного поколения, «главой-поколением».
Будем считать, что средняя длительность одного «поколения» — это средняя длительность правления реальных царей, зафиксированных в дошедших до нас летописях. Эта средняя длительность правления царей вычислена автором настоящей книги при обработке хронологических таблиц Блера [76]. Она оказалась равной 17,1 года [884].
При работе с реальными историческими текстами выделение в них «глав-поколений» иногда наталкивается на трудности. В таких случаях мы ограничивались лишь приблизительным разбиением текста на последовательные фрагменты. Пусть летопись X описывает события на достаточно большом интервале времени (А, В), на протяжении которого сменилось, по крайней мере, несколько поколений персонажей. Пусть летопись X разбита на «главы-поколения» X(T), где T — порядковый номер поколения, описанного во фрагменте X(T) в той нумерации «глав», которая фиксирована в тексте.
Возникает вопрос: правильно ли занумерованы, упорядочены эти «главы-поколения» в летописи? Или же, если эта нумерация утрачена или сомнительна, то как ее восстановить? Другими словами, как правильно расположить во времени «главы» друг относительно друга? Оказывается, для реальных исторических текстов в подавляющем большинстве случаев выполняется следующая «формула»-правило: полное имя = персонаж. Это означает следующее.
Пусть интервал времени, описываемый летописцем, достаточно велик, например, составляет несколько десятков или сотен лет. Тогда, — как было проверено нами в результате анализа большого набора исторических документов, — в подавляющем большинстве случаев РАЗНЫЕ ПЕРСОНАЖИ имеют в одном и том же тексте РАЗНЫЕ ПОЛНЫЕ ИМЕНА. Полное имя может состоять из нескольких слов, например, Карл Плешивый. Другими слова ми, ЧИСЛО РАЗНЫХ ЛИЦ С ОДИНАКОВЫМИ ПОЛНЫМИ ИМЕНАМИ НИЧТОЖНО МАЛÓ ПО СРАВНЕНИЮ С КОЛИЧЕСТВОМ ВСЕХ ПЕРСОНАЖЕЙ. Это верно для всех нескольких сотен исследованных нами исторических текстов, описывающих Рим, Грецию, Германию, Италию, Россию, Англию и т. д. Ничего удивительного в этом нет. В самом деле, летописец заинтересован в различении разных персонажей, чтобы избежать путаницы. Простейший способ добиться этого — присвоить разным лицам разные полные имена. Это простое психологическое обстоятельство и подтверждается подсчетами.
Читать дальшеИнтервал:
Закладка:








