Дэвид Шпигельхалтер - Искусство статистики. Как находить ответы в данных

- Название:Искусство статистики. Как находить ответы в данных
- Автор:
- Жанр:
- Издательство:Манн, Иванов и Фербер
- Год:2021
- Город:Москва
- ISBN:9785001692508
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Дэвид Шпигельхалтер - Искусство статистики. Как находить ответы в данных краткое содержание
Эта книга предназначена как для студентов, которые хотят ознакомиться со статистикой, не углубляясь в технические детали, так и для широкого круга читателей, интересующихся статистикой, с которой они сталкиваются на работе и в повседневной жизни. Но даже опытные аналитики найдут в книге интересные примеры и новые знания для своей практики. На русском языке публикуется впервые.
Искусство статистики. Как находить ответы в данных - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Осознавать неопределенность крайне важно. Сделать какую-нибудь оценку способен кто угодно, но умение реалистично определить ее возможную погрешность – важнейший компонент статистики. Даже притом, что это затрагивает некоторые сложные понятия.
Предположим, мы собрали какие-то точные данные, возможно, с помощью хорошо спланированного опроса, и хотим обобщить результаты на изучаемую совокупность. Если мы проявляли осторожность и избегали внутренних смещений (скажем, обеспечив случайную выборку), то можем ожидать, что характеристики выборки будут близки к соответствующим характеристикам изучаемой совокупности.
Этот важный момент стоит уточнить. В хорошем исследовании мы ожидаем, что выборочное среднее будет близко к среднему всей совокупности, интерквартильный размах в выборке будет близок к интерквартильному размаху всей совокупности и так далее. В главе 3мы рассматривали идею характеристик всей совокупности на примере данных о весе новорожденных, где назвали выборочное среднее статистикой , а среднее всей совокупности – параметром . В более строгих статистических текстах эти две величины обычно обозначают римскими и греческими буквами соответственно – скорее всего, в обреченной (вероятно) попытке избежать путаницы. Например, латинской буквой m часто обозначают выборочное среднее, а греческой буквой μ (мю) – среднее всей совокупности, буквой s – выборочное среднеквадратичное отклонение, а буквой σ (сигма) – среднеквадратичное отклонение всей совокупности.
Часто сообщают только итоговую статистику, и во многих случаях этого может быть достаточно. Например, мы видели, что большинство людей не знают, что показатели безработицы в США и Соединенном Королевстве основаны не на полном подсчете всех официально зарегистрированных безработных, а на масштабных опросах. Если такой опрос установил, что 7 % людей в выборке безработные, то национальные агентства и СМИ обычно преподносят это как факт, что 7 % всего населения страны безработные, вместо того чтобы признать, что 7 % – это всего лишь оценка. Выражаясь научно более точно, они просто путают выборочное среднее и среднее во всей совокупности.
Это может оказаться неважным при намерении просто представить широкую картину происходящего в стране, когда опрос масштабен и надежен. Но давайте возьмем такой пример: вы услышали, что опрошены только 100 человек, из которых семь сказали, что не имеют работы. Оценка составляет 7 %, но, вероятно, вряд ли вы сочли бы ее надежной и были бы счастливы, если бы она описывала всю совокупность. А если бы в опросе участвовала 1000 человек? А 100 тысяч? При достаточном масштабе опроса вы, возможно, увереннее согласитесь с тем, что выборочная оценка – достаточно хорошая характеристика всей совокупности. Размер выборки должен влиять на вашу уверенность в оценке, а чтобы делать статистические выводы, необходимо знать, насколько выборочная характеристика может отличаться от настоящей.
Давайте вернемся к опросу Natsal, описанному в главе 2, в котором участников спрашивали, сколько сексуальных партнеров у них было в течение жизни. В качестве респондентов было привлечено 1125 женщин и 806 мужчин в возрасте 35–44 лет, так что это был солидный опрос. В табл. 2.2представлены вычисленные выборочные характеристики, например медиана – 8 для мужчин и 5 для женщин. Поскольку мы знаем, что этот опрос базировался на правильной случайной выборке, вполне разумно предположить, что изучаемая совокупность соответствует целевой совокупности, то есть взрослому населению Великобритании. Главный вопрос здесь таков: насколько близки найденные статистики к тому, что мы обнаружили бы, опросив всех жителей страны?
В качестве иллюстрации того, как точность статистики зависит от размера выборки, представим, что мужчины в нашем опросе фактически представляют собой всю генеральную совокупность, которая нас интересует. Их ответы приведены на нижней диаграмме рис. 7.1. Для иллюстрации извлечем последовательные случайные выборки из общей совокупности из 760 участников: сначала 10, затем 50, а потом 200 человек. Распределение данных для трех выборок показано на рис. 7.1. Ясно видно, что маленькие выборки «ухабистее», поскольку они чувствительны к отдельным точкам. Сводные характеристики этих постепенно увеличивающихся выборок представлены в табл. 7.1. В первой выборке из 10 человек наблюдается большое количество партнеров (среднее 8,4), но по мере роста выборки эта величина постепенно уменьшается, приближаясь к характеристике всей группы из 760 человек.
Рис. 7.1
Нижняя диаграмма отображает распределение ответов для всех 760 мужчин в опросе. Из этой группы случайным образом последовательно выбираются 10, 50 и 200 человек. Соответствующие распределения построены на первых трех диаграммах. У меньших выборок видны значительные разбросы, но постепенно форма распределения приближается к распределению всей группы из 760 мужчин. Не показаны значения свыше 50 партнеров
Таблица 7.1
Сводные статистические данные о количестве сексуальных партнеров за всю жизнь у мужчин в возрасте 35–44 лет, которое они указывали в исследовании Natsal 3 (случайные выборки и характеристики всей группы из 760 мужчин)
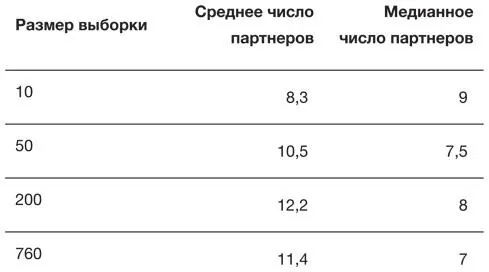
А теперь вернемся к фактической задаче: что мы можем сказать о среднем и медианном числе партнеров во всей изучаемой совокупности мужчин в возрасте 35–44 лет, основываясь на реальных выборках мужчин, показанных на рис. 7.1? Мы могли бы оценить эти параметры всей популяции по выборочной статистике каждой группы, представленной в табл. 7.1, предполагая, что статистики на основе б о льших выборок в каком-то смысле «лучше»: например, оценки среднего количества партнеров сходятся к 11,4, и при достаточно большой выборке мы, скорее всего, приблизились бы к истинному ответу с желаемой точностью.
Вот здесь мы подошли к критическому шагу. Чтобы понять, насколько точными могут быть такие характеристики, нам нужно подумать, как эти статистики могут измениться, если мы (в воображении) неоднократно повторим процесс составления выборки. Иначе говоря, если бы мы раз за разом формировали выборки из 760 британцев, насколько сильно менялись бы их статистики?
Если бы мы знали, как сильно они будут варьироваться, это помогло бы нам понять, насколько точна наша фактическая оценка. К сожалению, определить точный разброс оценок мы могли бы только в случае, если бы точно знали информацию о всей генеральной совокупности. Но как раз этого мы и не знаем.
Читать дальшеИнтервал:
Закладка:







