Алексей Благирев - Big data простым языком [litres]
![Алексей Благирев - Big data простым языком [litres]](/books/1084716/aleksej-blagirev-big-data-prostym-yazykom-litres.webp "Обложка книги")
- Название:Big data простым языком [litres]
- Автор:
- Жанр:
- Издательство:Литагент АСТ
- Год:2019
- Город:Москва
- ISBN:978-5-17-111829-7
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Алексей Благирев - Big data простым языком [litres] краткое содержание
Но насколько глубока кроличья нора? Каждому предстоит разобраться в этом самому. Эта книга поможет донести основные принципы проектирования и создания таких интерфейсов управления бизнесом, обществом и окружающим нас миром посредством Больших данных. Читайте, наслаждайтесь и помните: сожжение книг противозаконно.
Big data простым языком [litres] - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Они используют опросы, изучают логи [133] Файлы, в которые записываются все события, происходящие в каждой системе.
подключений к системам и на выходе, по результатам своей работы, они могут сказать, в каких из измерений, скорее всего, будет проблема.
Эти самые «assertions» можно смело назвать «измерениями», то есть некоторым разделением того, как я воспринимаю объект в реальном мире.
Главное, что они должны говорить пользователю – любое число или любые данные – само по себе объект многомерный.
Вот я держу книгу. В стандартной проекции у нее три оси – ширина от края разворота до середины, длина от одного края страницы до другого края страницы и толщина, то есть количество страниц. Книгу мы воспринимаем как физический объект в трех измерениях.
Так вот, информация сама по себе имеет много измерений, больше трех. И не факт, что их именно тринадцать. Чтобы управлять качеством этой информации, нужно управлять представлением этой информации в этих измерениях. Это сложный контекст, отчасти поэтому в качество данных мало инвестируют и мало этим занимаются, хотя, на мой персональный взгляд, ценность этого очевидна.
Чтобы стало проще, можно упростить количество тех самых измерений, в которых мы управляем качеством данных. Для простоты оставим только «полноту» и «точность» – то есть все, что произошло вокруг, отражено в информации и отражено корректно. Только два измерения.
Теперь вернемся к пресловутому и коварному отчету «аппетит к риску» – здесь мы должны посчитать размер потенциального искажения для двух измерений.
Как пострадает организация, если поймет, что не отражены только 95 % тех событий, которые произошли, или что сами 15 % событий отражены неточно? Возьмем то же поле «ИНН». Допустим, что поле заполнено только в 95 % случаев, а в заполненных оно некорректно в 15 % случаев. Пусть мы говорим о количестве записей 10 тысяч единиц известных нам, тогда потенциальный размер штрафа будет равен:
15 %*95 %*10 000 + (10000/95 % – 10000) = 1425 + 526 = 1951 записи могут быть некорректны.
Опустим как получили оценку 95 % или 15 %, для простоты считаем это экспертной позицией участников процесса работы с данными.
1951 умножаем на размер штрафа в пятьсот рублей, получаем 975 500 рублей – это потенциальный убыток от проблем с качеством данных одного поля «ИНН» для организации.
Как понять, какие измерения качества выбрать?
Мне нравится одно очень интересно исследование, которое провели исследователи из MIT. Оно называется « Beyond Accuracy» [134] http://mitiq.mit.edu/Documents/Publications/TDQMpub/14_Beyond_Accuracy.pdf
[135] .
. Для него исследователи выделили несколько групп пользователей.
В первой группе пользователей, которых они опросили, были студенты MBA.
Во второй группе пользователей, среди которых был опрос, находились уже выпускники MBA, которые проработали в компаниях достаточное количество лет.
Опросы так же отличались друг от друга. Опрос для первой группы включал в себя список возможных измерений контроля качества данных, из которого студенты должны были выбрать предпочтительный.
Напомню, что в исследованиях всегда используют один из трех различных подходов получения научного познания:
• Эмпирический – познание получаем через ощущения.
• Теоретический – осмысление опыта с точки зрения логики.
• Интуитивный – когда мы полагаемся на свой «внутренний» голос при исследовании того или иного события.
В первой группе исследователи применили теоретический подход получения нового знания – а именно списка параметров, «измерений», по которым можно контролировать качество данных.
Во второй группе исследователи применили уже интуитивный подход, чтобы понять, какие из этих параметров на самом деле наиболее важны в принятии решений и их влиянии на бизнес. В этом случае продолжительный опыт бывших выпускников MBA в компаниях являлся тем самым «внутренним фильтром», который помог определить наиболее ценные измерения из большого списка.
Исследователи сформировали список из 32 параметров контроля качества данных (32 параметра – это достаточно внушительно), и попросили сформулировать, как бы выпускники контролировали качество данных.
По итогам опроса получилось 179 уникальных параметров, которые сформулировали участники процесса, то есть в пять с половиной раз больше, чем исследователи изначально заложили в свою модель.
Модель исследователей строилась на четырех основных группах, которые объединяли эти самые параметры:
• Доступность – данные должны быть доступныдля пользователя.
• Интерпретируемость – данные должны быть способны к интерпретации. К слову, не пытайтесь использовать мандаринский диалект, если вдруг пишите комментарии в проводках и так далее.
• Релевантность – данные должны быть релевантныдля конечного пользователя, если они участвуют в процессе принятия решения.
• Точность – данные должны быть точныдля пользователя, то есть быть точными и из достоверных источников.
Во второй группе исследователи отбросили часть новых параметров и показали только 118 параметров контролирования качества данных. Опрос строился на ответах 1500 выпускников MBA, которые уже имели внушительный опыт работы.
Опустим тот факт, что опрос строился через почту, и тогда не было еще нормального работающего Интернета, обратимся лучше к его результатам.
99 из указанных параметров из основного списка оказались абсолютно не важны, когда люди с большим опытом и багажом знаний попытались интуитивно ответить на тот же самый вопрос о том, как контролировать качество данных.
Два параметра пользователи выделили как самые важные – «точность» (accuracy) и «правильность» (correct). Все самые важные параметры исследователи сгруппировали вместе в кластеры, которых получилось ровно четыре.
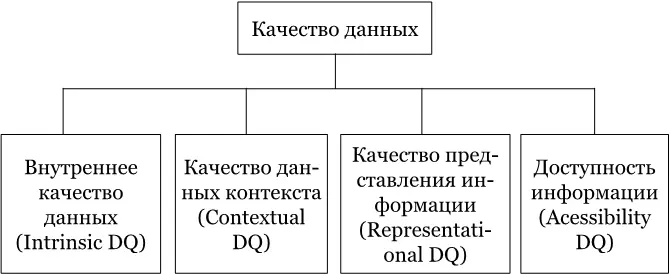
Рисунок SEQ Рисунок \* ARABIC 1 Структура концептуального фреймворка DQ, на основании исследования MIT Beyond Accuracy. 1993
Внутреннее качество данных– включает не только точность, но и два новых измерения – репутацию и правдоподобие. Одна лишь «точность», как оказалось, не дает пользователям уверенности в корректности данных. Им нужно доверять источникам данных.
Качество данных контекста– как оказалось, качество данных по контексту профессиональная литература по работе с данными не распознает, то есть, таких знаний просто не было. Люди не имели представления, как управлять качеством того контекста, который они получают. Единственные доступные материалы были о качестве визуального контекста – графике. Мы это подробно разобрали в главе про «Data Storytelling». Пример реализации контекстных проверок был, как ни странно, в армии Соединенных Штатов Америки во время операции « Буря в Пустыне» [136] .
, где такие проверки были установлены на воздушных судах. Они анализировали для каждой задачи, выполняемой воздушным судном, широкий список параметров, используемый в планировании авиаударов.
Интервал:
Закладка: