Алексей Благирев - Big data простым языком [litres]
![Алексей Благирев - Big data простым языком [litres]](/books/1084716/aleksej-blagirev-big-data-prostym-yazykom-litres.webp "Обложка книги")
- Название:Big data простым языком [litres]
- Автор:
- Жанр:
- Издательство:Литагент АСТ
- Год:2019
- Город:Москва
- ISBN:978-5-17-111829-7
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Алексей Благирев - Big data простым языком [litres] краткое содержание
Но насколько глубока кроличья нора? Каждому предстоит разобраться в этом самому. Эта книга поможет донести основные принципы проектирования и создания таких интерфейсов управления бизнесом, обществом и окружающим нас миром посредством Больших данных. Читайте, наслаждайтесь и помните: сожжение книг противозаконно.
Big data простым языком [litres] - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Представление качества данных– в первую очередь эта группа касается проблем с форматом данных и с тем, чтобы данные можно было понять и интерпретировать. К примеру, данные по отчетности ВТБ отражаются в российских рублях, в свою очередь, в данных группы Альфа-Банка в публикуемой отчетности вместо рублей уже используются доллары как основная валюта.
Доступность данных– один из самых неоднозначных параметров, потому что управление информационной безопасностью в большинстве проектов и организацией, в которых мне довелось побыть, выведено за периметр как IT-департамента, так и Финансового департамента. Управление информационной безопасностью – это отдельно выделенный лидер внутри организации, поэтому решения в области ИБ в большинстве случаев не участвуют в управлении качества данных.
В итоге, исследователи MIT вывели 15 ключевых измерений того, как можно управлять качеством данных, и сформировали из них следующий фреймворк.
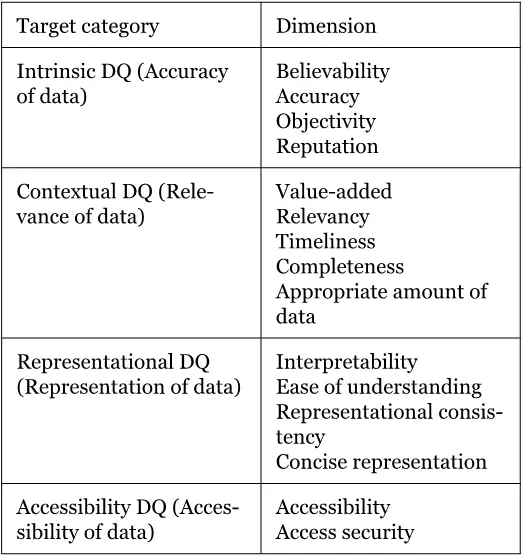
Это было более двадцати лет назад, но на мой скромный экспертный взгляд такой подход по-прежнему актуален, хотя мало где еще используется. Его мы можем смело использовать при подготовке отчета «аппетит к риску», чтобы выбить из менеджмента ресурсы на все свои «хотелки» в области данных.
Инструменты управления качеством данных
Вот представим, что вам дали задачу наладить контроль качества данных в организации. Ваши действия? Кроме того, что выпить валерьянки – это и так понятно.
Я бы постарался разделить весь этот необъятный пирог из данных внутри организации на какие-то разумные блоки или куски.
Интуитивно понятным мне видится выделить хотя бы три блока информации, которыми можно попробовать управлять каждым по-своему. Ими будут – клиенты, справочники и продукты.
Такие блоки для простоты предлагаю называть «доменами», только не будем путать их с теми доменами, которые есть в Интернете. В текущем контексте «домен» – это группа однородной информации, которой нужно управлять. Большую часть информационного пирога можно разделить на три крупных блока, чтобы с этим начать работать по закону Парето [137] 20 % усилий дают 80 % результата.
.
Почему так?
На моей практике оказалось, что решения или инструменты (программные средства), которые обещают стать универсальным средством, по факту проигрывают в этом соревновании. Либо они становятся малоэффективными, то есть не позволяют выявить проблемы в данных, либо они становятся неимоверно дорогими, до такой степени, что стоимость их использования совершенно не сопоставима с получаемой ценностью.
Поэтому я для себя решил, что одного универсального средства ото всех бед не существует. Кстати, такие универсальные инструменты называются MDM-платформами [138] Master Data Management – платформа управления мастер-данными.
. Какое-то время они считались единственным средством против всех болезней и рекомендовались к внедрению в любой организации для любой проблемы. В реальности каждое такое внедрение превращалось в некий эпик фейл, то есть в мероприятие, обреченное на провал. Поиск Святого Грааля в решениях с данными натолкнул на мысль о «вырожденности» решений, которые могут управлять различными доменами. «Вырожденность» подразумевает, что свойства и функции каждого из инструментов для различных доменов сильно отличаются друг от друга. Инструмент по управлению качеством данных для домена «Клиенты» не подходит для управления качеством в домене «Справочники» – и наоборот.
Теперь шаг в сторону и маленький ликбез по тому, как можно управлять качеством данных этого большого информационного пирога.
С одной стороны, можно не трогать источники данных и работать с конечным информационным продуктом, что обычно получается на выходе. К примеру, как это делают аудиторы, когда работают и проверяют финансовую отчетность и данные, на основании которых она строится.
С другой стороны, можно исправлять данные там, где они появляются, то есть, в самих системах. Или исправлять до того момента, пока они не появятся. Например, ограничить ввод данных и задать определенные рамки для информации [139] Например, выпадающие списки, где можно выбрать значение только из списка.
.
Разница между этими принципиальными подходами заключается только в стоимости усилий. Оказалось, что стоимость усилий контроля в конце цикла какого-то длинного процесса кратновыше, чем стоимость контроля на начальных этапах. Происходит это из-за того, что анализ проблем осуществляется в конце, и требуется много дополнительного времени для раскопок причин, которые обычно могут рассказать, что пошло не так.
Если, скажем, стоимость проверки в конце при формировании финансовой отчетности стоит тысячу рублей, то стоимость контроля на первых этапах будет стоить не больше десяти рублей. Поэтому при плохой работе внутренних контролей внешний аудит обычно стоит много денег, потому что аудиторам приходится раскапывать много информации, – почему все плохо в цифрах.
Работать с качеством данных и контролировать их на первых этапах можно несколькими путями. Можно задать тот самый коридор допустимых значений, которые, к примеру, не позволяют ввести несуществующий адрес.
Во втором случае все работает наоборот. Решения допускают ввод любого значения, чтобы потом некоторое внутреннее решение по тому или иному домену само разобрало данные с использованием различной сложной логики и предложило правильный вариант. Если я ввел несуществующий адрес, система сможет найти самый ближайший аналог или экземпляр похожего адреса, который существует в реальности, а дата-стюард уже согласует финальное значение.
Да, именно так, решения сами по себе без дата-стюардов не работают, то есть нельзя автоматизировать всеми возможными средствами вокруг все возможные ошибки.
Самыми эффективными считаются гибридные подходы. Они объединяют первые подходы с заранее невозможным вводом несуществующих и невозможных данных и с определенным допущением свободны со стороны пользователя ввести все, что он считает правильным. Пример с почтовыми индексами это наглядно отражает. В базах данных они по-прежнему некорректные, поэтому пользователя просят дополнительно в свободной форме ввести его.
Первый подход называется «децентрализованным» контролем качества данных [140] Так как источников ввода может быть много, то допускается, что они сгружают из систем в решение по тому или иному домену по обработке данных.
, а второй, когда задаются значения, называется «централизованным» [141] Централизованным он называется потому, что инструмент становится мастер источником для всех остальных систем и распространяет заведомо качественный и согласованный контент, который в нем появляется.
.
Интервал:
Закладка: