Чарльз Уилан - Голая статистика

- Название:Голая статистика
- Автор:
- Жанр:
- Издательство:Array Литагент «МИФ без БК»
- Год:2016
- Город:Москва
- ISBN:978-5-00057-953-4
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Чарльз Уилан - Голая статистика краткое содержание
Эта книга будет полезной для студентов, которые не любят и не понимают статистику, но хотят в ней разобраться; маркетологов, менеджеров и аналитиков, которые хотят понимать статистические показатели и анализировать данные; а также для всех, кому интересно, как устроена статистика.
Голая статистика - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Это, так сказать, «картина в целом». Фактическая методология гораздо сложнее. Вообще говоря, в 2006 году Netflix инициировала конкурс, в рамках которого обычным гражданам было предложено разработать механизм, который бы повысил эффективность уже существующих рекомендаций Netflix по меньшей мере на 10 % (это означает, что данная система стала бы на 10 % точнее при прогнозировании того, как бы кинозритель оценил тот или иной фильм после просмотра). Победителю был обещан 1 миллион долларов.
Каждый человек или группа людей, зарегистрировавшихся для участия в конкурсе, получал «обучающие данные», состоящие из более чем 100 миллионов рейтингов, выставленных 18 000 фильмам клиентами Netflix (их общее количество составляло 480 000 человек). Отдельная совокупность из 2,8 миллиона рейтингов не разглашалась (то есть Netflix знала, как кинозрители оценили эти фильмы, но участникам конкурса такая информация не предоставлялась). Конкурсантов оценивали по тому, насколько успешно предложенные ими алгоритмы прогнозировали фактические оценки, выставленные зрителями этих «неразглашенных» фильмов. Спустя три года тысячи команд из более чем 180 стран представили на суд жюри свои предложения. К участникам конкурса предъявлялось два требования. Во-первых, победитель должен был уступить Netflix права на свой алгоритм. И во-вторых, он должен был «объяснить миру, как ему удалось решить эту задачу и каким образом она работает» {27}.
В 2009 году Netflix объявила победителя. Им стала группа из семи человек, в состав которой входили статистики и программисты из США, Австрии, Канады и Израиля. Увы, я не могу описать здесь – даже в приложении – систему-победителя. Объяснение принципа ее действия занимает 92 страницы. Качество рекомендаций Netflix произвело на меня неизгладимое впечатление. Тем не менее система Netflix – просто супернавороченная вариация того, чем занимаются люди с момента появления кинематографа: найти кого-либо со схожими вкусами и попросить порекомендовать вам тот или иной фильм. Вам, как правило, нравятся те же фильмы, что и мне, и не нравятся те же фильмы, что и мне. Так что вы думаете о новом фильме Джорджа Клуни?
В этом и состоит суть корреляции.
Приложение к главе 4
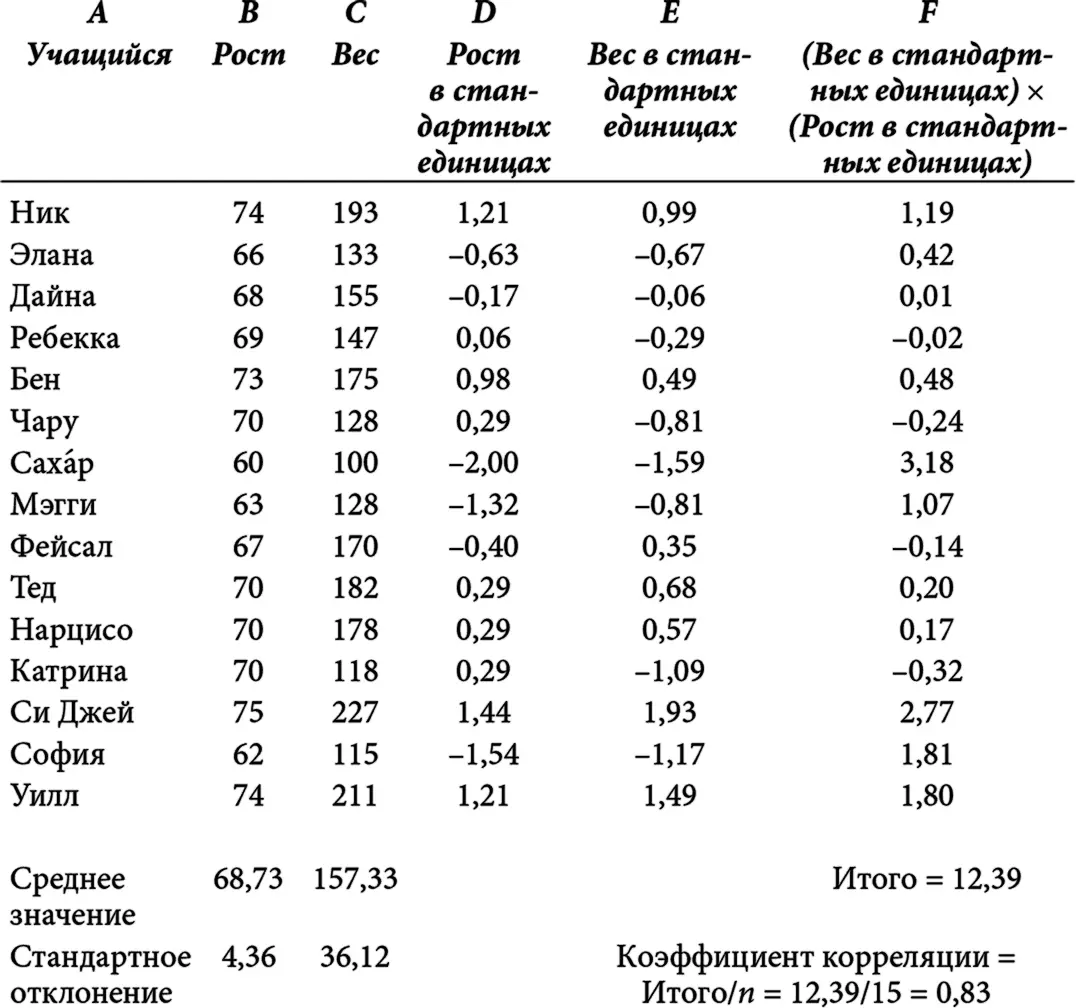
Чтобы вычислить коэффициент корреляции между двумя совокупностями чисел, вы должны выполнить перечисленные ниже действия, каждое из которых иллюстрируется путем использования данных о значениях роста и веса для 15 гипотетических учащихся в приведенной ниже таблице.
1. Преобразуйте рост каждого учащегося в стандартные единицы: (рост ‒ среднее значение) / стандартное отклонение.
2. Преобразуйте вес каждого из учащихся в стандартные единицы: (вес ‒ среднее значение) / стандартное отклонение.
3. Для каждого учащегося вычислите произведение (вес в стандартных единицах) × (рост в стандартных единицах). Вы должны увидеть, что это число будет самым большим по абсолютному значению, когда рост и вес ученика расположены относительно далеко от своих средних значений.
4. Коэффициент корреляции представляет собой сумму произведений, вычисленных выше, деленную на количество наблюдений (в нашем случае – 15).
Корреляция между ростом и весом для этой группы учащихся – 0,83. Учитывая, что коэффициент корреляции может находиться в диапазоне от −1 до 1, это относительно высокая степень положительной корреляции, чего и следовало ожидать.
A – Учащийся; B – Рост; C – Вес; D – Рост в стандартных единицах; E – Вес в стандартных единицах; F – (Вес в стандартных единицах) × (Рост в стандартных единицах)
Формула для вычисления коэффициента корреляции требует небольшого отступления, которое понадобится для того, чтобы объяснить систему обозначений, используемую в данном случае. Символ ∑ часто применяется в статистике. Он обозначает суммирование величин, которые указаны после него. Если, например, имеется некая совокупность наблюдений x 1, x 2, x 3 и x 4, то запись ∑ ( xi ) говорит о том, что мы должны суммировать четыре наблюдения: x 1 + x 2 + x 3 + x 4. Таким образом, ∑ ( xi ) = x 1 + x 2 + x 3 + x 4. Наша формула для среднего значения совокупности из n наблюдений может быть представлена в следующем виде: среднее значение = ∑ ( xi )/ n .
Мы можем придать этой формуле еще более универсальный вид, записав ее как 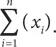 Эта формула означает суммирование величин x 1 + x 2 + x 3 +…+ xn , или, другими словами, начиная с x1 (поскольку i = 1) до xn включительно (поскольку i = n ). Наша формула для среднего значения совокупности из n наблюдений может быть представлена в следующем виде:
Эта формула означает суммирование величин x 1 + x 2 + x 3 +…+ xn , или, другими словами, начиная с x1 (поскольку i = 1) до xn включительно (поскольку i = n ). Наша формула для среднего значения совокупности из n наблюдений может быть представлена в следующем виде:
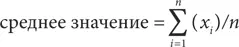
С учетом этой универсальной системы обозначений формула вычисления коэффициента корреляции r для двух переменных x и y может выглядеть так:
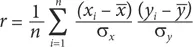
где
n – количество наблюдений;
x̅ x – среднее значение для переменной x ;
y̅ y – среднее значение для переменной y ;
σ x – стандартное отклонение для переменной x ;
σ y – стандартное отклонение для переменной y .
Любая статистическая компьютерная программа может с помощью статистических инструментов вычислить коэффициент корреляции между двумя переменными. Использование Microsoft Excel в примере с ростом и весом учащихся позволяет получить такую же корреляцию между ростом и весом пятнадцати учащихся, что и вычисление, выполненное нами вручную на основе приведенной выше таблицы: 0,83.
5. Основы теории вероятностей
Не покупайте расширенную гарантию для своего 99-долларового принтера
В 1981 году Joseph Schlitz Brewing Company потратила 1,7 миллиона долларов на необычайно смелую и рискованную маркетинговую кампанию для своего слабеющего бренда Schlitz. В перерыве матча за Суперкубок американского футбола Joseph Schlitz Brewing Company перед 100-миллионной зрительской аудиторией из разных стран мира провела в прямом эфире сравнительную дегустацию пива Schlitz Beer и его главного конкурента – пива Michelob {28}, причем участвовали в ней не случайные люди, а сотня любителей пива Michelob. Это стало кульминацией маркетинговой кампании, проходившей в ходе игр плей-офф NFL {29}. Всего транслировалось пять таких дегустаций; в каждой участвовало по 100 любителей конкурирующих сортов пива (Budweiser, Miller или Michelob), вслепую дегустировавших свой любимый сорт пива и Schlitz Beer. Каждый сеанс сопровождался рекламой, агрессивность которой не уступала агрессивности игр плей-офф (например, «Следите за сравнительной дегустацией Schlitz и Budweiser, проводимой во время игр плей-офф AFC»).
Читать дальшеИнтервал:
Закладка:







