Нихиль Будума - Основы глубокого обучения

- Название:Основы глубокого обучения
- Автор:
- Жанр:
- Издательство:Манн, Иванов и Фербер
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Нихиль Будума - Основы глубокого обучения краткое содержание
Основы глубокого обучения - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Следующий шаг — новые изменения представления каждого входного и выходного предложения. Здесь мы вводим идею группирования . Этот метод используется в основном в задачах вроде seq2seq, особенно при машинном переводе, и помогает модели эффективно обрабатывать предложения или фразы разной длины. Сначала рассмотрим простейший метод ввода обучающих данных и покажем его недостатки. При введении токенов в кодер и декодер длина исходной и целевой последовательностей в парах данных для обучения не всегда идентична. Например, исходная последовательность может иметь длину X, а целевая — Y. Кажется, что нам нужны разные сети seq2seq для каждой пары (X, Y), что сразу можно расценить как неэффективную трату сил и времени. Чуть лучше пойдут дела, если мы дополним каждую последовательность до определенной длины, как показано на рис. 7.28 (считаем, что мы используем пословное разбиение и уже добавили в целевые последовательности метки EOS).
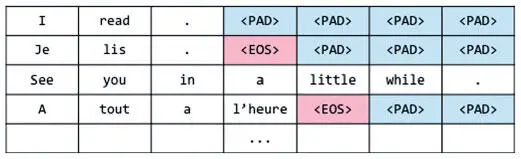
Рис. 7.28. Наивная стратегия дополнения последовательностей
Этот шаг дает возможность не создавать разные модели seq2seq для каждой пары исходной и целевой длины. Но при этом возникает проблема иного рода: если найдется очень длинная последовательность, все остальные придется дополнять до этой длины . И дополненная короткая последовательность будет требовать столько же вычислительных ресурсов, что и длинная с небольшим количеством заполнителей, а это приведет к трате сил и может крайне негативно сказаться на производительности нашей модели. Допустимо разбить каждую последовательность в корпусе на фразы, чтобы длина каждой из них не превышала определенного максимального значения, но не вполне понятно, как разбивать переводы. Здесь-то и поможет группирование.
Группирование основано на том, что пары кодера и декодера можно поместить в группы сходного размера и дополнять до максимальной длины последовательности в каждой соответствующей группе. Например, допустимо обозначить ряд групп [(5, 10), (10, 15), (20, 25), (30,40)], где каждая запись — максимальная длина исходной и целевой последовательностей соответственно. Если вернуться к предыдущему примеру, то можно поместить пару последовательностей (["I", "read", "."], ["Je", "lis", ".", "EOS"]) в первую группу, поскольку исходное предложение меньше пяти токенов, а целевое — меньше 10. Во вторую группу помещаем набор (["See", "you", "in", "a", "little", "while"], ["A", "tout", "a","l'heure", "EOS]) и т. д. Этот метод позволяет найти компромисс между двумя экстремумами: теперь дополнять можно ровно столько, сколько необходимо, что и показано на рис. 7.29.
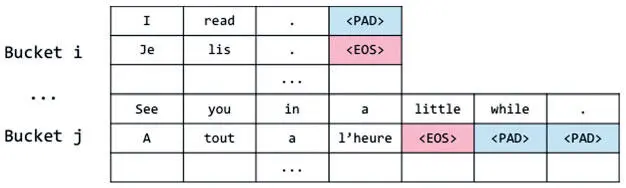
Рис. 7.29. Дополнение последовательностей в группах
Группирование позволяет существенно ускорить время обучения и тестирования, а разработчикам дает возможность писать оптимизированный код, используя то обстоятельство, что все последовательности из одной группы имеют один размер, и упаковывать данные для повышения эффективности работы GPU.
Как только все дополнения последовательностей выполнены, добавляем в целевые последовательности еще один токен — GO . Он говорит декодеру, что пора начать декодирование. Тот действует соответственно.
Последнее, что нужно делать во время подготовки данных, — переворачивать исходные предложения. Исследователи установили, что это повышает эффективность, и это действие стало стандартным при обучении нейронных моделей машинного перевода. Это своего рода трюк, но вспомните, что наше нейронное состояние фиксированного размера и, соответственно, не может содержать информации больше определенного предела. Получается, информация, закодированная при обработке начала предложения, может подвергнуться перезаписи при кодировании последующих фрагментов.
Во многих языковых парах начало предложений перевести сложнее, чем конец, и переворачивание повышает точность: последнее слово на финальной стадии кодирования остается за началом последовательности. После реализации всех этих идей конечные последовательности должны выглядеть так, как на рис. 7.30.
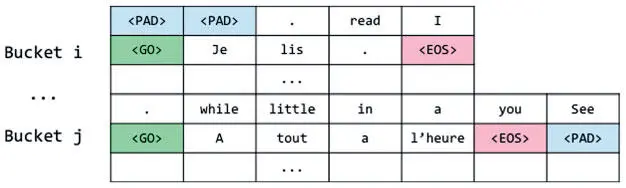
Рис. 7.30. Итоговая схема дополнения в группах после переворачивания данных и добавления метки GO
Описав эти техники, мы можем перейти к подробностям реализации. Идеи реализованы в методе get_batch() кода. Он получает отдельный пакет обучающих данных, учитывая bucket_id, который берется из цикла обучения. В результате создаются токены для исходного и целевого предложений, метод задействует все описанные выше техники, включая дополнение в группах и переворачивание ввода:
def get_batch(self, data, bucket_id):
encoder_size, decoder_size = self.buckets[bucket_id]
encoder_inputs, decoder_inputs = [], []
Сначала мы задаем заполнители для каждого входного значения, поступающего в кодер и декодер:
for _ in xrange(self.batch_size):
encoder_input, decoder_input = random.choice(data[bucket_id])
# Encoder inputs are padded and then reversed. (Входные данные кодера дополняются и переворачиваются)
encoder_pad = [data_utils.PAD_ID] * (encoder_size — len(encoder_input))
encoder_inputs.append(list(reversed(encoder_input + encoder_pad)))
# Decoder inputs get an extra "GO" symbol,
# and are then padded. (Входные данные декодера получают дополнительный символ "GO" и затем переворачиваются)
decoder_pad_size = decoder_size — len(decoder_input) — 1
decoder_inputs.append([data_utils.GO_ID] + decoder_input + [data_utils.PAD_ID] * decoder_pad_size)
В соответствии с размером пакета мы берем соответствующее количество кодирующих и декодирующих последовательностей:
# Now we create batch-major vectors from the data selected
# above. (Теперь создаем пакетные векторы на основании выбранных выше данных)
batch_encoder_inputs, batch_decoder_inputs, batch_weights =
[], [], []
# Batch encoder inputs are just re-indexed encoder_inputs. (Пакетные вводы кодера — переформатированные encoder_inputs)
for length_idx in xrange(encoder_size):
batch_encoder_inputs.append(
np.array([encoder_inputs[batch_idx][length_idx]
for batch_idx in xrange(self.batch_size)],
dtype=np.int32))
# Batch decoder inputs are re-indexed decoder_inputs,
# we create weights. (Пакетные вводы декодера — переформатированные decoder_inputs, мы назначаем веса)
for length_idx in xrange(decoder_size):
batch_decoder_inputs.append(
np.array([decoder_inputs[batch_idx][length_idx]
for batch_idx in xrange(self.batch_size)], dtype=np.int32))
Убеждаемся, что первое измерение тензора — размер мини-пакета, и преобразуем определенные ранее заполнители в нужный формат:
# Create target_weights to be 0 for targets that
# are padding. (Назначаем target_weights равными 0 для дополнений в целевой последовательности)
batch_weight = np.ones(self.batch_size, dtype=np.float32)
for batch_idx in xrange(self.batch_size):
# We set weight to 0 if the corresponding target is
# a PAD symbol. (Назначаем вес 0, если соответствующая цель — символ PAD)
# The corresponding target is decoder_input shifted
Читать дальшеИнтервал:
Закладка:









