Нихиль Будума - Основы глубокого обучения

- Название:Основы глубокого обучения
- Автор:
- Жанр:
- Издательство:Манн, Иванов и Фербер
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Нихиль Будума - Основы глубокого обучения краткое содержание
Основы глубокого обучения - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
def lstm(input, hidden_dim, keep_prob, phase_train):
lstm = tf.nn.rnn_cell.BasicLSTMCell(hidden_dim)
dropout_lstm = tf.nn.rnn_cell.DropoutWrapper(lstm,
input_keep_prob=keep_prob,
output_keep_prob=keep_prob)
# stacked_lstm = tf.nn.rnn_cell.MultiRNNCell(
[dropout_lstm] * 2,
state_is_tuple=True)
lstm_outputs, state = tf.nn.dynamic_rnn(dropout_lstm,
input, dtype=tf.float32)
return tf.squeeze(tf.slice(lstm_outputs,
[0, tf.shape(
lstm_outputs)[1]-1, 0],
[tf.shape(lstm_outputs)[0],
1, tf.shape(
lstm_outputs)[2]])
В завершение мы добавляем скрытый слой пакетной нормализации, идентичный тем, которые мы использовали в предыдущих примерах. Собрав все компоненты вместе, мы можем перейти к построению графа логического вывода:
def inference(input, phase_train):
embedding = embedding_layer(input, [30000, 512])
lstm_output = lstm(embedding, 512, 0.5, phase_train)
output = layer(lstm_output, [512, 2], [2], phase_train)
return output
Опустим остальной шаблонный код, который сохраняет сводную статистику, промежуточные состояния и создает сессию: он такой же, как и остальные модели, уже созданные в этой книге; вы можете посмотреть исходный код в репозитории GitHub. Теперь можно запустить и визуализировать работу модели при помощи TensorBoard (рис. 7.23).
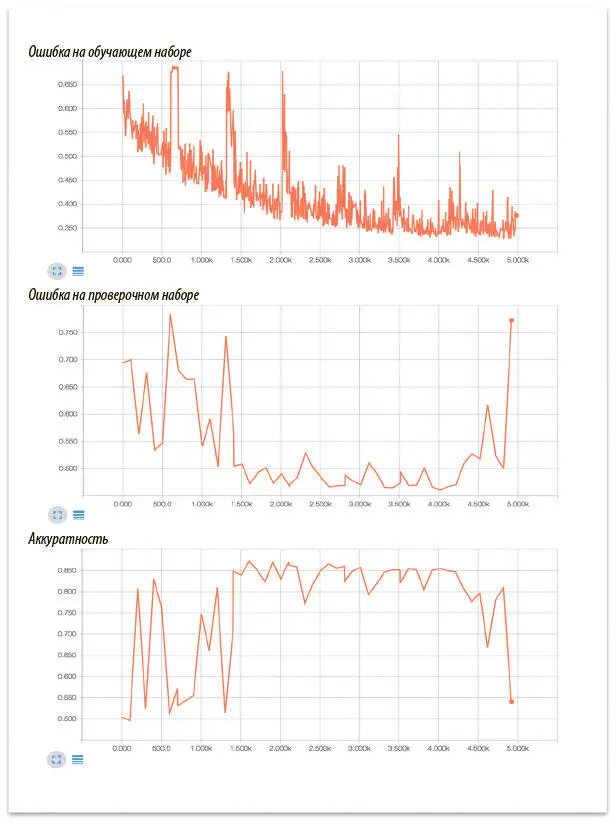
Рис. 7.23. Ошибка на обучающем и проверочном наборах данных, а также аккуратность модели анализа эмоциональной окраски кинорецензий
В начале обучения модель несколько нестабильна, а в конце явно происходит переобучение, поскольку ошибки на обучающем и проверочном наборах начинают сильно различаться. В период же оптимальной работы модель демонстрирует эффективные результаты и показывает на тестовом наборе данных аккуратность примерно 86%. Поздравляем! Вы создали свою первую рекуррентную нейронную сеть.
Решение задач класса seq2seq при помощи рекуррентных нейронных сетей
Теперь мы хорошо понимаем работу рекуррентных нейронных сетей и можем вернуться к проблеме seq2seq. Мы начали эту главу примером задачи класса seq2seq — привязкой последовательности слов в предложении к последовательности меток частей речи.
Работать с этой проблемой было можно, поскольку для создания соответствующих меток не требовалось учитывать долгосрочные зависимости. Но некоторые проблемы seq2seq, например перевод с одного языка на другой или создание резюме к видеофайлу, таковы, что долгосрочные зависимости в них крайне важны для успеха. И тут в дело вступают РНС.
Работа РНС с seq2seq во многом напоминает работу автокодера, о которой шла речь в предыдущей главе. Модель seq2seq состоит из двух отдельных сетей. Первая называется кодер (encoder) . Это рекуррентная сеть (обычно использующая нейроны LSTM), которая читает всю входную последовательность. Цель ее — создать сжатое понимание входных данных и выразить его в единой «мысли», представленной конечным состоянием сети. Затем используется декодер (decoder) , начальное состояние которой инициализируется конечным состоянием кодера. Символ за символом генерируется выходная последовательность. На каждом шаге декодер использует собственные выходные данные с предыдущего шага в качестве входных данных текущего шага. Весь процесс представлен на рис. 7.24.
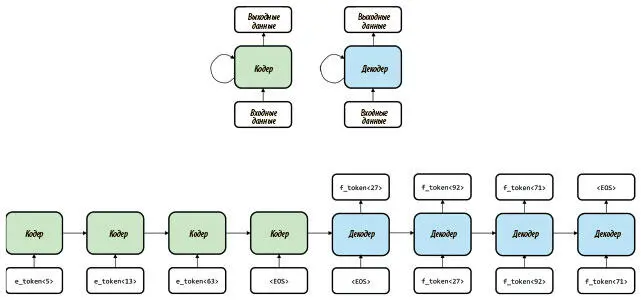
Рис. 7.24. Иллюстрация использования схемы рекуррентной сети кодера-декодера для решения задач класса seq2seq
В этом примере мы попробуем перевести предложение с английского на французский. Мы токенизируем входное предложение и используем плотное векторное представление (так же, как для модели анализа эмоциональных состояний, созданной в предыдущем разделе), загружая по слову в кодер. В конце предложения мы ставим специальную метку (end of sentence, EOS), которая отмечает конец входного предложения для кодера.
Теперь берем скрытое состояние последней для инициализации декодера. Первый элемент на входе в нее — метка EOS, а выходное значение интерпретируется как первое слово предсказанного французского перевода.
С этого момента мы используем выходные данные декодера как входные данные в нее же на следующем шаге. Продолжаем, пока кодер не выдаст на выходе метку EOS, что будет свидетельствовать об окончании работы над переводом исходного английского предложения. Мы проанализируем открытую рабочую реализацию этой сети (с парой улучшений и хитростей для повышения точности) ниже.
Архитектура РНС для seq2seq может быть использована и для обучения хорошим плотным векторным представлениям последовательностей. Например, Райан Кирос и коллеги в 2015 году ввели понятие вектора skip-thought [91], который по архитектурным характеристикам напоминал как структуру автокодера, так и модель Skip-Gram (см. главу 6). Вектор skip-thought был создан путем разбиения фрагмента на серию триплетов, состоящих из последовательных предложений. Авторы воспользовались одним кодером и двумя декодерами (рис. 7.25).
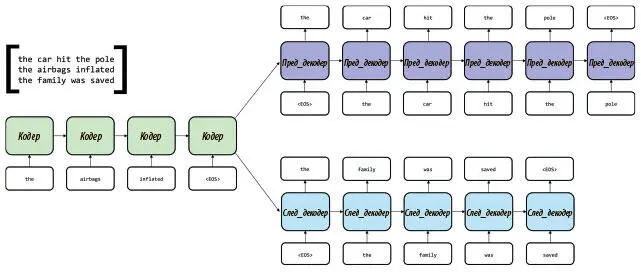
Рис. 7.25. Архитектура skip-thought для seq2seq порождает компактные векторные представления для целых предложений
Кодер прочел предложение, плотное векторное представление которого (хранимое в последнем конечном состоянии кодера) мы и намеревались создать. Затем начался этап декодирования. Первая из сетей использовала это представление для инициализации собственного скрытого состояния и попыталась воссоздать предложение, предшествовавшее введенному. Вторая старалась воссоздать предложение, непосредственно следующее за введенным. Вся система была полностью обучена на этих триплетах и после завершения могла выдавать связные фрагменты текста; кроме того, повысилась эффективность решения ключевых задач на уровне предложений. Вот пример порождения рассказа из исходной статьи:
she grabbed my hand.
"come on. "
she fluttered her back in the air.
"i think we're at your place. I ca n't come get you. "
he locked himself back up
" no. she will. "
kyrian shook his head [92]
Теперь, поняв, как применять рекуррентные нейронные сети к задачам класса seq2seq, мы почти готовы создать свой вариант. Но сначала нужно разобраться еще с одной проблемой, к которой мы и перейдем в следующем разделе: идеей внимания в РНС для seq2seq.
Дополнение рекуррентных сетей вниманием
Продолжим разговор о проблемах перевода. Если вы когда-то пытались выучить иностранный язык, то знаете, что именно помогает успешному переводу. Во-первых, стоит полностью прочесть предложение, чтобы понять, какую идею нужно передать. Затем вы слово за словом записываете перевод, и каждое слово вытекает из предыдущего. При этом, составляя новое предложение, вы часто обращаетесь к исходному тексту, сосредоточиваясь на определенных фрагментах, которые важны для текущего перевода. На каждом шаге вы обращаете внимание на самые важные в данный момент части «входных данных», чтобы принять наилучшее решение по поводу следующего слова, которое должно будет появиться на бумаге.
Читать дальшеИнтервал:
Закладка:









