Нихиль Будума - Основы глубокого обучения

- Название:Основы глубокого обучения
- Автор:
- Жанр:
- Издательство:Манн, Иванов и Фербер
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Нихиль Будума - Основы глубокого обучения краткое содержание
Основы глубокого обучения - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
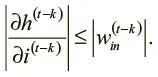
В результате получаем итоговое неравенство (которое можно упростить, поскольку мы хотим, чтобы связи на разных шагах имели одинаковые значения):
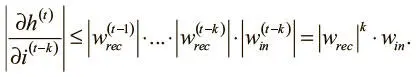
Это отношение устанавливает жесткую верхнюю границу того, как изменения во входных данных на шаге ( t − k) влияют на скрытое состояние на шаге t . Поскольку веса нашей модели в начале обучения невелики, значение этой производной с возрастанием k стремится к 0. Иными словами, градиент быстро уменьшается, когда он вычисляется по входным данным на несколько шагов назад, что существенно ограничивает способность модели к изучению долгосрочных зависимостей. Эта проблема обычно называется проблемой исчезающего градиента . Она серьезно влияет на способности обычных рекуррентных нейронных сетей к обучению. Наша задача — устранить эти ограничения, и в следующем разделе мы поговорим о чрезвычайно эффективном подходе к рекуррентным слоям, который именуется долгой краткосрочной памятью.
Нейроны долгой краткосрочной памяти (long short-term memory, LSTM)
Для борьбы с проблемой исчезающего градиента Зепп Хохрайтер и Юрген Шмидхубер ввели архитектуру долгой краткосрочной памяти (LSTM). Основной ее принцип таков: сеть создается для надежного переноса важной информации на много шагов в будущее. Эти соображения привели к созданию архитектуры, показанной на рис. 7.17.
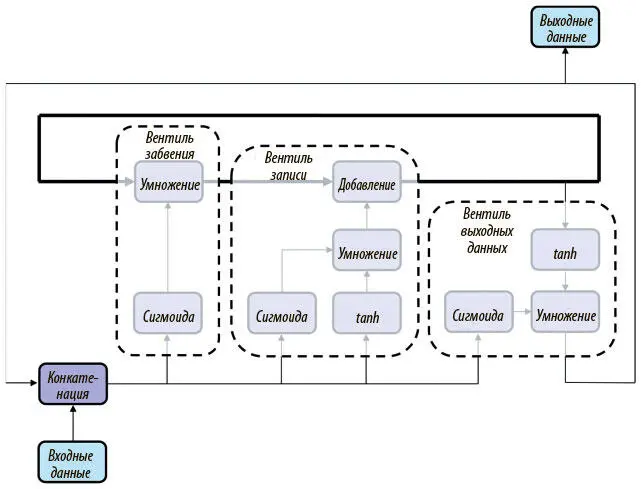
Рис. 7.17. Архитектура нейрона LSTM на уровне тензоров (стрелки) и операций (сиреневые блоки)
Для простоты обсуждения отойдем от уровня отдельных нейронов и будем говорить о сети как о наборе тензоров и операций над ними.
Как ясно из рисунка, нейрон LSTM состоит из нескольких ключевых компонентов. Один из них — ячейка памяти , тензор, выделенный жирным в центре рисунка. Она содержит важную информацию, которую усвоила со временем, а сеть призвана эффективно сохранять в ней эту полезную информацию на протяжении нескольких шагов. На каждом шаге нейрон LSTM изменяет ячейку памяти, снабжая ее новой информацией в три этапа. Сначала он должен определить, какую часть предшествующей информации следует хранить, при помощи вентиля забвения (рис. 7.18).
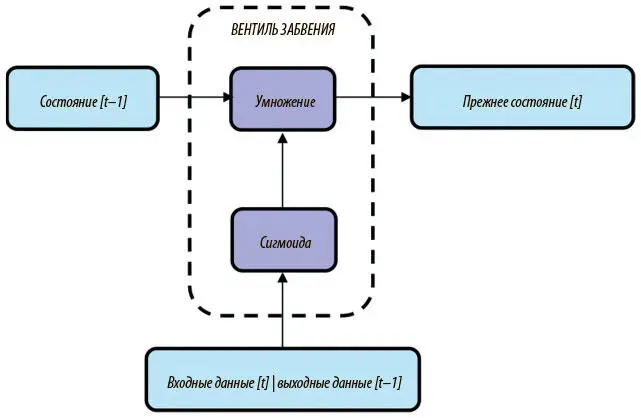
Рис. 7.18. Архитектура вентиля забвения нейрона LSTM
Основная идея проста. Тензор состояния памяти с предыдущего шага насыщен информацией, но часть ее может быть устаревшей, и ее следует стереть. Мы выясняем, какие элементы тензора релевантны, а какие уже нет, вычисляя двоичный тензор (состоящий из нулей и единиц), который мы умножаем на предыдущее состояние. Если соответствующее место в двоичном тензоре содержит 1, это значит, что место ячейки памяти по-прежнему значимо и его нужно сохранить. Если же на этом месте 0, оно утратило значимость и его следует забыть.
Мы аппроксимируем этот двоичный тензор, соединив входные данные этого шага и выходные данные нейрона LSTM с предыдущего и наложив на полученный тензор сигмоидный слой (sigmoid). Как вы наверняка помните, последний на выходе дает значение, которое обычно очень близко к 0 или 1 (единственное исключение — если входное значение само близко к 0). Выходные данные сигмоидного слоя — хорошее приближение двоичного тензора, чем можно воспользоваться при построении вентиля забвения. Поняв, какую информацию от прежних состояний следует сохранить, а какую забыть, мы переходим к той, которую нужно добавить в память. Эта часть нейрона LSTM называется вентилем записи , и она показана на рис. 7.19. Она делится на две основные части. Первая определяет, какую информацию мы хотим добавить в состояние. Это вычисляется в слое tanh путем создания промежуточного тензора. Второй компонент определяет, какие части этого тензора мы хотим ввести в новое состояние, а какие выбросить и не записывать. Для этого мы аппроксимируем двоичный вектор из нулей и единиц с помощью той же стратегии (сигмоидного слоя), что и для вентиля забвения. Затем мы умножаем двоичный вектор на промежуточный тензор и добавляем полученный результат, создавая новый вектор состояния для LSTM.
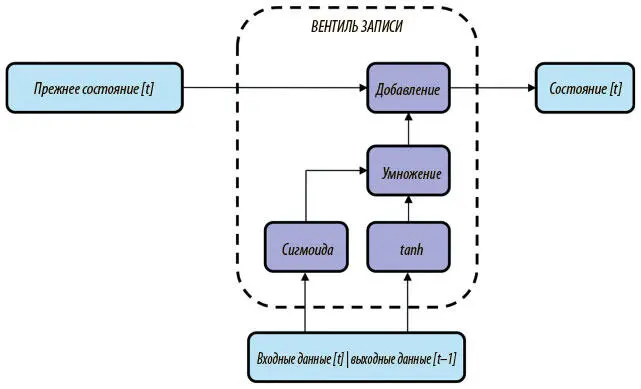
Рис. 7.19. Архитектура вентиля записи в нейроне LSTM
Наконец, на каждом временном шаге нейрон LSTM должен выдавать данные. Можно воспринимать вектор состояния как выходные данные, но нейрон LSTM призван обеспечить большую гибкость, передавая на выход тензор — «интерпретацию» или внешнюю «коммуникацию» того, что содержит вектор состояния. Архитектура выходного вентиля показана на рис. 7.20. Мы используем структуру, почти идентичную реализованной для вентиля записи: слой tanh порождает промежуточный тензор от вектора состояния; сигмоидный слой создает маску двоичного тензора на основе текущего ввода и предыдущего вывода; промежуточный тензор умножается на двоичный тензор, что дает нам конечные выходные данные.
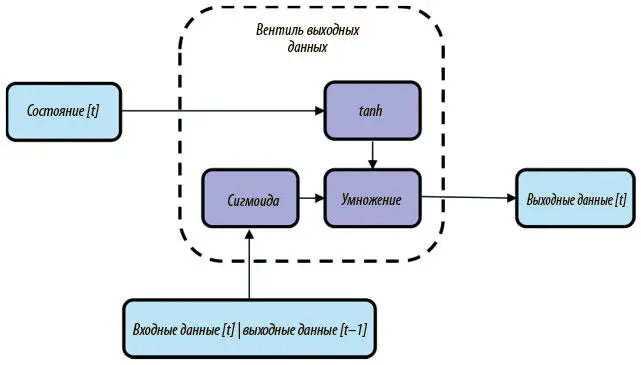
Рис. 7.20. Архитектура выходного вентиля в нейроне LSTM
Почему этот вариант лучше, чем обычный нейрон РНС? Главное здесь то, как информация распространяется по сети, когда мы разворачиваем нейрон LSTM во времени. Развернутая архитектура показана на рис. 7.21.
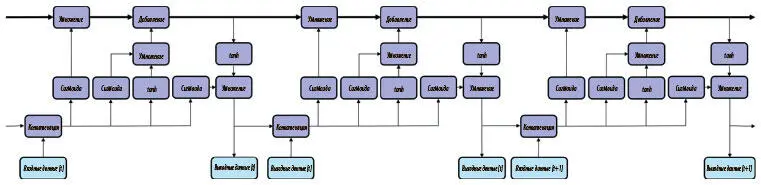
Рис. 7.21. Разворачивание нейрона LSTM во времени
На самом верху видно распространение вектора состояния, взаимодействия которого во времени в основном линейны. В результате градиент, который связывает входные данные, поступившие за несколько временных шагов до этого, с текущими выходными данными, не затухает так резко, как в обычной архитектуре РНС. А значит, LSTM может обучаться долгосрочным связям гораздо эффективнее, чем в исходной формулировке РНС.
Наконец, нужно понять, насколько легко порождать произвольные архитектуры при помощи нейрона LSTM. Насколько они «компонуемы»? Не придется ли при использовании нейронов LSTM вместо обычных РНС пожертвовать гибкостью? Мы можем соединять их для большей выразительности так же, как соединяли обычные нейроны РНС, где вход второго нейрона будет выходом первого, вход третьего — выходом второго и т. д. Иллюстрация того, как это работает, показана на рис. 7.22, где из двух нейронов LSTM составлено целое. Это значит, что обычные слои РНС всегда можно заменить нейронами LSTM.
Читать дальшеИнтервал:
Закладка:









