Нихиль Будума - Основы глубокого обучения

- Название:Основы глубокого обучения
- Автор:
- Жанр:
- Издательство:Манн, Иванов и Фербер
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Нихиль Будума - Основы глубокого обучения краткое содержание
Основы глубокого обучения - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
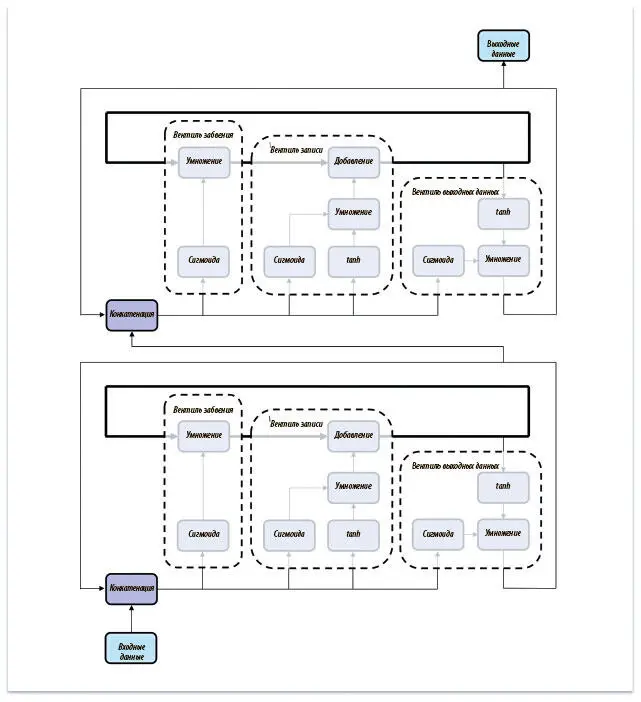
Рис. 7.22. Соединение нейронов LSTM ничем не отличается от соединения рекуррентных слоев нейронной сети
Итак, мы решили проблему исчезающего градиента и познакомились с работой нейронов LSTM. Теперь мы готовы заняться реализацией наших первых моделей РНС.
Примитивы TensorFlow для моделей РНС
TensorFlow предлагает несколько примитивов, которые можно использовать для создания моделей РНС. Во-первых, есть объекты tf.RNNCell, которые представляют либо слой РНС, либо LSTM:
cell_1 = tf.nn.rnn_cell.BasicRNNCell(num_units, input_size=None, activation=tanh)
cell_2 = tf.nn.rnn_cell.BasicLSTMCell(num_units, forget_bias=1.0, input_size=None, state_is_tuple=True, activation=tanh)
cell_3 = tf.nn.rnn_cell.LSTMCell(num_units, input_size=None, use_peepholes=False, cell_clip=None, initializer=None, num_proj=None, proj_clip=None, num_unit_shards=1, num_proj_shards=1, forget_bias=1.0, state_is_tuple=True, activation=tanh)
cell_4 = tf.nn.rnn_cell.GRUCell(num_units, input_size=None, activation=tanh)
Абстракция BasicRNNCell представляет обычный рекуррентный нейронный слой. BasicLSTMCell соответствует простейшей реализации LSTM, а LSTMCell — реализации с большим количеством возможностей конфигурации (замочные скважины, клипирование переменных состояния и т. д.). Библиотека TensorFlow также содержит разновидность нейрона LSTM, известную как вентильная рекуррентная единица (Gated Recurrent Unit, GRU) и предложенную в 2014 году группой Джошуа Бенджо. Важнейший параметр для всех этих нейронов — размер вектора скрытого состояния, или num_units.
Кроме примитивов, в нашем арсенале есть несколько надстроек. Если мы хотим соединить рекуррентные нейроны или слои, можно сделать следующее:
cell_1 = tf.nn.rnn_cell.BasicLSTMCell(10)
cell_2 = tf.nn.rnn_cell.BasicLSTMCell(10)
full_cell = tf.nn.rnn_cell.MultiRNNCell([cell_1, cell_2])
Также можно при помощи надстройки применить прореживание ко входам и выходам LSTM с указанными вероятностями остаточной памяти входа и выхода:
cell_1 = tf.nn.rnn_cell.BasicLSTMCell(10)
tf.nn.rnn_cell.DropoutWrapper(cell_1, input_keep_prob=1.0, output_keep_prob=1.0 seed=None)
Завершаем мы создание РНС, упаковывая всё в соответствующий примитив Tensor Flow:
outputs, state = tf.nn.dynamic_rnn(cell, inputs, sequence_length=None, initial_state=None, dtype=None, parallel_iterations=None, swap_memory=False, time_major=False, scope=None)
Ячейка (cell) — объект RNNCell, который мы уже создали. Если time_major == False (значение по умолчанию), входные данные должны быть тензором вида [batch_size, max_time, …]. Если же time_major == True, входной тензор должен принять форму [max_time, batch_size, …]. Подробности есть в документации TensorFlow, где можно узнать больше и о других параметрах конфигурации.
Результат обращения к tf.nn.dynamic_rnn — тензор, представляющий выход РНС вместе с вектором конечного состояния. Если time_major == False, вывод будет иметь форму [batch_size, max_time, cell.output_size]. Иначе тензор должен иметь вид [max_time, batch_size, cell.output_size]. Состояние, как можно ожидать, будет иметь форму [batch_size, cell.state_size].
Познакомившись с инструментами для создания рекуррентных нейронных сетей, которые есть в TensorFlow, мы построим первую LSTM, решающую задачу анализа эмоциональной окраски.
Реализация модели анализа эмоциональной окраски
Здесь мы попробуем проанализировать эмоциональную окраску рецензий на кинофильмы из базы данных Large Movie Review Dataset. Она состоит из 50 тысяч рецензий с сайта IMDB, каждая из которых помечена как положительная или отрицательная с эмоциональной точки зрения. Мы возьмем простую модель LSTM с прореживанием, чтобы понять, как классифицировать эмоциональную окраску. Рецензии будут поступать в модель по слову за раз. По окончании процесса мы возьмем выходное значение модели за основу двоичной классификации, которая пометит эмоциональную окраску как «положительную» или «отрицательную». Начнем с загрузки базы данных. Воспользуемся вспомогательной библиотекой tflearn. Установить ее можно с помощью следующей команды:
$ pip install tflearn
Теперь можно загрузить базу данных, выбрать из словаря 30 тысяч самых распространенных слов, ограничить длину входных последовательностей 500 словами [90]и обработать метки:
from tflearn.data_utils import to_categorical, pad_sequences
from tflearn.datasets import imdb
train, test, _ = imdb.load_data(path='data/imdb.pkl',
n_words=30000,
valid_portion=0.1)
trainX, trainY = train
testX, testY = test
trainX = pad_sequences(trainX, maxlen=500, value=0.)
testX = pad_sequences(testX, maxlen=500, value=0.)
trainY = to_categorical(trainY, nb_classes=2)
testY = to_categorical(testY, nb_classes=2)
Теперь наши входные данные — 500-мерные векторы. Каждый соответствует кинорецензии, причем i -й компонент вектора сопоставлен индексу i -го слова в рецензии в нашем общем словаре из 30 тысяч единиц. Чтобы закончить подготовку, создадим особый класс Python для подачи мини-пакетов желаемого размера из основной базы данных:
class IMDBDataset():
def __init__(self, X, Y):
self.num_examples = len(X)
self.inputs = X
self.tags = Y
self.ptr = 0
def minibatch(self, size):
ret = None
if self.ptr + size < len(self.inputs):
ret = self.inputs[self.ptr: self.ptr+size], self.tags[self.ptr: self.ptr+size]
else:
ret = np.concatenate((self.inputs[self.ptr: ], self.inputs[: size-len(self.inputs[self.ptr: ])])),
np.concatenate((self.tags[self.ptr: ], self.tags[: size-len(self.tags[self.ptr: ])]))
self.ptr = (self.ptr + size) % len(self.inputs)
return ret
train = IMDBDataset(trainX, trainY)
val = IMDBDataset(testX, testY)
Класс Python IMDBDataset используется для подачи как обучающих, так и проверочных данных, которые будут использоваться в обучении нашей модели анализа эмоциональной окраски.
Итак, данные готовы, приступим к пошаговому созданию модели анализа эмоциональной окраски. Для начала нужно привязать каждое слово из входной рецензии к вектору слов. Для этого используется слой плотного векторного представления, который, как вы наверняка помните из предыдущей главы, представляет собой простую таблицу соответствия. Она хранит вектор плотного представления, сопоставленный каждому слову. В отличие от предыдущих примеров, когда обучение векторных представлений слов мы рассматривали как отдельную проблему (и создавали, например, модель Skip-Gram), мы будем обучать векторные представления слов вместе с проблемой анализа эмоциональной окраски и считать матрицу векторных представлений матрицей параметров общей проблемы. Воспользуемся примитивами TensorFlow для управления плотными векторными представлениями (помните, что входные данные — это один полный мини-пакет, а не просто вектор кинорецензии):
def embedding_layer(input, weight_shape):
weight_init = tf.random_normal_initializer(stddev=(1.0/weight_shape[0])**0.5)
E = tf.get_variable("E", weight_shape, initializer=weight_init)
incoming = tf.cast(input, tf.int32)
embeddings = tf.nn.embedding_lookup(E, incoming)
return embeddings
Затем берем результат из слоя векторных представлений слов и строим LSTM с прореживанием при помощи тех же примитивов, что и в предыдущем разделе. Проделаем небольшую дополнительную работу, чтобы сохранить последнее значение, выданное LSTM, при помощи операторов tf.slice и tf.squeeze, которые находят фрагмент, где содержится последний вывод LSTM, и устраняют ненужные измерения. Смена измерений выглядит так:
[batch_size, max_time, cell.output_size] to [batch_size, 1, cell.out put_size] to [batch_size, cell.output_size].
Реализовать LSTM можно следующим образом:
Читать дальшеИнтервал:
Закладка:









