Нихиль Будума - Основы глубокого обучения

- Название:Основы глубокого обучения
- Автор:
- Жанр:
- Издательство:Манн, Иванов и Фербер
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг:
- Избранное:Добавить в избранное
-
Отзывы:
-
Ваша оценка:
Нихиль Будума - Основы глубокого обучения краткое содержание
Основы глубокого обучения - читать онлайн бесплатно ознакомительный отрывок
Интервал:
Закладка:
Вернемся к нашему подходу к seq2seq. Прочтя полностью входные данные и резюмируя их в виде «мысли» в скрытом состоянии, сеть кодера фактически копирует первую часть процесса перевода. Используя предшествующие выходные данные как текущие входные, сеть декодера реализует вторую часть процесса. Это явление внимания еще не отражено в нашем подходе к seq2seq, так что сейчас мы этим и займемся.
Единственные входные данные декодера на шаге t — его выходные на шаге ( t − 1). Один из способов дать сети декодера представление об исходном предложении — предоставить доступ ко всему выводу кодера (который мы пока игнорировали). Эти выходные данные интересуют нас, поскольку отражают изменение внутреннего состояния кодера после поступления каждого нового токена. Предлагаемая реализация этой стратегии показана на рис. 7.26.
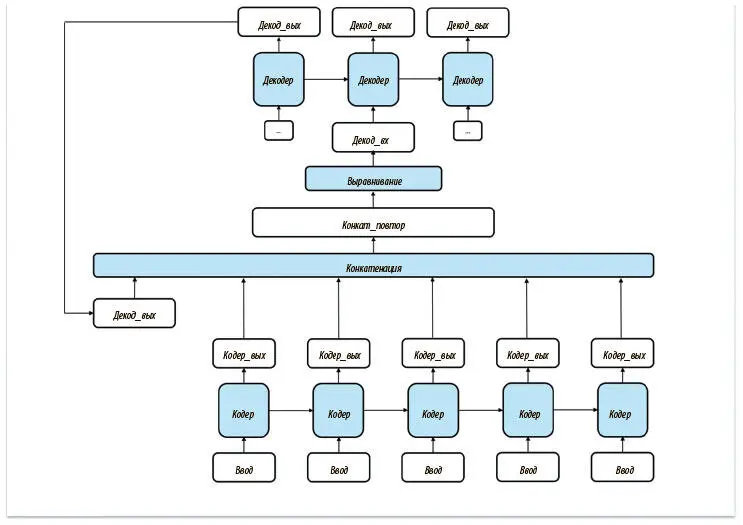
Рис. 7.26. Попытка ввести внимание в архитектуру seq2seq. Нас ждет неудача, поскольку сеть не может динамически выбирать самые важные части входных данных и сосредоточиваться на них
Но у этого подхода обнаруживается важный недостаток. На каждом шаге декодер рассматривает все выходные данные кодера одинаково. Человек же в процессе перевода действует не так. Работая над разными фрагментами, мы сосредоточиваемся на разных аспектах оригинала. Важно понять, что дать декодеру доступ ко всем выходным данным недостаточно. Нужно придумать механизм, с помощью которого он мог бы динамически обращать внимание на конкретную подвыборку выходных данных кодера.
Проблему можно решить, подвергнув входные данные конкатенации. Поможет в этом предложение, внесенное в 2015 году Дмитрием Баданау и коллегами [93]. Вместо того чтобы непосредственно работать с сырыми выходными данными из кодера, мы присваиваем им веса. Для этого используем состояние сети декодера в момент ( t − 1) как основу.
Операция присвоения весов показана на рис. 7.27. Сначала назначаем скалярный (одно число, а не тензор) коэффициент релевантности для каждого выходного значения кодера. Для этого вычисляем скалярное произведение каждого вывода кодера и состояния декодера на шаге ( t − 1). Затем нормализуем эти результаты с помощью операции мягкого максимума. Наконец, с помощью нормализованных результатов индивидуально оцениваем все выходные значения кодера, прежде чем начать конкатенацию. Важно, что относительные показатели для каждого выходного значения кодера отражают степень его важности для решения декодера на шаге t . Позже мы покажем, как визуализировать то, какие элементы выходных данных наиболее важны для перевода на каждом шаге, с помощью анализа выходных данных операции мягкого максимума.
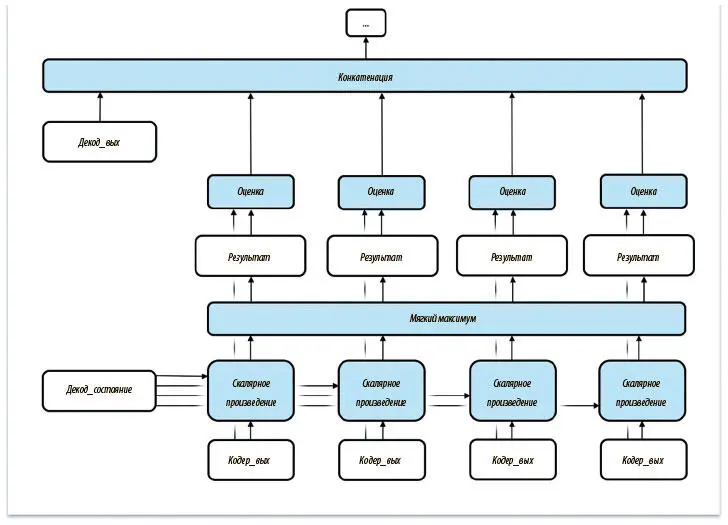
Рис. 7.27. Внесение изменений в первичный вариант позволяет создать динамический механизм внимания на основе скрытого состояния сети декодера на предыдущем шаге
Вооружившись пониманием стратегии введения внимания в архитектуру seq2seq, мы готовы заняться построением модели РНС для перевода английских предложений на французский. Но сначала стоит отметить, что внимание очень важно и для других проблем, не связанных с переводом. Оно может сыграть свою роль в задаче распознавания языка, когда алгоритм обучается динамически обращать внимание на соответствующие части аудиофайла при его переводе в текст. Оно применимо для улучшения алгоритма описания изображений и дает ему возможность фокусироваться на конкретных фрагментах входного изображения при создании описания. Если существуют отдельные элементы входных данных, которые тесно связаны с верным воспроизводством соответствующих сегментов выходных данных, внимание может существенно повысить производительность.
Разбор нейронной сети для перевода
Современные нейронные сети для перевода используют ряд методов и достижений, основанных всё на той же архитектуре кодера-декодера seq2seq. Внимание, рассмотренное в предыдущем разделе, — жизненно важное новшество. Ниже мы разберем полностью реализованную нейронную систему машинного перевода, дополним ее обработкой данных, построим модель, обучим ее и используем в качестве системы перевода английских фраз на французский! Работать мы будем с упрощенной версией официального учебного кода для машинного перевода TensorFlow [94].
Обучение и последующее использование нейронной системы машинного перевода очень похожи на большинство других процессов в области машинного обучения: сбор данных, их подготовка, построение модели, ее обучение, оценка ее качества и, наконец, использование обученной модели для получения полезных предсказаний или выводов. Все эти этапы мы и рассмотрим.
Сначала мы получаем данные из репозитория WMT'15, который содержит большие массивы, используемые для обучения систем перевода. Мы воспользуемся англо-французскими данными. Заметим, что если нужно будет переводить с нескольких или на несколько языков, то придется с нуля обучать модель на новых данных. Предварительно обрабатываем данные, преобразуя их в формат, который модели смогут использовать при обучении и логическом выводе. Для этого надо провести чистку и разбиение на токены предложений в каждой английской и французской фразе. Мы приведем методы, используемые в подготовке данных, и поговорим об их реализации.
Первый шаг — преобразовать предложения и фразы в совместимый с моделью формат путем разбиения на токены , или составляющие (и для английских, и для французских фраз). Например, простой пословный токенизатор, получив предложение I read. («я читаю»), выдаст набор ["I", "read","."], а из французского предложения Je lis. сделает набор ["Je", "lis","."]. Посимвольный токенизатор разобьет предложение на отдельные символы или пары символов, получится ["I", " ", "r", "e", "a", "d", "."] и ["I", " "re", "ad", "."] соответственно.
В каждом случае нужно решить, какое разбиение лучше: у обоих есть свои достоинства и недостатки. Например, пословный токенизатор обеспечит выдачу слов из словаря, но размер последнего может быть слишком велик для эффективного выбора во время декодирования. Эта проблема известна, мы обратимся к ней позже. Токенизатор на основе посимвольного разбиения не всегда может выдать читабельные данные, но словарь, из которого декодер выбирает варианты, гораздо меньше: это набор всех печатаемых символов ASCII. Мы используем пословное разбиение, но читателю предлагаем поэкспериментировать с разными вариантами и посмотреть на результаты. Нам придется добавить EOS — особый символ конца последовательности — по окончании всех входных последовательностей, поскольку нам нужен способ указать декодеру, что он завершил работу. Обычную пунктуацию использовать нельзя, ведь мы не можем по умолчанию считать, что переводим полные предложения. В наших входных последовательностях символы EOS не нужны, поскольку они уже отформатированы и нам не надо специально отмечать конец каждой исходной последовательности.
Читать дальшеИнтервал:
Закладка:









